| pgpool-II多种应用场景性能测试报告 原作者:阿弟 创作时间:2017-08-13 11:00:58+08 |
doudou586 发布于2017-08-13 11:00:58
 评论: 2 评论: 2
 浏览: 29807 浏览: 29807
|
pgpool-II多种应用场景性能测试报告
作者: PostgreSQL中国社区---阿弟
联系: 4893310 / 4893310@qq.com
欢迎大家踊跃投稿,投稿信箱: press@postgres.cn
目录
一、测试机器及部署环境说明
二、postgresql运行参数配置
三、pgpool-II部署及运行参数配置
四、pgbench性能测试对比
五、性能分析及应用总结
一、测试机器及部署环境说明
1、Postgresql主备节点部署硬件
| 项目 | 型号或大小 |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 16线锃 * 1 |
| RAM | 64G |
| 硬盘 | 4*600G SAS 15k 组成raid10 |
| 列阵卡 | H710 Mini |
| 写入方式 | Write Back |
2、pgpool部署机器硬件
| 项目 | 型号或大小 |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 12线锃 * 1 |
| RAM | 32G |
| 硬盘 | 300*1 SAS 15k |
| 列阵卡 | H310 Mini |
| 写入方式 | Write Through |
和
| 项目 | 型号或大小 |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 16线锃 * 1 |
| RAM | 64G |
| 硬盘 | 4*600G SAS 15k 组成raid10 |
| 列阵卡 | H310 Mini |
| 写入方式 | Write Through |
3、pgbench运行机器硬件
| 项目 | 型号或大小 |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 12线锃 * 1 |
| RAM | 32G |
| 硬盘 | 300*1 SAS 15k |
| 列阵卡 | H310 Mini |
| 写入方式 | Write Through |
4、各应用软件版本
| 项目 | 版本号 |
|---|---|
| OS | Centos6.9 |
| Postgresql | 9.6.1 |
| pgpool | pgpool-II-3.6.4 |
| Gcc | 4.4.7 20120313 (Red Hat 4.4.7-18) (GCC) |
二、postgresql运行参数配置
1、posgresql.conf配置
listen_addresses = '0.0.0.0' port = 9610 max_connections = 500 shared_buffers = 16384MB work_mem = 4MB maintenance_work_mem = 512MB autovacuum_work_mem = -1 checkpoint_timeout = 60min max_wal_size = 6GB min_wal_size = 2GB checkpoint_warning = 30s wal_level = replica max_wal_senders = 3 wal_keep_segments = 8000 hot_standby = on max_standby_archive_delay = 1800s max_standby_streaming_delay = 1800s log_destination = 'csvlog' logging_collector = on log_min_duration_statement = 1000 log_checkpoints = on autovacuum = on log_autovacuum_min_duration = 0 autovacuum_max_workers = 3 timezone = 'PRC'
2、pg_hba.conf配置
host all all 127.0.0.1/32 md5 host all all 192.168.1.0/24 md5 host replication postgres 192.168.1.0/24 md5
3、recovery.conf配置
standby_mode = 'on' primary_conninfo = 'host=192.168.1.146 port=9610 user=postgres password=pgsql' recovery_target_timeline = 'latest'
三、pgpool-II部署及运行参数配置
1、下载pgpool源码
[root@pgpool-01 source]# wget http://www.pgpool.net/download.php?f=pgpool-II-3.6.4.tar.gz
2、编译安装pgpool
[root@pgpool-01 source]# tar zxf pgpool-II-3.6.4.tar.gz [root@pgpool-01 source]# cd pgpool-II-3.6.4 [root@pgpool-01 pgpool-II-3.6.4]# ./configure --prefix=/usr/local/pgpool-II-3.6.4/ --with-pgsql=/usr/local/pgsql9.6.1 --with-openssl [root@pgpool-01 source]# gmake [root@pgpool-01 source]# gmake install
为pgpool 软连接一个标准运行目录
[root@pgpool-01 pgpool-II-3.6.4]# ln -s /usr/local/pgpool-II-3.6.4 /usr/local/pgpool
3、配置pgpool.conf
