| PostgreSQL 9.6 引领开源数据库攻克多核并行计算难题(第一部分) 原作者:digoal / 德哥 创作时间:2016-10-04 10:02:40+08 |
doudou586 发布于2016-10-04 10:02:40
 评论: 3 评论: 3
 浏览: 8764 浏览: 8764
|

背景
经过多年的酝酿(从支持work process到支持动态fork共享内存,再到内核层面支持并行计算),PostgreSQL的多核并行计算功能终于在2016年发布的9.6版本中正式上线,为PG的scale up能力再次拔高一个台阶,标志着开源数据库已经攻克了并行计算的难题。相信有很多小伙伴已经开始测试了。在32物理核的机器上进行了测试,重计算的场景,性能程线性提升。目前并行计算支持全表扫描,JOIN,聚合。
一、快速安装PostgreSQL 9.6
为了让大伙能够快速用上9.6,以下是一个简单的安装说明。
OS 准备
# yum -y install coreutils glib2 lrzsz sysstat e4fsprogs xfsprogs ntp readline-devel zlib zlib-devel openssl openssl-devel pam-devel libxml2-devel libxslt-devel python-devel tcl-devel gcc make smartmontools flex bison perl perl-devel perl-ExtUtils* openldap openldap-devel # vi /etc/sysctl.conf # add by digoal.zhou fs.aio-max-nr = 1048576 fs.file-max = 76724600 kernel.core_pattern= /data01/corefiles/core_%e_%u_%t_%s.%p # /data01/corefiles事先建好,权限777 kernel.sem = 4096 2147483647 2147483646 512000 # 信号量, ipcs -l 或 -u 查看,每16个进程一组,每组信号量需要17个信号量。 kernel.shmall = 107374182 # 所有共享内存段相加大小限制(建议内存的80%) kernel.shmmax = 274877906944 # 最大单个共享内存段大小(建议为内存一半), >9.2的版本已大幅降低共享内存的使用 kernel.shmmni = 819200 # 一共能生成多少共享内存段,每个PG数据库集群至少2个共享内存段 net.core.netdev_max_backlog = 10000 net.core.rmem_default = 262144 # The default setting of the socket receive buffer in bytes. net.core.rmem_max = 4194304 # The maximum receive socket buffer size in bytes net.core.wmem_default = 262144 # The default setting (in bytes) of the socket send buffer. net.core.wmem_max = 4194304 # The maximum send socket buffer size in bytes. net.core.somaxconn = 4096 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.tcp_keepalive_intvl = 20 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_keepalive_time = 60 net.ipv4.tcp_mem = 8388608 12582912 16777216 net.ipv4.tcp_fin_timeout = 5 net.ipv4.tcp_synack_retries = 2 net.ipv4.tcp_syncookies = 1 # 开启SYN Cookies。当出现SYN等待队列溢出时,启用cookie来处理,可防范少量的SYN攻击 net.ipv4.tcp_timestamps = 1 # 减少time_wait net.ipv4.tcp_tw_recycle = 0 # 如果=1则开启TCP连接中TIME-WAIT套接字的快速回收,但是NAT环境可能导致连接失败,建议服务端关闭它 net.ipv4.tcp_tw_reuse = 1 # 开启重用。允许将TIME-WAIT套接字重新用于新的TCP连接 net.ipv4.tcp_max_tw_buckets = 262144 net.ipv4.tcp_rmem = 8192 87380 16777216 net.ipv4.tcp_wmem = 8192 65536 16777216 net.nf_conntrack_max = 1200000 net.netfilter.nf_conntrack_max = 1200000 vm.dirty_background_bytes = 409600000 # 系统脏页到达这个值,系统后台刷脏页调度进程 pdflush(或其他) 自动将(dirty_expire_centisecs/100)秒前的脏页刷到磁盘 vm.dirty_expire_centisecs = 3000 # 比这个值老的脏页,将被刷到磁盘。3000表示30秒。 vm.dirty_ratio = 95 # 如果系统进程刷脏页太慢,使得系统脏页超过内存 95 % 时,则用户进程如果有写磁盘的操作(如fsync, fdatasync等调用), # 则需要主动把系统脏页刷出。 # 有效防止用户进程刷脏页,在单机多实例,并且使用CGROUP限制单实例IOPS的情况下非常有效。 