| 【转】:优化Postgres-x2 GTM 原作者:scarbrofair 创作时间:2015-12-22 12:35:35+08 |
doudou586 发布于2015-12-23 12:35:35
 评论: 5 评论: 5
 浏览: 16848 浏览: 16848
|
Postgres-x2是一个基于pgsql、面向OTLP的分布式数据库,采用了shared-nothing的架构,目标是针对OLTP\OLAP应用能做到可扩展的系统。源码在github上:https://github.com/postgres-x2/postgres-x2 。
最近在针对 Postgres-x2做压力测试。测试是在一台DEll R510上进行的,该服务器上有4颗X5650和64G内存,另外是两块老式的SSD,型号不详,最大写入速度100M左右。
测试的版本是直接从github上拉下来的,直接编译安装。在这台服务器上安装了GTM、coordinator、datanode各一个,GTM和coordinator的数据目录都在一个SSD上,datanode的数据目录在另外的一个SSD盘上。以最大化利用磁盘资源。之所以在一台服务器上进行测试,主要是想模拟一个网络带宽不受限的环境,也是为了简化问题。
coordinator的几个重要配置如下:
max_connections = 1024 shared_buffers = 2048MB # shared_buffer没有必要设置过大 checkpoint_segments = 64 checkpoint_timeout = 20min # 让checkpoint间隔尽量大 logging_collector = on autovacuum = off min_pool_size = 100 # 连接池初始大小 max_pool_size = 1024
datanode的配置如下:
max_connections = 1024 shared_buffers = 20480MB vacuum_cost_delay = 10 vacuum_cost_limit = 10000 checkpoint_segments = 256 checkpoint_timeout = 10min logging_collector = on autovacuum_vacuum_cost_delay = 5ms
测试的主要方法是使用pgbench生成scale为1000的数据集合,大概有16G,主要的测试方法就是先执行checkpoint,将数据块刷回磁盘,以减小checkpoint的影响,然后执行下面的命令:
Bash代码:
pgbench -c N -j N -T 60
N是连接数,这个操作会模拟并发的N个客户连续访问数据库60秒,每个客户需要在60秒内不停执行一个有着5条SQL的事务:
Sql代码:
BEGIN; UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2; UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2; SELECT abalance FROM pgbench_accounts WHERE aid = $1; INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES ($1, $2, $3, $4, CURRENT_TIMESTAMP); UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2; END;
测试的时候,N从32增大到768,取TPS。结果如下:
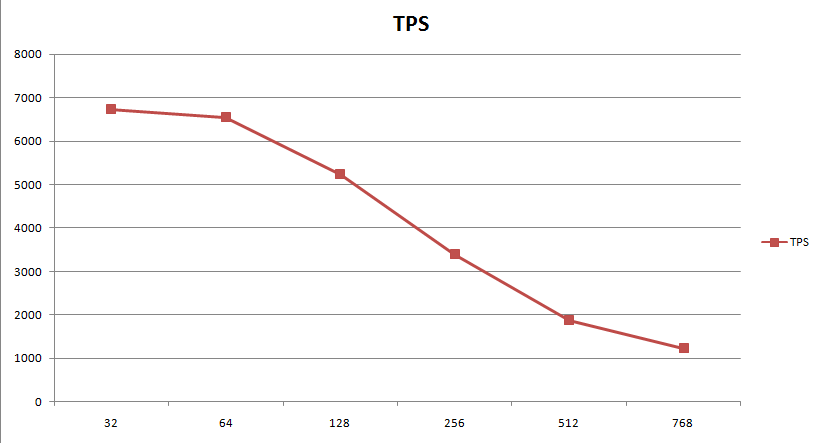
随着连接数的增加,TPS几乎是线性降低。datanode数据目录所在的磁盘使用率也基本上从最高的60%降低到了20%,而整体的CPU使用率不怎么飙升,只是GTM看起来还比较忙。
感觉GTM比较有问题,于是祭出了gprof来做性能分析,结果啥都没有,google一下,发现是gtm屏蔽了SIGPROF信号,打上我的这个patch就OK了:
