| PostgreSQL 统计信息混淆之处(scan,read,fetch,hit)源码解读 原作者:digoal / 德哥 创作时间:2016-10-22 20:31:54+08 |
doudou586 发布于2016-10-23 20:31:54
 评论: 3 评论: 3
 浏览: 10195 浏览: 10195
|
PostgreSQL 统计信息混淆之处(scan,read,fetch,hit)源码解读
2016 Postgres大象会官方报名通道: 点此报名

作者: digoal
日期: 2016-03-18
PostgreSQL 几个统计信息的解释难以理解,所以本文花一些时间从源码的角度来解释一下。 让大家对这几个容易误解的统计值有更好的理解。
比较难理解的几个统计值为:
pg_stat_all_indexes 的
idx_scan idx_tup_read idx_tup_fetch
pg_statio_all_indexes 的
idx_blks_read idx_blks_hit
pg_stat_all_tables 的
seq_scan seq_tup_read idx_scan idx_tup_fetch
pg_statio_all_tables 的
heap_blks_read heap_blks_hit idx_blks_read idx_blks_hit toast_blks_read heap表对应的toast表统计字段 toast_blks_hit tidx_blks_read heap表的索引对应的toast索引统计字段 tidx_blks_hit
首先需要获得以上统计字段的信息来源:
postgres=# \d+ pg_stat_all_indexes
View "pg_catalog.pg_stat_all_indexes"
Column | Type | Modifiers | Storage | Description
---------------+--------+-----------+---------+-------------
relid | oid | | plain |
indexrelid | oid | | plain |
schemaname | name | | plain |
relname | name | | plain |
indexrelname | name | | plain |
idx_scan | bigint | | plain | --pg_stat_get_numscans(i.oid)
idx_tup_read | bigint | | plain | --pg_stat_get_tuples_returned(i.oid)
idx_tup_fetch | bigint | | plain | --pg_stat_get_tuples_fetched(i.oid)
View definition:
SELECT c.oid AS relid,
i.oid AS indexrelid,
n.nspname AS schemaname,
c.relname,
i.relname AS indexrelname,
pg_stat_get_numscans(i.oid) AS idx_scan,
pg_stat_get_tuples_returned(i.oid) AS idx_tup_read,
pg_stat_get_tuples_fetched(i.oid) AS idx_tup_fetch
FROM pg_class c
JOIN pg_index x ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r'::"char", 't'::"char", 'm'::"char"]);
postgres=# \d+ pg_statio_all_indexes
View "pg_catalog.pg_statio_all_indexes"
Column | Type | Modifiers | Storage | Description
---------------+--------+-----------+---------+-------------
relid | oid | | plain |
indexrelid | oid | | plain |
schemaname | name | | plain |
relname | name | | plain |
indexrelname | name | | plain |
idx_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(i.oid)
- pg_stat_get_blocks_hit(i.oid)
idx_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(i.oid)
View definition:
SELECT c.oid AS relid,
i.oid AS indexrelid,
n.nspname AS schemaname,
c.relname,
i.relname AS indexrelname,
pg_stat_get_blocks_fetched(i.oid) - pg_stat_get_blocks_hit(i.oid) AS idx_blks_read,
pg_stat_get_blocks_hit(i.oid) AS idx_blks_hit
FROM pg_class c
JOIN pg_index x ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r'::"char", 't'::"char", 'm'::"char"]);
postgres=# \d+ pg_stat_all_tables
View "pg_catalog.pg_stat_all_tables"
Column | Type | Modifiers | Storage | Description
---------------------+--------------------------+-----------+---------+-------------
relid | oid | | plain |
schemaname | name | | plain |
relname | name | | plain |
seq_scan | bigint | | plain | -- pg_stat_get_numscans(c.oid)
seq_tup_read | bigint | | plain | -- pg_stat_get_tuples_returned(c.oid)
idx_scan | bigint | | plain | -- sum(pg_stat_get_numscans(i.indexrelid))
idx_tup_fetch | bigint | | plain | -- sum(pg_stat_get_tuples_fetched(i.indexrelid))
+ pg_stat_get_tuples_fetched(c.oid)
n_tup_ins | bigint | | plain |
n_tup_upd | bigint | | plain |
n_tup_del | bigint | | plain |
n_tup_hot_upd | bigint | | plain |
n_live_tup | bigint | | plain |
n_dead_tup | bigint | | plain |
n_mod_since_analyze | bigint | | plain |
last_vacuum | timestamp with time zone | | plain |
last_autovacuum | timestamp with time zone | | plain |
last_analyze | timestamp with time zone | | plain |
last_autoanalyze | timestamp with time zone | | plain |
vacuum_count | bigint | | plain |
autovacuum_count | bigint | | plain |
analyze_count | bigint | | plain |
