| PostgreSQL执行引擎简介 -- 李浩@www.leehao.org 原作者:李浩 创作时间:2016-10-20 20:07:13+08 |
doudou586 发布于2016-10-25 20:07:13
 评论: 2 评论: 2
 浏览: 12046 浏览: 12046
|
PostgreSQL执行引擎简介
2016 Postgres大象会官方报名通道: 点此报名

作者: 李浩@www.leehao.org
日期: 2016-10-25
简介
当一条SQL在经过查询引擎处理的词法、语法,查询优化,访问路径的创建后,我们得了一个理论上最优的查询计划/查询访问路径(Plan/Path)。而该查询访问路径正是之后我们查询结果的来源,当然最终的数据来源于存储引擎中,但是存储引擎中的数据并非是无条件的全部查询出,而是需要满足一定的条件,而这些条件的获得则是由查询访问路径来指定。
执行引擎作为一个连接查询引擎与存储引擎的中间部件,其主要的作用就是将最优查询访问路径转换为相对应的查询引擎操作。通过执行相应的查询引擎接口函数来完成数据的存取工作。

图一:执行引擎所处位置
执行引擎与查询引擎和存储引擎之间的关系如上图所示。因此,我们从上图中可以清晰的看出,执行引擎所接收的输入信息是查询引擎的输出信息-最优查询访问路径,这里我们称之为输入信息,而不仅仅限于输入参数。而执行引擎所产生的输出信息则是一些文件访问操作接口。
为了能够快速且较为方便的访问数据文件,我们并不是直接使用执行引擎来操作相应的数据文件,而是在这些文件操作之上封装了一层,用来提供便捷和高效的文件操作接口,而这些便是存储引擎所需要完成的工作。当然在存储引擎中,为了能够提高操作效率,我们在存储引擎层面上又引入了许多辅助模块来加速数据和文件的访问操作,例如:Buffer模块,以及解决系统文件句柄资源的限制而引入的虚拟文件句柄模块,VFD,等等。在这里我们不打算对于存储引擎进行更加详细的讨论,这里我们将讨论的重点放在执行引擎层(Execution Engine)。
在讨论执行引擎的时候,我们首先要考虑如下的一个问题,我们以什么样的方式来获取数据?即执行引擎所采取数据获取策略。
一个最为朴素的策略就是,一次将满足条件的所有元组取出;采用这样的策略,其优点:简单,易于实现。同样,该种方式存在着相当大的缺点:对于系统资源的需求;当我们在小数据量的环境下时,我们完全可以将所有满足条件的元组一起取出并将这些元组放入到系统内存中,但是当我们在大数据量的环境下,恐怕无论多大的内存空间最后都将会被消耗殆尽,出现Out of Memory问题。因此,可以看出该种方式并非一个完美的解决方案。
作为现今数据库均采用主流方式,Pipe line方式,其与上述方案最大的不同是,按需请求;每次我们只是取出一条元组,在处理本条元组后,系统将会取出下一条满足条件的元组,直到取出所有满足条件的元组为止。从该种方式的运行机制可以看出,其每次执行时对于系统资源的需求非常小。Pipe line运行机制正如我们的抽水井一样,每次操作取出部分资源。该种方式的架构如下:
Data fetch (Path*)
{
If (!init) do_initialization();
While ( get_next() != EOF )
do_something(…) ;
}
在完成对于执行引擎的初始化操作后,由get_next函数来获取一条数据,当我们未到数据集的末尾时候(!= EOF),则继续数据提取操作和数据操作;否则结束本次的数据提取。
作为当今最先进的开源关系型数据库,PostgreSQL执行引擎也采取PIPE-LINE的方式进行数据的获取。PIPE-LINE的思想在不仅在数据库系统中出现,在计算机的许多系统中也同样可以找到其身影,例如最著名的PIPE-LINE的指令处理系统架构。下面我们就来看看PostgreSQL在执行引擎层是如何工作的。
PostgreSQL执行引擎
1.综述
由前述讨论可知,一条SQL语句在经过pg_analyze_and_rewrite中的词法和语法处理以及相应的基于规则系统的优化后,由后续pg_plan_queries函数进行相应的物理优化以及最优查询访问路径的构建工作。即数据库系统中的查询引擎所主要完成的工作。
在经过该步骤后,我们将获得一条最优访问路径,而该最优路径则是后续执行引擎的工作基础。执行引擎将通过遍历该查询访问路径树,对该查询路径树上的每个节点进行分类处理:依据节点的类型构建表访问的相关操作,例如:打开关系表并执行相应的扫描操作;最后,形成最终的查询结果并将该查询结果按照可读方式返回给查询客户端。由exec_simple_query函数中,我们可以清晰的看出上述的讨论。
Void exec_simple_query(…)
{
…
plantree_list = pg_plan_queries(...);
...
