| 基于PostgreSQL的内存计算引擎LeMCS设计开发经验之谈 原作者:联想数据库团队 创作时间:2017-04-02 00:30:34+08 |
doudou586 发布于2017-04-02 00:30:34
 评论: 1 评论: 1
 浏览: 12397 浏览: 12397
|
基于PostgreSQL的内存计算引擎LeMCS设计开发经验之谈
联想数据库团队(卢俊峰、刘虎城、王凯)/ 2017-4-1
欢迎大家踊跃投稿,投稿信箱:press@postgres.cn
1、背景介绍
身处大数据时代,在数据库领域,我们要分析处理的数据越来越多,我们分析处理数据的速度也要越来越快,但是传统数据库基于磁盘的计算模型,已经难以满足我们的需求。幸运的是随着硬件的发展,内存设备的性能在不断提高,而价格却在不断下降。内存计算技术将带着我们“飞”起来!
内存计算(In-Memory Computing),实质上是CPU直接从内存而非硬盘上读取数据,并对数据进行计算、分析。在数据库上引入内存计算技术,意味着去除磁盘IO的消耗,利用内存随机访问的特性可以制定更高效的算法等等。这都极大的提高数据的处理速度。
目前很多商业数据库已经拥有了内存计算功能,如SAP HANA、DB2 BLU、Oracle 12C、SQL Server 2014。但是商业数据库的价格毕竟不菲,在开源产品飞速发展的今天,利用开源的内存计算产品是一个好主意。
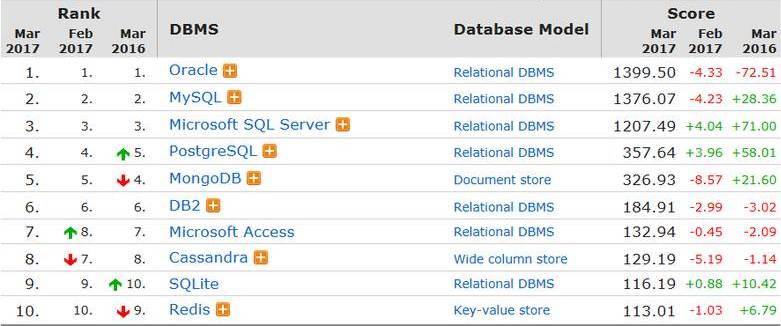
图1 数据库产品使用排名
从图1我们可以看到,目前开源的数据库使用比较多的是MySQL、Redis、PostgreSQL等等。Redis、MemCached是KV类型的内存数据库,不支持关系模型,仅作为关系型数据库的缓存。MySQL支持In-Memory引擎,但是不支持数据的持久化,不支持列存储。基于这种情况,我们打算开发一套基于开源关系型数据库之上的内存计算引擎,实现支持内存计算,数据持久化,并行计算等特性。
2、为什么选择PostgreSQL
虽然决定自开发,但是站在巨人的肩膀上是一个好主意!我们决定基于PostgreSQL开发一个内存计算的引擎,具体理由如下:
1、PostgreSQL的许可证非常开放(BSD协议),简单来说,你可以忘记许可证的问题。
2、PostgreSQL提供完善的外部表(FDW:Foreign Data Wrapper)扩展开发机制,可以很容易的开发满足自身需求的插件。
3、PostgreSQL的自身稳定性很高,基于PostgreSQL开发产品,不用担心稳定性的问题。
4、在开源社区上有很多PostgreSQL的扩展插件,可以借鉴。
5、可以随着PostgreSQL的社区版本进行迭代。
6、由于PostgreSQL的学院派风格。PostgreSQL的代码质量很高,便于阅读学习。
3、内存计算引擎的设计思路