autoanalyze_count | bigint | | plain |
View definition:
SELECT c.oid AS relid,
n.nspname AS schemaname,
c.relname,
pg_stat_get_numscans(c.oid) AS seq_scan,
pg_stat_get_tuples_returned(c.oid) AS seq_tup_read,
sum(pg_stat_get_numscans(i.indexrelid))::bigint AS idx_scan,
sum(pg_stat_get_tuples_fetched(i.indexrelid))::bigint
+ pg_stat_get_tuples_fetched(c.oid) AS idx_tup_fetch,
pg_stat_get_tuples_inserted(c.oid) AS n_tup_ins,
pg_stat_get_tuples_updated(c.oid) AS n_tup_upd,
pg_stat_get_tuples_deleted(c.oid) AS n_tup_del,
pg_stat_get_tuples_hot_updated(c.oid) AS n_tup_hot_upd,
pg_stat_get_live_tuples(c.oid) AS n_live_tup,
pg_stat_get_dead_tuples(c.oid) AS n_dead_tup,
pg_stat_get_mod_since_analyze(c.oid) AS n_mod_since_analyze,
pg_stat_get_last_vacuum_time(c.oid) AS last_vacuum,
pg_stat_get_last_autovacuum_time(c.oid) AS last_autovacuum,
pg_stat_get_last_analyze_time(c.oid) AS last_analyze,
pg_stat_get_last_autoanalyze_time(c.oid) AS last_autoanalyze,
pg_stat_get_vacuum_count(c.oid) AS vacuum_count,
pg_stat_get_autovacuum_count(c.oid) AS autovacuum_count,
pg_stat_get_analyze_count(c.oid) AS analyze_count,
pg_stat_get_autoanalyze_count(c.oid) AS autoanalyze_count
FROM pg_class c
LEFT JOIN pg_index i ON c.oid = i.indrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r'::"char", 't'::"char", 'm'::"char"])
GROUP BY c.oid, n.nspname, c.relname;
postgres=# \d+ pg_statio_all_tables
View "pg_catalog.pg_statio_all_tables"
Column | Type | Modifiers | Storage | Description
-----------------+--------+-----------+---------+-------------
relid | oid | | plain |
schemaname | name | | plain |
relname | name | | plain |
heap_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(c.oid)
- pg_stat_get_blocks_hit(c.oid)
heap_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(c.oid)
idx_blks_read | bigint | | plain | -- sum(pg_stat_get_blocks_fetched(i.indexrelid)
- pg_stat_get_blocks_hit(i.indexrelid))
idx_blks_hit | bigint | | plain | -- sum(pg_stat_get_blocks_hit(i.indexrelid))
toast_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(t.oid)
- pg_stat_get_blocks_hit(t.oid)
toast_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(t.oid)
tidx_blks_read | bigint | | plain | -- sum(pg_stat_get_blocks_fetched(x.indexrelid) - pg_stat_get_blocks_hit(x.indexrelid))
tidx_blks_hit | bigint | | plain | -- sum(pg_stat_get_blocks_hit(x.indexrelid))
View definition:
SELECT c.oid AS relid,
n.nspname AS schemaname,
c.relname,
pg_stat_get_blocks_fetched(c.oid) - pg_stat_get_blocks_hit(c.oid) AS heap_blks_read,
pg_stat_get_blocks_hit(c.oid) AS heap_blks_hit,
sum(pg_stat_get_blocks_fetched(i.indexrelid) - pg_stat_get_blocks_hit(i.indexrelid))::bigint AS idx_blks_read,
sum(pg_stat_get_blocks_hit(i.indexrelid))::bigint AS idx_blks_hit,
pg_stat_get_blocks_fetched(t.oid) - pg_stat_get_blocks_hit(t.oid) AS toast_blks_read,
pg_stat_get_blocks_hit(t.oid) AS toast_blks_hit,
sum(pg_stat_get_blocks_fetched(x.indexrelid) - pg_stat_get_blocks_hit(x.indexrelid))::bigint AS tidx_blks_read,
sum(pg_stat_get_blocks_hit(x.indexrelid))::bigint AS tidx_blks_hit
FROM pg_class c
LEFT JOIN pg_index i ON c.oid = i.indrelid
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
LEFT JOIN pg_index x ON t.oid = x.indrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r'::"char", 't'::"char", 'm'::"char"])
GROUP BY c.oid, n.nspname, c.relname, t.oid, x.indrelid;
以上几个统计字段的统计信息来自如下函数:
idx_scan | bigint | | plain | -- pg_stat_get_numscans(i.oid)
idx_tup_read | bigint | | plain | -- pg_stat_get_tuples_returned(i.oid)
idx_tup_fetch | bigint | | plain | -- pg_stat_get_tuples_fetched(i.oid)
idx_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(i.oid)
- pg_stat_get_blocks_hit(i.oid)