vm.dirty_writeback_centisecs = 100 # pdflush(或其他)后台刷脏页进程的唤醒间隔, 100表示1秒。 vm.extra_free_kbytes = 4096000 vm.min_free_kbytes = 2097152 vm.mmap_min_addr = 65536 vm.overcommit_memory = 0 # 在分配内存时,允许少量over malloc, 如果设置为 1, 则认为总是有足够的内存,内存较少的测试环境可以使用 1 . vm.overcommit_ratio = 90 # 当overcommit_memory = 2 时,用于参与计算允许指派的内存大小。 vm.swappiness = 0 # 关闭交换分区 vm.zone_reclaim_mode = 0 # 禁用 numa, 或者在vmlinux中禁止. net.ipv4.ip_local_port_range = 40000 65535 # 本地自动分配的TCP, UDP端口号范围 # vm.nr_hugepages = 102352 # 建议shared buffer设置超过64GB时 使用大页,页大小 /proc/meminfo Hugepagesize # sysctl -p # vi /etc/security/limits.conf * soft nofile 1024000 * hard nofile 1024000 * soft nproc unlimited * hard nproc unlimited * soft core unlimited * hard core unlimited * soft memlock unlimited * hard memlock unlimited # rm -f /etc/security/limits.d/*
安装
$ wget https://ftp.postgresql.org/pub/source/v9.6.0/postgresql-9.6.0.tar.bz2 $ tar -jxvf postgresql-9.6.0.tar.bz2 $ cd postgresql-9.6.0 $ ./configure --prefix=/home/digoal/pgsql9.6.0 $ make world -j 32 $ make install-world -j 32 $ vi ~/.bash_profile export PS1="$USER@`/bin/hostname -s`-> " export PGPORT=5281 export PGDATA=/u02/digoal/pg_root$PGPORT export LANG=en_US.utf8 export PGHOME=/home/digoal/pgsql9.6.0 export LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH export DATE=`date +"%Y%m%d%H%M"` export PATH=$PGHOME/bin:$PATH:. export MANPATH=$PGHOME/share/man:$MANPATH export PGHOST=$PGDATA export PGUSER=postgres export PGDATABASE=postgres alias rm='rm -i' alias ll='ls -lh' unalias vi $ . ~/.bash_profile $ df -h /dev/mapper/vgdata01-lv03 4.0T 1.3T 2.8T 32% /u01 /dev/mapper/vgdata01-lv04 7.7T 899G 6.8T 12% /u02
初始化集群
$ initdb -D $PGDATA -E UTF8 --locale=C -U postgres -X /u01/digoal/pg_xlog$PGPORT
配置数据库参数
$ cd $PGDATA $ vi postgresql.conf listen_addresses = '0.0.0.0' port = 5281 max_connections = 800 superuser_reserved_connections = 13 unix_socket_directories = '.' unix_socket_permissions = 0700 tcp_keepalives_idle = 60 tcp_keepalives_interval = 10 tcp_keepalives_count = 10 shared_buffers = 128GB huge_pages = try maintenance_work_mem = 2GB dynamic_shared_memory_type = sysv vacuum_cost_delay = 0 bgwriter_delay = 10ms bgwriter_lru_maxpages = 1000 bgwriter_lru_multiplier = 10.0 bgwriter_flush_after = 256 max_worker_processes = 128 max_parallel_workers_per_gather = 16 old_snapshot_threshold = 8h backend_flush_after = 256 synchronous_commit = off full_page_writes = off wal_buffers = 128MB wal_writer_delay = 10ms wal_writer_flush_after = 4MB checkpoint_timeout = 55min max_wal_size = 256GB checkpoint_flush_after = 1MB random_page_cost = 1.0 effective_cache_size = 512GB constraint_exclusion = on log_destination = 'csvlog' logging_collector = on log_checkpoints = on log_connections = on log_disconnections = on log_error_verbosity = verbose log_timezone = 'PRC' autovacuum = on log_autovacuum_min_duration = 0 autovacuum_max_workers = 8 autovacuum_naptime = 10s autovacuum_vacuum_scale_factor = 0.02 autovacuum_analyze_scale_factor = 0.01 statement_timeout = 0 lock_timeout = 0 idle_in_transaction_session_timeout = 0 gin_fuzzy_search_limit = 0 gin_pending_list_limit = 4MB datestyle = 'iso, mdy' timezone = 'PRC' lc_messages = 'C' lc_monetary = 'C' lc_numeric = 'C' lc_time = 'C' default_text_search_config = 'pg_catalog.english' deadlock_timeout = 1s $ vi pg_hba.conf local all all trust host all all 127.0.0.1/32 trust host all all ::1/128 trust host all all 0.0.0.0/0 md5
启动数据库
$ pg_ctl start
二、多核并行计算相关参数与用法
1. 控制整个数据库集群同时能开启多少个work process,必须设置。
max_worker_processes = 128 # (change requires restart)
2. 控制一个并行的EXEC NODE最多能开启多少个并行处理单元,同时还需要参考表级参数parallel_workers,或者PG内核内置的算法,
根据表的大小计算需要开启多少和并行处理单元。实际取小的。
max_parallel_workers_per_gather = 16 # taken from max_worker_processes
3. 计算并行处理的成本,如果成本高于非并行,则不会开启并行处理。
#parallel_tuple_cost = 0.1 # same scale as above
#parallel_setup_cost = 1000.0 # same scale as above
4. 小于这个值的表,不会开启并行。
#min_parallel_relation_size = 8MB
5. 告诉优化器,强制开启并行。
#force_parallel_mode = off
6. 表级参数,不通过表的大小计算并行度,而是直接告诉优化器这个表需要开启多少个并行计算单元。
parallel_workers (integer)
This sets the number of workers that should be used to assist a parallel scan of this table.
If not set, the system will determine a value based on the relation size.
The actual number of workers chosen by the planner may be less, for example due to the setting of max_worker_processes.
三、测试场景描述
在标签系统中,通常会有多个属性,每个属性使用一个标签标示,最简单的标签是用0和1来表示,代表true和false。
我们可以把所有的标签转换成比特位,例如系统中一共有200个标签,5000万用户。
那么我们可以通过标签的位运算来圈定特定的人群。
这样就会涉及BIT位的运算。
那么我们来看看PostgreSQL位运算的性能如何?
四、测试1 (数据量大于shared buffer)
创建一张测试表,包含一个比特位字段,后面用于测试。
postgres=# create unlogged table t_bit2 (id bit(200)) with (autovacuum_enabled=off, parallel_workers=128);
CREATE TABLE
并行插入32亿记录
for ((i=1;i<=64;i++)) ; do psql -c "insert into t_bit2 select B'101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010
101010' from generate_series(1,50000000);" & done
单表32亿,180GB
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------+-------+----------+--------+-------------
public | t_bit2 | table | postgres | 180 GB |
全表扫描测试
非并行模式
postgres=# set force_parallel_mode =off; SET postgres=# set max_parallel_workers_per_gather =0; SET postgres=# \timing Timing is on.