diff --git a/src/gtm/libpq/pqsignal.c b/src/gtm/libpq/pqsignal.c
index e3f482c..594540f 100644
--- a/src/gtm/libpq/pqsignal.c
+++ b/src/gtm/libpq/pqsignal.c
@@ -119,6 +119,10 @@ pqinitmask(void)
sigdelset(&BlockSig, SIGCONT);
sigdelset(&AuthBlockSig, SIGCONT);
#endif
+#ifdef SIGPROF
+ sigdelset(&BlockSig, SIGPROF);
+ sigdelset(&AuthBlockSig, SIGPROF);
+#endif
记得使用--enable-profiling选项来重新生成makefile 或是直接编辑makefile加上 -pg选项,然后重新编译一下gtm。拿pgbench运行一段时间之后,停掉gtm,在gtm的目录下会有一个gmon.out,执行:
Bash代码:
gprof -b /usr/local/pgx2/bin/gtm gmon.out > gtm.out
Gmon代码:
Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 31.41 49.90 49.90 8256962 0.01 0.01 GTM_GXIDToHandle 15.00 73.72 23.82 3791614 0.01 0.01 GTM_GetTransactionSnapshot 6.33 83.77 10.05 4305476 0.00 0.00 gtm_list_delete 5.07 91.83 8.06 790 10.20 181.29 GTM_ThreadMain 3.09 96.75 4.92 25006706 0.00 0.00 AllocSetAlloc 2.06 100.02 3.27 752039341 0.00 0.00 GlobalTransactionIdPrecedes 1.78 102.85 2.83 30641196 0.00 0.00 elog_start 1.66 105.49 2.64 11157165 0.00 0.00 pq_recvbuf 1.62 108.07 2.58 13648719 0.00 0.00 internal_flush
在花了半天看了这两个耗时的函数,大概有点眉目:
- 当coordinator上启动一个事务时,回去gtm申请一个一个事务id (XID) 和存放事务相关信息的GTM_TransactionInfo数据结构,并把这个数据结构的指针放入一个全局的链表GTMTransactions.gt_open_transactions中,gtm将事务ID返回给coordinator
- 事务执行时,会将XID发给gtm去获取快照。gtm会首先调用GTM_GXIDToHandle函数去获得对应的GTM_TransactionInfo数据结构的指针,GTM_GXIDToHandle函数会遍历全局链表GTMTransactions.gt_open_transactions来获取。然后将该GTM_TransactionInfo数据结构的指针传给GTM_GetTransactionSnapshot函数来获得快照:遍历GTMTransactions.gt_open_transactions中的每个元素,获取全局最小的xmin,和活跃的事务ID(小于最近提交事务的最大ID),放入快照并返回给coordinator。
- 事务结束时,coordinator将XID返回给gtm,gtm根据XID查找对应的GTM_TransactionInfo数据结构,将其回收,并删除GTMTransactions.gt_open_transactions中的对应item。