idx_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(i.oid)
seq_scan | bigint | | plain | -- pg_stat_get_numscans(c.oid)
seq_tup_read | bigint | | plain | -- pg_stat_get_tuples_returned(c.oid)
idx_scan | bigint | | plain | -- sum(pg_stat_get_numscans(i.indexrelid))
idx_tup_fetch | bigint | | plain | -- sum(pg_stat_get_tuples_fetched(i.indexrelid))
+ pg_stat_get_tuples_fetched(c.oid)
heap_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(c.oid)
- pg_stat_get_blocks_hit(c.oid)
heap_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(c.oid)
idx_blks_read | bigint | | plain | -- sum(pg_stat_get_blocks_fetched(i.indexrelid)
- pg_stat_get_blocks_hit(i.indexrelid))
idx_blks_hit | bigint | | plain | -- sum(pg_stat_get_blocks_hit(i.indexrelid))
toast_blks_read | bigint | | plain | -- pg_stat_get_blocks_fetched(t.oid)
- pg_stat_get_blocks_hit(t.oid)
toast_blks_hit | bigint | | plain | -- pg_stat_get_blocks_hit(t.oid)
tidx_blks_read | bigint | | plain | -- sum(pg_stat_get_blocks_fetched(x.indexrelid)
- pg_stat_get_blocks_hit(x.indexrelid))
tidx_blks_hit | bigint | | plain | -- sum(pg_stat_get_blocks_hit(x.indexrelid))
这些SQL函数对应的C函数如下:
postgres=# \df+ pg_stat_get_numscans | Source code | Description +----------------------+-------------------------------------------------- | pg_stat_get_numscans | statistics: number of scans done for table/index postgres=# \df+ pg_stat_get_tuples_returned | Source code | Description +-----------------------------+---------------------------------------------- | pg_stat_get_tuples_returned | statistics: number of tuples read by seqscan postgres=# \df+ pg_stat_get_tuples_fetched | Source code | Description +----------------------------+------------------------------------------------- | pg_stat_get_tuples_fetched | statistics: number of tuples fetched by idxscan postgres=# \df+ pg_stat_get_blocks_fetched | Source code | Description +----------------------------+-------------------------------------- | pg_stat_get_blocks_fetched | statistics: number of blocks fetched postgres=# \df+ pg_stat_get_blocks_hit | Source code | Description +------------------------+--------------------------------------------- | pg_stat_get_blocks_hit | statistics: number of blocks found in cache
以上5个C函数的源码分析
pg_stat_get_numscans result = (int64) (tabentry->numscans); pg_stat_get_tuples_returned result = (int64) (tabentry->tuples_returned); pg_stat_get_tuples_fetched result = (int64) (tabentry->tuples_fetched); pg_stat_get_blocks_fetched result = (int64) (tabentry->blocks_fetched); pg_stat_get_blocks_hit result = (int64) (tabentry->blocks_hit);
他们都是返回以下数据结构中的某项计数器的值:
/* ----------
* PgStat_StatTabEntry The collector's data per table (or index)
* ----------
*/
typedef struct PgStat_StatTabEntry
{
Oid tableid;
PgStat_Counter numscans;
PgStat_Counter tuples_returned;
PgStat_Counter tuples_fetched;
PgStat_Counter tuples_inserted;
PgStat_Counter tuples_updated;
PgStat_Counter tuples_deleted;
PgStat_Counter tuples_hot_updated;
PgStat_Counter n_live_tuples;
PgStat_Counter n_dead_tuples;
PgStat_Counter changes_since_analyze;
PgStat_Counter blocks_fetched;
PgStat_Counter blocks_hit;
TimestampTz vacuum_timestamp; /* user initiated vacuum */
PgStat_Counter vacuum_count;
TimestampTz autovac_vacuum_timestamp; /* autovacuum initiated */
PgStat_Counter autovac_vacuum_count;
TimestampTz analyze_timestamp; /* user initiated */
PgStat_Counter analyze_count;
TimestampTz autovac_analyze_timestamp; /* autovacuum initiated */
PgStat_Counter autovac_analyze_count;
} PgStat_StatTabEntry;
这些值是由pgstats进程来进行统计的
PgstatCollectorMain(int argc, char *argv[])
{
...
for (;;)
{
/* Clear any already-pending wakeups */
ResetLatch(&pgStatLatch);
...