执行计划
postgres=# explain (verbose,costs) select * from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010 10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010 1010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101 01010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101 0101010101011'; QUERY PLAN Seq Scan on public.t_bit2 (cost=0.00..71529415.52 rows=16000001 width=32) Output: id Filter: (bitand(t_bit2.id, B'10101010101010101010101010101010101010101010101010101010101010101010 1010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010 10101010101010101010101010101010'::"bit") = B'101010101010101010101010101010101010101010101010101010 1010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010 1010101010101010101010101010101010101010101011'::"bit") (3 rows)
取测试三轮后的结果,排除CACHE影响。
postgres=# explain (analyze,verbose,costs) select * from t_bit2 where bitand(id, '1010101010101010101010101010101010101010101010101010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010101010101010101010101
01010101010101010101010101010101010')=B'1010101010101010101010101010101010101010101
01010101010101010101010101010101010101010101010101010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010101010101011';
Seq Scan on public.t_bit2 (cost=0.00..71529415.52 rows=16000001 width=32)
(actual time=0.033..1135403.694 rows=3200000000 loops=1)
Output: id
Filter: (bitand(t_bit2.id, B'10101010101010101010101010101010101010101010101010101
0101010101010101010101010101010101010101010101010101010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010'::"bit") = B'101010101
0101010101010101010101010101010101010101010101010101010101010101010101010101010101010
1010101010101010101010101010101010101010101010101010101010101010101010101010101010101
010101010101010101011'::"bit")
Planning time: 0.576 ms
Execution time: 1285437.199 ms
(5 rows)
Time: 1285438.195 ms
并行模式
postgres=# set force_parallel_mode =on; postgres=# set max_parallel_workers_per_gather = 64;
取测试三轮后的结果,排除CACHE影响。
postgres=# explain (analyze,verbose,costs) select * from t_bit2 where bitand(id,
'101010101010101010101010101010101010101010101010101010101010101010101010101010101
0101010101010101010101010101010101010101010101010101010101010101010101010101010101
0101010101010101010101010101010101010')=B'1010101010101010101010101010101010101010
1010101010101010101010101010101010101010101010101010101010101010101010101010101010
101010101010101010101010101010101010101010101010101010101010101010101010101011';
Gather (cost=1000.00..26630413.18 rows=16000001 width=32) (actual time=30946.103..30946.103 rows=0 loops=1)
Output: id
Workers Planned: 32
Workers Launched: 32
-> Parallel Seq Scan on public.t_bit2 (cost=0.00..25029413.08 rows=500000 width=32)
(actual time=30941.191..30941.191 rows=0 loops=33)
Output: id
Filter: (bitand(t_bit2.id, B'101010101010101010101010101010101010101010101010101
01010101010101010101010101010101010101010101010101010101010101010101010101010101010101010
101010101010101010101010101010101010101010101010101010101010'::"bit") = B'10101010101
0101010101010101010101010101010101010101010101010101010101010101010101010101010101010101
0101010101010101010101010101010101010101010101010101010101010101010101010101010101010101
0101010101011'::"bit")
Rows Removed by Filter: 96969697