PortalStart(portal, NULL, 0, InvalidSnapshot);
...
PortalSetResultFormat(portal, 1, &format);
...
receiver = CreateDestReceiver(dest);
(void) PortalRun(...);
(*receiver->rDestroy) (receiver);
…
}
由上述代码可以看出,由PortalStart进行执行引擎开始执行之前的准备工作,其主要的工作就是创建一个指定名称的Portal变量。Portal类型代表了查询语句在执行过程中的状态信息。由此我们可以看出其描述了查询语句在执行过程中的状态信息,而非执行器在执行过程中的信息。Portal中包含了该查询语句,优化后的查询计划,查询结果的格式信息等等。
当然除了描述语句在执行过程中的状态信息外,我们还需有对执行器在执行过程中所处的每个阶段进行描述,即用来描述执行器的状态信息。当然我们无法使用某个形如Portal类型这样的具体类型来完整的描述整个执行器在执行的过程,而是使用一系列的类型来描述执行器在执行过程中的各个状态信息。这些描述执行器状态信息的类型在include\nodes\execnodes.h中给出,这里就不在对其中的所有类型给出详细介绍。下面我们着重讨论一下PlanState。前文中我们曾提及,在最优查询访问路径在执行的过程中,执行器会依据该查询访问路径,来创建一个相应的执行树。而这里的执行树就由PlanState类型所构成的执行状态树。由如下的PlanState的定义可以看出,PlanState中包括我们在获取数据时的所需三个条件:(1)数据从何处来,由plan, lefttree,righttree等描述;(2)数据需要满足的条件,由qual等描述;(3)数据已何种形式表现,由targetlist等描述。
最后,由类型为TupleTableSlot的ps_ResultTupleSlot变量保存上述的满足条件的结果元组信息。TupeTableSlot大家可以把它看做是一个虚拟的关系表,只是该表中的数据是经过满足我们所提供的扫描条件由数据源中所获取的元组。
typedef struct PlanState
{
NodeTag type;
Plan *plan; /* associated Plan node */
...
List *targetlist; /* target list to be computed at this node */
List *qual; /* implicitly-ANDed qual conditions */
struct PlanState *lefttree; /* input plan tree(s) */
struct PlanState *righttree;
List *initPlan; /* Init SubPlanState nodes (un-correlated expr
* subselects) */
List *subPlan; /* SubPlanState nodes in my expressions */
...
TupleTableSlot *ps_ResultTupleSlot; /* slot for my result tuples */
ExprContext *ps_ExprContext; /* nodes expression-evaluation context */
ProjectionInfo *ps_ProjInfo; /* info for doing tuple projection */
...