数据需要存储在内存上,由于PostgreSQL提供了外部表(FDW)概念,可以通过API来对数据进行管理,普通思维是外部表对应的是远程数据库或者其他数据来源,但是我们提出一个概念是将这个FDW对应成内存,这样通过开发扩展插件来实现,不影响PostgreSQL升级带来的迭代问题,也不需要修改内核源码。数据常驻内存,只是简单的解决了数据库IO的问题,只能节省IO的时间,并不能带来计算上质的飞跃,我们测试过,只是将数据Cache到内存中,性能只有1-2倍的提升。如果说设计好存储,利用列式存储将数据分条带分块,通过多线程对数据进行计算,每个线程互不干扰的扫描并计算所分配的条带,这样对内存计算来说能够达到质的飞跃,这也是所有常见数据库所追求的。
3.1 外部表(FDW)
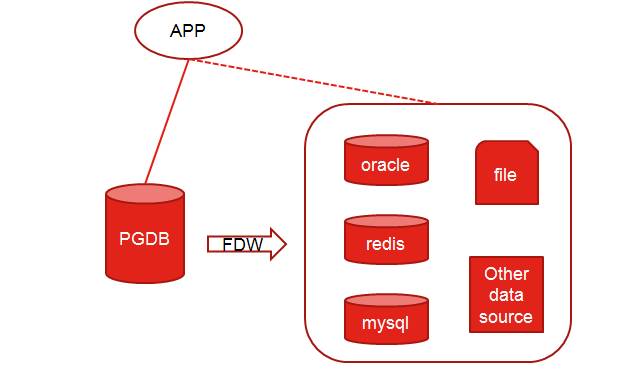
图2 外部表透明访问
外部表:在PostgreSQL内部提供一种表类型,能够提供用户访问外部源数据的一种方式,这是PostgreSQL作为学院派设计比较优美的地方,努力打造成世界的中心,提供给开发人员遐想的空间。
3.2 列式存储
如图3所示,将一张表进行横向切割产生了stripe,stripe是由多个块数组构成,blockArray是多列的block数据,block是由单列的多个行数据组成,在对数据进行索引时,只需要通过stripeNum、blockArrayNum、blockRowNum能索引到行,这样组成了RowID。
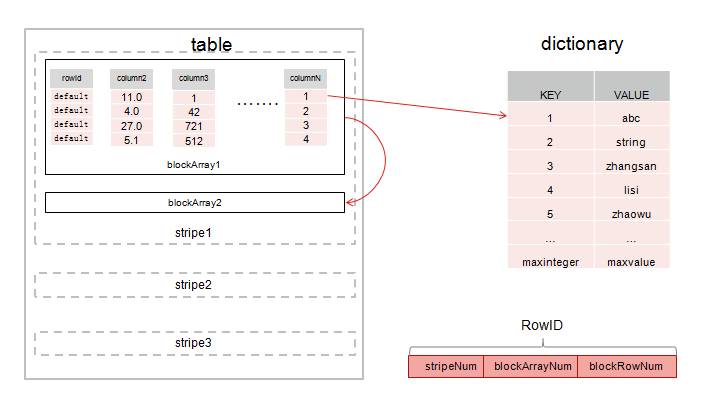
图3 内存列式存储
注:blockArrayNum:DEFAULT is 15
blockRowNum:DEFAULT is 10000
RowID = stripeNum + blockNum + blockRowNum(“+”号是拼接)
对字符串存储使用了Hash字典表,字符串存储过程中会在Hash表中对应一个8字节的MapCode,在进行字符串比较过滤或者对字符串进行Join计算时,只需要对MapCode值进行比较或者对MapCode值进行排序而不是对字符串进行比较或者排序,这样不仅带来了效率上的提升,而且还节省了空间。在存储中采用分条带分块的概念,这样的存储模型为多线程计算做好了完美铺垫。
3.3 内存计算
在对内存计算分析之前需要提出一个概念,对数据列单个的取出或者两个列的取出都称之为序列(Time Series),序列是自定义的一种类型,我们打造是所有类型皆序列,如下面的例子:
SQL:select sum(c1 + 1) from table where c2>10; àselect cs_sum(cs_filter(c2>10,c1) + 1) from table_get();
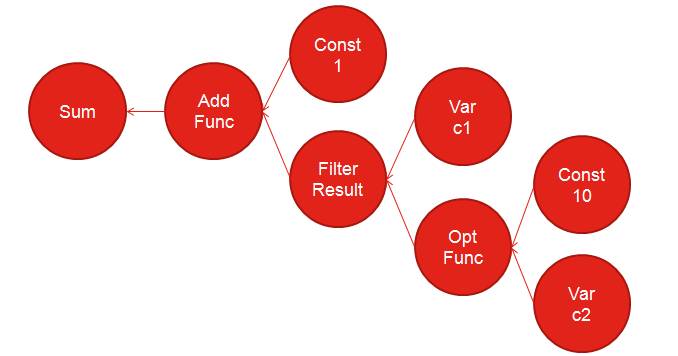
图4 内存计算流程
对图4的分析如下:
我们是将整个SQL语句翻译成UDF函数来进行执行,通过这样的翻译会生成如图4所示的一个树形结构,当中的每个节点都是对应的一个Iterator,当键入带有UDF的SQL语句后,准备工作先生成Iterator的结构树,在对SUM值输出时才开始进行计算。
C2>10是一个公式,在迭代器中进行的是C2与常数10的比较,满足条件的会返回序列(Time Series),在过滤过程中返回的序列其实是一个Bitmap,通过这个Bitmap可以知道C1这个序列哪些记录被选中,再对选中返回的序列进行Add操作,最终返回SUM结果。
3.4 并行计算