/*
* O.K. - we accept this message. Process it.
*/
switch (msg.msg_hdr.m_type)
{
...
case PGSTAT_MTYPE_TABSTAT:
pgstat_recv_tabstat((PgStat_MsgTabstat *) &msg, len);
break;
...
/* ----------
* pgstat_recv_tabstat() -
*
* Count what the backend has done.
* ----------
*/
static void
pgstat_recv_tabstat(PgStat_MsgTabstat *msg, int len)
{
...
tabentry->numscans += tabmsg->t_counts.t_numscans;
tabentry->tuples_returned += tabmsg->t_counts.t_tuples_returned;
tabentry->tuples_fetched += tabmsg->t_counts.t_tuples_fetched;
tabentry->tuples_inserted += tabmsg->t_counts.t_tuples_inserted;
tabentry->tuples_updated += tabmsg->t_counts.t_tuples_updated;
tabentry->tuples_deleted += tabmsg->t_counts.t_tuples_deleted;
tabentry->tuples_hot_updated += tabmsg->t_counts.t_tuples_hot_updated;
tabentry->n_live_tuples += tabmsg->t_counts.t_delta_live_tuples;
tabentry->n_dead_tuples += tabmsg->t_counts.t_delta_dead_tuples;
tabentry->changes_since_analyze += tabmsg->t_counts.t_changed_tuples;
tabentry->blocks_fetched += tabmsg->t_counts.t_blocks_fetched;
tabentry->blocks_hit += tabmsg->t_counts.t_blocks_hit;
...
tabmsg->t_counts.? 则是通过如下macro进行改写的:
/* nontransactional event counts are simple enough to inline */
#define pgstat_count_heap_scan(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_numscans++;
} while (0)
#define pgstat_count_heap_getnext(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_tuples_returned++;
} while (0)
#define pgstat_count_heap_fetch(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_tuples_fetched++;
} while (0)
#define pgstat_count_index_scan(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_numscans++;
} while (0)
#define pgstat_count_index_tuples(rel, n)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_tuples_returned += (n);
} while (0)
#define pgstat_count_buffer_read(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_blocks_fetched++;
} while (0)
#define pgstat_count_buffer_hit(rel)
do {
if ((rel)->pgstat_info != NULL)
(rel)->pgstat_info->t_counts.t_blocks_hit++;
} while (0)
取出每个macro对应的调用以及解释如下:
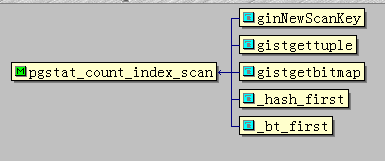
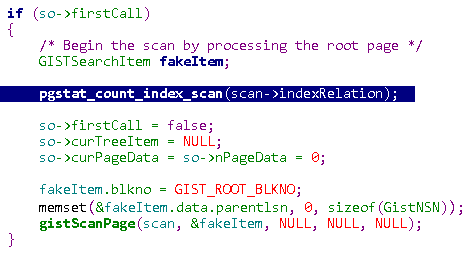
pgstat_count_index_scan(idx_oid)
统计指定索引的扫描次数,和扫描多少条记录无关,和node有个,一般看执行计划中,同一个索引如果在NODE中出现一次,那么就算扫描一次。
pgstat_count_index_tuples(rel, n)
统计从指定索引获取tid的条数

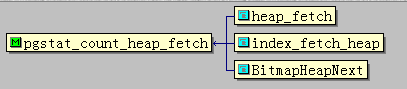
pgstat_count_heap_fetch
统计从使用指定索引的tid获取HEAP tuple的条数
pgstat_count_buffer_read
统计所有的buffer read次数, 包括在postgresql shared buffers中命中的,或者未在postgresql shared buffers中命中的。

pgstat_count_buffer_hit(rel)
统计在shared buffers中命中的buffer read次数。


pgstat_count_heap_scan(rel)