} PlanState;
在完成执行状态树的构建后,接下来的任务就是依据该执行状态树进行执行,其流程与原始语法树到查询语法树的转换流程非常相似:遍历相应的树,并根据树中各个节点的类型进行分类处理,例如:如果当前处理的节点类型为:SeqScanState,则表明我们将执行表的顺序扫描操作,此时执行引擎将会调用存储引擎所提供的表操作接口,例如:relation_open, heap_getnext等函数完成表的扫描操作;若当前处理的节点为HashJoinState类型时,会依据hash key和hash func将hj_OuterTupleSlot,hj_HashTupleSlot中的元组进行Hash Join处理。
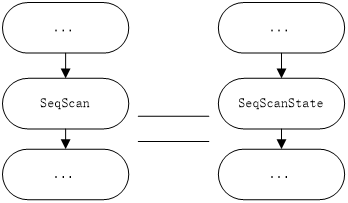
图二:查询计划与执行状态树的对应关系
最后,将最终的满足条件的元组按照预先设定的输出格式,将其发送给查询客户端进行结果展示。
上述就是
2.具体案例讨论
我们使用如下的形式来说明: Create table bar (col1 int);
对于一条形如:select col1 from bar where col1 = 1 的这样查询语句,在经过上述的词法和语法解析后会形成如下的查询语法树:

图三:查询语句的查询语法树
经过查询优化我们得到如下的查询计划:
图四:查询计划
在我们使用explain查看其查询计划后,我们得到的查询计划如下:
db=# explain select col from bar where col=1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Seq Scan on bar (cost=0.00..41.88 rows=13 width=4)
Filter: (col = 1)
(2 rows)
由此可以看出,其使用的SeqScan方式在表bar上进行顺序扫描操作,同时,使用相应的过滤条件是 col=1,即:满足条件col=1的元组将会被作为查询结果返回给查询客户端。
在上述从宏观的层面讨论后,在我们获得一个优化后的查询计划后,执行引擎又是如何具体完成执行?下面我们具体而深入的分析下PostgreSQL查询引擎的工作。
依据上述的讨论可知,PostgreSQL首先会依据查询计划创建相应的执行状态树,而此项工作PortalStart来完成。当未使用第三方的初始化方案后,PostgreSQL最终会standard_ExecutorStart函数来完成查询计划到执行状态树的创建工作。下面代码就描述该项工作。(execMain.c中InitPlan函数)
planstate = ExecInitNode(plan, estate, eflags);
由此可以看出ExecInitNode的输入参数查询计划,Plan;而其相应的输出参数为执行状态树,planstate。
由此我们看出函数ExecInitNode的功能就相对单一而具体:以及查询树中的各个节点的类型构建其对应的执行状态树。该函数的相应架构如下:
switch (nodeTag(node)) {
case T_SeqScan : ExecInitSeqScan (…); break;
case T_NestLoop: ExecInitNestLoop(…) break;
…
default: break;
}
这些ExecInitXXX函数将会依据不同数据类型进行特定的初始化构建工作,在这里我们就不展开讨论了。总之,这些操作的目的就是为执行引擎准备其开始真正执行之前所需要准备的所有基本信息。下面我就以SeqScanState为例
SeqScanState *
ExecInitSeqScan(SeqScan *node, EState *estate, int eflags)
{
SeqScanState *scanstate;
scanstate = makeNode(SeqScanState);
...
scanstate->ss.ps.targetlist = (List *)
ExecInitExpr((Expr *) node->plan.targetlist,
(PlanState *) scanstate);
scanstate->ss.ps.qual = (List *)
ExecInitExpr((Expr *) node->plan.qual,
(PlanState *) scanstate);
ExecInitResultTupleSlot(estate, &scanstate->ss.ps);//初始化保存结果集存的slot
ExecInitScanTupleSlot(estate, &scanstate->ss); //初始扫描集的slot
InitScanRelation(scanstate, estate, eflags); //在该函数中进行relation_open操作。
…
return scanstate;
}
从上述代码中可以看出,在函数分别处理了上述讨论中所论述扫描操作所涉及的三个问题,由ExecInitExpr分别处理目标列和扫描约束条件;在InitScanRelation函数中又对数据源进行了处理,即:关系表的打开。在关系表的操作时候,此时执行引擎第一次近距离的接触到存储引擎,heap_open,relation_open等函数。
当完成了执行状态树的构建后,接下来的任务就是依据执行状态树进行执行操作。此项操作由PortalRun函数来完成。PortalRun函数中又会依据策略的不同进行分类处理。本例中该项操作交由PortalRunSelect来具体完成。PortalRunSelect函数在完成相应扫描方向,快照信息等信息的设定后,由执行引擎使用ExecutorRun(ExecutePlan)函数启动执行。此时,该函数就功能就比较明确了,依据执行状态树执行。
static void
ExecutePlan(EState *estate,
PlanState *planstate,
bool use_parallel_mode,
CmdType operation,
bool sendTuples,
uint64 numberTuples,
ScanDirection direction,
DestReceiver *dest)
{
...
for (;;)
{
...
slot = ExecProcNode(planstate);
if (TupIsNull(slot)) //无可用记录,跳出执行
{
/* Allow nodes to release or shut down resources. */
(void) ExecShutdownNode(planstate);
break;
}
...