简单看来,这两个耗时的函数都是O(N)级别的复杂度,N 是GTMTransactions.gt_open_transactions的长度,也就是当前正在进行的事务数。因此,随着连接数的增加,coordinator和datanode内部锁竞争的加剧,会导致事务逐渐的积压起来,让GTMTransactions.gt_open_transactions长度变得越来越长,因此堵住了很多获取事务快照的事务。最终就是刚才描述的情形:事务等待GTM,磁盘使用率急剧降低。
所以,从直觉出发,其实可以直接用开放式hash表来优化GTM_GXIDToHandle函数,key是事务ID,value是对应的GTM_TransactionInfo的指针,将这个的函数的操作复杂度降低到O(1)。但是,发现效果并不好:因为GTM_GetTransactionSnapshot函数依然还是要去遍历所有的当前事务获取最小事务xmin和快照。
在经过一个礼拜的调整之后,直接采用教科书的方法:使用一个AVL树来存储GTM_TransactionInfo的指针,比较大小的方法就是对比其中的GXID;另外一个使用AVL树来存最小的xmin。简单来说就是分别以xmin和事务ID为主键建立两个类似BTree的索引,以满足查找需求。最终去掉了GTMTransactions.gt_open_transactions,将这两个耗时的函数的复杂度降低到了O(log(N)),N是当前系统内的事务。
采用前面的测试方法,来获取TPS。和前面的对比图如下:
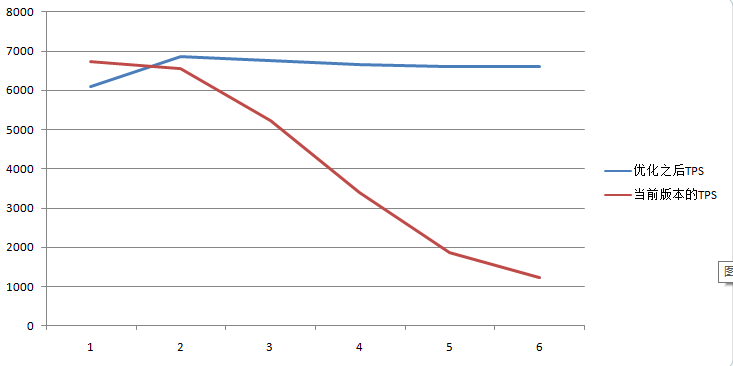
可以看到优化之后的GTM响应时间基本维持在O(log(N)),从而使得TPS在连接数增大时,TPS没有像当前版本下降得这么剧烈(678个连接时,TPS是当前版本的几乎5倍),datanode的数据目录所在磁盘利用利用率机会基本维持在65%~60%之间。这样看来,基本上能改善GTM的扩展能力。
当然,这个优化并非是完美的,因为在执行简单事务并且连接数不多的情况下,TPS和原有的版本几乎相同,但是,一旦事务变得复杂,在GTM中停留的时间增大,或是连接数增大后同时执行的事务数量多了之后,优化之后的GTM相对现有的GTM会稳定很多。
最后,为了验证工作,选了三台相同配置的R510,配置和前面所述相同。一台上装GTM,其他两台上配置了coordinator和datanode各一个(配置也和前面相同)。
生成了scale为1000的数据,32G,使用前面的测试方法,但是分别执行在一张大表上的简单主键查询:
SQL代码:
\\setrandom aid 1 :1000 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
和基于主键的更新
SQL代码:
\\setrandom aid 1 10000000 \\setrandom delta -5000 5000 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
在两台coordinator同时上执行。
最终, 简单select操作的总QPS最大值是45000(每个coordinator上的QPS是22500),简单update操作的总 TPS最大值是 35000(每个coordinator上最大的QPS是17500)。碰巧的是获得最大值时,每台coordinator上执行pgbench的连接数都是64。而随着连接数增大到一定程度,优化之后的GTM会比当前的GTM 结果高50%以上。
从测试看来,在64个连接数的情况,增大一个服务器(部署上datanode和coordinator),可以增加17500的TPS,网络流量增加20MB/s。因此如果真的想达到10W的TPS,预计需要10台左右这样的服务器用来部署coordinator和datanode。
但是我们需要解决两个问题:一方面,我们需要子网的交换机来提供200MB/s以上的带宽连接各个服务器,这是首先必须解决的问题,当然也是比较容易解决的问题;另外一方面,对于GTM来说,我们必须采用类似的优化来增大GTM的可扩展能力,因为如果每个coordinator上使用64个连接,那么对于10台的集群来说,系统内操作的连接数就是640了,如果还采用目前的GTM,TPS QPS会急剧下降,这是根本没法做到的。
请在登录后发表评论,否则无法保存。