统计指定表的,全表扫描的次数,和返回的记录数无关,只和执行计划中的node相关,如果在plan中某个表只有一个seq scan的次数,则这条SQL执行一次时算一次。

pgstat_count_heap_getnext(rel)
指从全表扫描节点中扫描的记录数
梳理一下最初的统计字段和这些macro的对应关系:
pg_stat_all_indexes 的
idx_scan 对应 pgstat_count_index_scan(idx_oid) 产生的计数的累加
idx_tup_read 对应 pgstat_count_index_tuples(idx_oid, n) 产生的计数的累加
idx_tup_fetch 对应 pgstat_count_heap_fetch(idx_oid) 产生的计数的累加
pg_statio_all_indexes 的
idx_blks_read 对应 pgstat_count_buffer_read(idx_oid) 产生的计数的累加
idx_blks_hit 对应 pgstat_count_buffer_hit(idx_oid) 产生的计数的累加
pg_stat_all_tables 的
seq_scan 对应 pgstat_count_heap_scan(tbl_oid) 产生的计数的累加
seq_tup_read 对应 pgstat_count_heap_getnext(tbl_oid) 产生的计数的累加
idx_scan 对应 sum( 索引 pgstat_count_index_scan(tbl_oid) ) 产生的计数的累加
idx_tup_fetch 对应 sum( 索引 pgstat_count_index_tuples(idx_oid, n) ) +
pgstat_count_heap_fetch(tbl_oid) 产生的计数的累加
pg_statio_all_tables 的
heap_blks_read 对应 pgstat_count_buffer_read(tbl_oid) -
pgstat_count_buffer_hit(tbl_oid) 产生的计数的累加
heap_blks_hit 对应 pgstat_count_buffer_hit(tbl_oid) 产生的计数的累加
idx_blks_read 对应 sum( 索引 pgstat_count_buffer_read(idx_oid) -
pgstat_count_buffer_hit(idx_oid) ) 产生的计数的累加
idx_blks_hit 对应 sum( pgstat_count_buffer_hit(idx_oid) ) 产生的计数的累加
toast_blks_read 对应 pgstat_count_buffer_read(toast_oid) -
pgstat_count_buffer_hit(toast_oid) 产生的计数的累加
toast_blks_hit 对应 pgstat_count_buffer_hit(toast_oid) 产生的计数的累加
tidx_blks_read 对应 sum( 索引 pgstat_count_buffer_read(toast_idx_oid) -
pgstat_count_buffer_hit(toast_idx_oid) ) 产生的计数的累加
tidx_blks_hit 对应 sum( pgstat_count_buffer_hit(toast_idx_oid) ) 产生的计数的累加
小结:
pg_stat_all_indexes 的
idx_scan 索引被扫描了多少次,和扫描多少条记录无关,和node有关,一般看执行计划, 同一个索引如果在NODE中出现一次,那么这条SQL执行时这个索引就算扫描一次。 idx_tup_read 从指定索引获取tid的条(tid是指向heap表数据块上某条记录的一个数据结构, 如(1,10)表示1号数据块的第10条记录) idx_tup_fetch 从索引的tid获取HEAP tuple的记数(每扫一条tuple计1)
pg_statio_all_indexes 的
idx_blks_read 该索引的buffer read记数(每读一个block记1次), 包括在postgresql shared buffers中命中的, 或者未在postgresql shared buffers中命中的。 idx_blks_hit 在postgresql shared buffers中命中的buffer read记数。
pg_stat_all_tables 的
seq_scan 全表扫描的次数 seq_tup_read 使用全表扫描扫过的tuple条数 idx_scan 该表的所有索引扫描次数总和 idx_tup_fetch 该表的所有 从索引的tid获取HEAP tuple的条数
pg_statio_all_tables 的
heap_blks_read 该表的buffer read记数, 包括在postgresql shared buffers中命中的, 或者未在postgresql shared buffers中命中的。 heap_blks_hit 在postgresql shared buffers中命中的buffer read记数。 idx_blks_read 该表所有索引 所有buffer read记数(含命中和未命中) idx_blks_hit 该表所有索引 在shared buffer命中的buffer read记数 toast_blks_read heap表对应的toast表统计字段 toast_blks_hit tidx_blks_read heap表的索引对应的toast索引统计字段 tidx_blks_hit
希望能帮助到大家,还不理解就要打屁屁了。
2016 Postgres大象会官方报名通道:http://www.huodongxing.com/event/8352217821400
扫描报名

请在登录后发表评论,否则无法保存。