首先多线程是通过参数配置启动多少个线程来完成这次计算,配置选项在postgres.conf文件,默认情况是单线程计算,如果配置了会根据配置数量来进行启动nthreads个线程。
之前也提到过由于使用了分条带分块,因此并行计算不是问题了,以下是拆分条带的间隔
Interval = (stripe_last – stripe_first + nthreads)/nthreads
并行中按照这个间隔来对条带进行扫描并计算,还是以SUM为例。
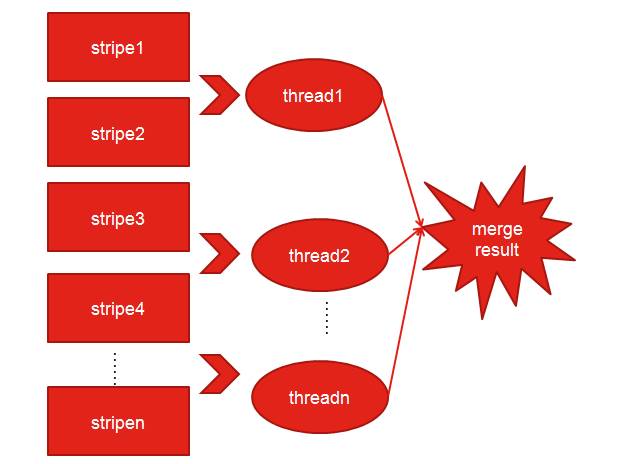
图5 并行计算分析
如图5所示,每个线程都只扫描所分配的条带号并进行计算,最终将各个线程的计算结果merge,最终得到计算结果。
4、内存计算引擎的优化
4.1 Join
由于使用的是列式存储,因此与原生PostgreSQL行式计算引擎有很大的不同,但是实现的原理以及算法都是模仿PostgreSQL内部实现,支持三种Join方式:Nestloop Join、Sort Merge Join、Hash Join。
4.1.1 Nestloop
实现方式:
for each row in t1
{
for each row in t2
{
if row satisfies join conditions
{
…
}
}
}
参见伪代码,Nestloop实现的方式比较简单,通过for循环进行嵌套实现,所以复杂度是O(N*M)。
分析:比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,对于被连接的数据子集较小的情况,Nestloop连接是个较好的选择。
4.1.2 Sort Merge Join
实现方式:

参考PostgreSQL中提供的伪代码分析,首先对两个表做Join的两列进行排序,由于我们是列存储,这个操作非常容易。接下来遍历两个表,如果合适放入结果集,依次处理直到将两表的数据取完。
分析:merge join需要在排序上花一部分开销,排序后运算成本接近全表扫描两个表的成本之和。在已经排序的条件下,这种join方式具有巨大优势。
4.1.3 hash join
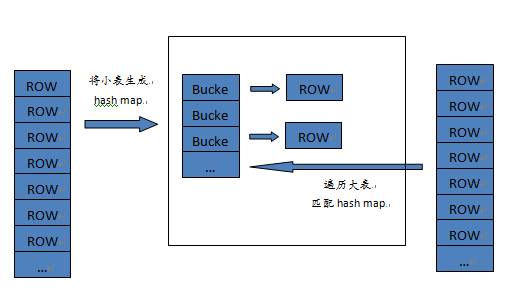
图6 hash join实现分析
实现方式:对于要做join的两张表,首先将小表转换成hash map,然后扫描大表的每一行数据,计算行数据的hash值,映射hash map,可以得到匹配的行。
分析:当表比较大的时候,采用hash join是比较有优势的。运算成本接近全表扫描两个表的成本之和。当然这会浪费一定的内存空间,不过既然我们是内存计算引擎,内存空间显然不是问题。由于采用hash字典技术,字符串数据在表中实际上存储的是字符串对应的hash值,这样在做hash join的时候,我们选择字符串的列去做join的话,我们将更快的得到结果。
4.2 持久化
既然是内存引擎会出现断电数据丢失的问题,因此我们在设计之初考虑到了这个问题,添加一个可配置的功能持久化,只要配置该选项是把持久化switch打开,在创建内存外部表时,会同时创建PostgreSQL原生表,该表的插入操作是会进行Wal日志记录以及落盘,在对内存进行增删改操作时,会先将sql拷贝一份,并将在PostgreSQL原生表中先执行一遍,然后再对内存外部表操作,这样保证了数据的持久化了,数据都可以从原生表以及Wal日志中获取。