}
}
上文中我们曾经指出当今的执行引擎数据获取的方式都为Pipe-line的方式进行且示例代码1中也给出了相应模型。从PostgreSQL中ExecutePlan函数中可以看出其价格模型与我们示例代码1所给出的形式一样。当我们在获得最后一条元组后,下一次的比较TupIsNull(slot)将为真,表明我们已经扫描到结果集中的最后,完成本次执行。
对于本例来说,在ExecProcNode函数中将进入到SeqScan的处理流程中,即执行顺序扫描操作。
case T_SeqScanState: result = ExecSeqScan((SeqScanState *) node); break;
又由ExecSeqScan函数可以看到,在该函数中通过对执行Scan操作的函数ExecScan设定相应的访问接口方法SeqNext以及约束条件检查方法SeqRecheck后。通过ExecScanFetch函数中执行该方法进行相应的扫描操作。
return (*accessMtd) (node); //此处调用的函数为SeqNext.
SeqNext函数中使用存储引擎所提供的访问接口heap_beginscan,heap_getnext进行基表扫描并将扫描出的元组保存。
当完成最低层的元组获取后,上层的Hash Join,NestLoop等操作即可在这些元组基础之上进行下一步的计算,在这里就不展开讨论了。
至此,我们就简单的讨论了PostgreSQL执行引擎的相关实现机制。从上面讨论可以看出,所有操作在执行更高的逻辑处理之前,首先要都会落到存储引擎的基表扫描操作,无论是进行SeqScan或是IndexScan操作。当然你要问我是否可以支持其它的存储引擎?答案显然是可以的,当然前提是其它存储引擎提供与PostgreSQL现有的相同存储访问接口。
如果我们需要对执行增加特定功能支持,我们只需要对ExecProcNode等函数中的分类添加相应特定处理函数即可。
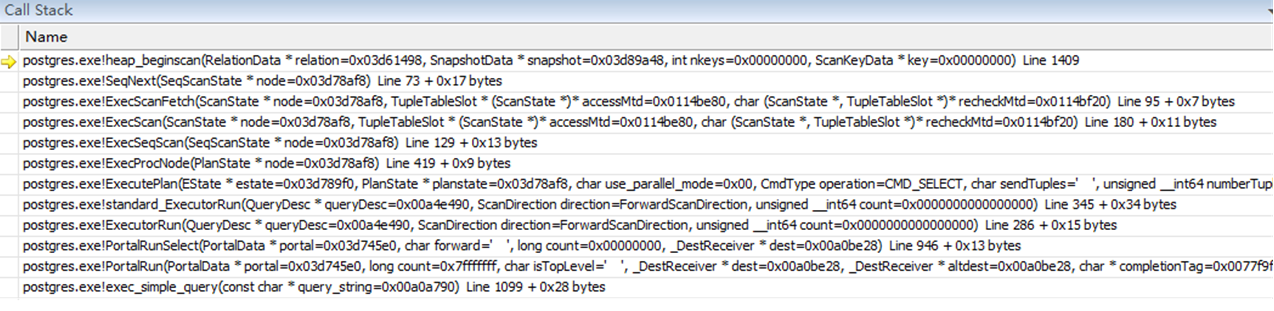
图五:函数执行调用栈信息
图六:pgAdmin所得图形化执行情况说明(与本例不同,示范作用)
2016 Postgres大象会官方报名通道:http://www.huodongxing.com/event/8352217821400
扫描报名

请在登录后发表评论,否则无法保存。