Worker 0: actual time=30938.594..30938.594 rows=0 loops=1
Worker 1: actual time=30939.353..30939.353 rows=0 loops=1
Worker 2: actual time=30939.419..30939.419 rows=0 loops=1
Worker 3: actual time=30939.574..30939.574 rows=0 loops=1
Worker 4: actual time=30939.692..30939.692 rows=0 loops=1
Worker 5: actual time=30939.825..30939.825 rows=0 loops=1
Worker 6: actual time=30939.850..30939.850 rows=0 loops=1
Worker 7: actual time=30940.028..30940.028 rows=0 loops=1
Worker 8: actual time=30940.287..30940.287 rows=0 loops=1
Worker 9: actual time=30940.466..30940.466 rows=0 loops=1
Worker 10: actual time=30940.436..30940.436 rows=0 loops=1
Worker 11: actual time=30940.649..30940.649 rows=0 loops=1
Worker 12: actual time=30940.733..30940.733 rows=0 loops=1
Worker 13: actual time=30940.818..30940.818 rows=0 loops=1
Worker 14: actual time=30941.083..30941.083 rows=0 loops=1
Worker 15: actual time=30941.086..30941.086 rows=0 loops=1
Worker 16: actual time=30940.612..30940.612 rows=0 loops=1
Worker 17: actual time=30941.342..30941.342 rows=0 loops=1
Worker 18: actual time=30941.617..30941.617 rows=0 loops=1
Worker 19: actual time=30941.667..30941.667 rows=0 loops=1
Worker 20: actual time=30941.730..30941.730 rows=0 loops=1
Worker 21: actual time=30941.207..30941.207 rows=0 loops=1
Worker 22: actual time=30942.115..30942.115 rows=0 loops=1
Worker 23: actual time=30942.049..30942.049 rows=0 loops=1
Worker 24: actual time=30941.440..30941.440 rows=0 loops=1
Worker 25: actual time=30942.361..30942.361 rows=0 loops=1
Worker 26: actual time=30942.562..30942.562 rows=0 loops=1
Worker 27: actual time=30942.430..30942.430 rows=0 loops=1
Worker 28: actual time=30942.697..30942.697 rows=0 loops=1
Worker 29: actual time=30942.577..30942.577 rows=0 loops=1
Worker 30: actual time=30942.985..30942.985 rows=0 loops=1
Worker 31: actual time=30942.356..30942.356 rows=0 loops=1
Planning time: 0.061 ms
Execution time: 32566.303 ms
(42 rows)
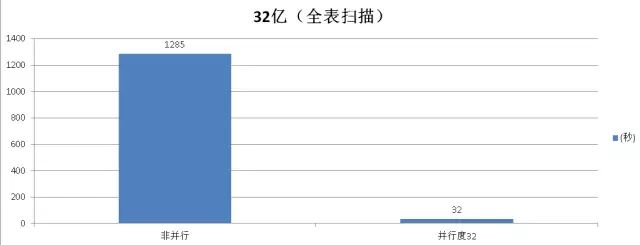
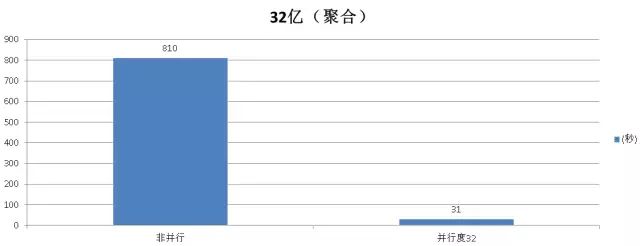
聚合测试
非并行模式
postgres=# set force_parallel_mode =off;
postgres=# set max_parallel_workers_per_gather = 0;
postgres=# select count(*) from t_bit2 where bitand(id,
'10101010101010101010101010101010101010101010101010101010101010101010101
010101010101010101010101010101010101010101010101010101010101010101010101
010101010101010101010101010101010101010101010101010101010')=B'1010101010
101010101010101010101010101010101010101010101010101010101010101010101010
1010101010101010101010101010101010101010101010101010101010101010101010101
010101010101010101010101010101010101010101011';
count
-------
0
(1 row)
Time: 810115.643 ms
并行模式
postgres=# set force_parallel_mode =on;
postgres=# set max_parallel_workers_per_gather = 32;
postgres=# select count(*) from t_bit2 where bitand(id, '10101010101010101
01010101010101010101010101010101010101010101010101010101010101010101010101
01010101010101010101010101010101010101010101010101010101010101010101010101
01010101010101010101010101010101010')=B'1010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010101010101010
10101010101010101010101010101010101010101010101010101010101010101010101010
101010101010101011';
count
-------
0
(1 row)
Time: 31805.820 ms
Postgres大象会2016官方报名通道:http://www.huodongxing.com/event/8352217821400
扫描报名

请在登录后发表评论,否则无法保存。