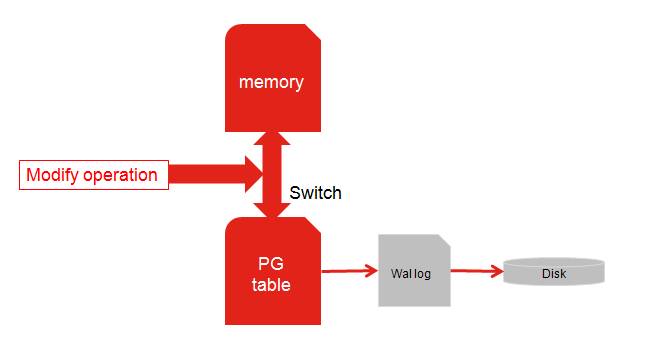
图7 数据持久化过程
5、测试对比
测试环境:
Server Specs: Physical Server, 24 Cores, 128G RAM Test Products: LeMCS; PostgreSQL ; DB2 Data Volume: 2 tables , 30GB, 800w records & 1300w records
测试结果:
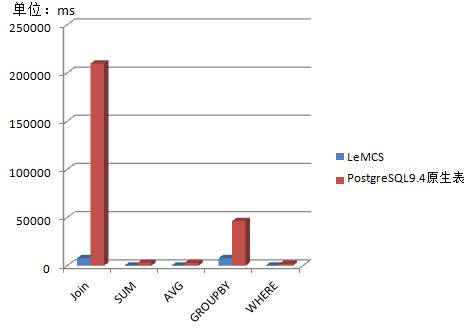
图8 测试对比
如图8所示,LeMCS在对比PostgreSQL原生表测试中,计算速度都能够快到5x-30x。
附测试sql:
select count(t1.sls_ordr_num) from OVP.rdl_sls_ordr_sts_1 as t1, OVP.rdl_sls_ordr_sts_2 as t2 where t1.sls_ordr_num=t2.sls_ordr_num and t1.ordr_ent_dt>='2016-08-30 00:00:00' and t1.ordr_ent_dt<='2016-12-27 23:59:59'; select sum(ct_ordr_ent_to_dlvry_dt_bsns) from OVP.rdl_sls_ordr_sts_2; select avg(ct_ordr_ent_to_dlvry_dt_bsns) from OVP.rdl_sls_ordr_sts_2; select sls_ordr_num,sum(ct_ordr_ent_to_dlvry_dt_bsns) from OVP.rdl_sls_ordr_sts_2 group by sls_ordr_num; select count(sls_ordr_num) from ovp.rdl_sls_ordr_sts_1 where ordr_ent_dt>='2016-08-30 00:00:00' and ordr_ent_dt<='2016-12-27 23:59:59'; select sum(ct_ordrcpt_to_dlvry_dt_bsns) from ovp.rdl_sls_ordr_sts_1 where ordr_ent_dt>='2016-08-30 00:00:00' and ordr_ent_dt<='2016-12-27 23:59:59';
注:LeMCS均使用的是UDF函数替换进行测试
6、后续开发
通过运用以上的技术手段实现的内存计算引擎,以插件的形式嵌入PostgreSQL数据库中,目前通过测试使用正常,达到我们之前制定的目标。当然很多问题需要后续开发进行解决。目前所有对内存中表的访问都是通过自定义函数(UDF)来实现的,为了便于使用,我们正在开发对于标准SQL的支持。后续我们联想会将这款工具发布出来,与有需要的同学分享,大家一起使用并持续开发,把这款工具打造的更加强大,帮助更多的人。

请在登录后发表评论,否则无法保存。