[root@pgpool-01 pgpool-II-3.6.4]# cd /usr/local/pgpool/etc [root@pgpool-01 etc]# cp pgpool.conf.sample-stream pgpool.conf [root@pgpool-01 etc]# vim /usr/local/pgpool/etc/pgpool.conf #监听参数配置 listen_addresses = '*' port = 9999 socket_dir = '/tmp' pcp_listen_addresses = '*' pcp_port = 9898 pcp_socket_dir = '/tmp' #节点参数配置 #节点一 backend_hostname0 = '192.168.1.146' backend_port0 = 9610 backend_weight0 = 0 backend_data_directory0 = '/home/postgres/data9.6.1' backend_flag0 = 'ALLOW_TO_FAILOVER' #节点二 backend_hostname1 = '192.168.1.12' backend_port1 = 9610 backend_weight1 = 0 backend_data_directory1 = '/home/postgres/data9.6.1' backend_flag1 = 'ALLOW_TO_FAILOVER' #认证方法配置 enable_pool_hba = on pool_passwd = 'pool_passwd' #连接池配置 num_init_children = 200 max_pool = 4 #日志配置 log_destination = 'syslog' log_connections = off log_hostname = off log_statement = off log_per_node_statement = off syslog_facility = 'LOCAL0' syslog_ident = 'pgpool' #pid文件及状态文件存放路径 pid_file_name = '/usr/local/pgpool/pgpool.pid logdir = '/usr/local/pgpool' #pgpool工作方式,负载+复制(流复制方式) load_balance_mode = on master_slave_mode = on master_slave_sub_mode = 'stream' #连接状态检查 sr_check_period = 10 sr_check_user = 'postgres' sr_check_password = 'pgsql' sr_check_database = 'postgres'
4、配置pcp.conf
生成pcp工具连接用户名及密码
[root@pgpool-01 etc]# pg_md5 -u pgpool -p password: ba777e4c2f15c11ea8ac3be7e0440aa0
配置pcp.conf文件
[root@pgpool-01 etc]# cp pcp.conf.sample pcp.conf [root@pgpool-01 etc]# vim pcp.conf # USERID:MD5PASSWD pgpool:ba777e4c2f15c11ea8ac3be7e0440aa0
5、配置pool_hba.conf
[root@pgpool-01 etc]# vim pool_hba.conf host all all 127.0.0.1/32 md5 host all all 192.168.1.0/24 md5
6、生成pool_passwd配置文件
[root@pgpool-01 etc]# pg_md5 -m -u postgres pgsql [root@pgpool-01 etc]# cat pool_passwd postgres:md5859b0f43555758bfa7e9cc24a8a964c1 [root@pgpool-01 etc]#
7、配置pgpool使用环境
在/etc/profile文件中增加下面内容
PATH=/usr/local/pgpool/bin:$PATH export PATH
环境变量生效
[root@pgpool-01 etc]# source /etc/profile [root@pgpool-01 etc]# which pgpool /usr/local/pgpool/bin/pgpool
8、配置pgpool日志
[root@pgpool-01 etc]# vim /etc/rsyslog.conf local0.* /var/log/pgpool.log [root@pgpool-01 etc]# service rsyslog restart 关闭系统日志记录器: [确定] 启动系统日志记录器: [确定] [root@pgpool-01 etc]#
9、配置.pgpass密码文件
[postgres@gpool-01 etc]$ vim /home/postgres/.pgpass *.:9610:*:postgres:pgsql *.:9999:*:postgres:pgsql [postgres@ppool-01 etc]$ chmod 0600 /home/postgres/.pgpass
10、启动pgpool服务
[root@pgpool-01 etc]# su postgres [postgres@pgpool-01 etc]$ pgpool
四、pgbench性能测试对比
1、pgbench使用注意点
1)、发单进程的pgbench使用的CPU为100%时需要分成三个进程的pgbench同时跑
2)、跑pgbench需要在另外一台机器上执行,否则会占用比较多的pgpool或postgresql的系统资源
3)、pgbench的latency average计算是包括向测试终端输出信息事个过程,所以测试时需要把pgbench输出导向文件,才能获取比较准确的tps和qps,否则相差几十倍的性能值都有可能。
4)、跑pgbench前先用 ethtool em1检查网卡当前工作速率,有些网卡是10/100/1000MB自适用,以确认网卡带宽是否足够,pgbench测试过程中网络带宽经常也会成为瓶颈。
2、测试节点上配置.pgpass文件
[postgres@pgbench-01 ~]$ vim /home/postgres/.pgpass *:9610:*:postgres:pgsql *:9999:*:postgres:pgsql [postgres@pgbench-01~]$ chmod 0600 /home/postgres/.pgpass
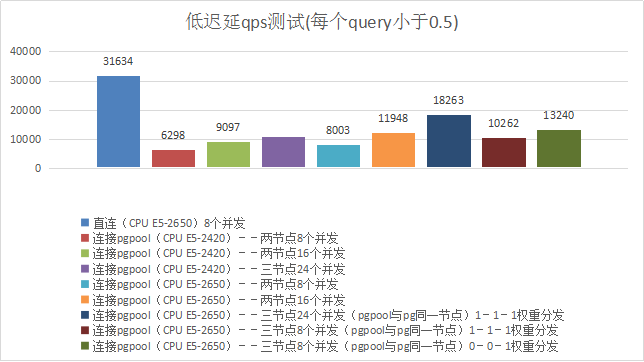
3、低迟延qps测试(每个query小于0.5)
1)、生成测试数据
create table t (id serial not null unique ,remark text); insert into t (remark) select md5(random()::text) from generate_series(1,1000000); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim sele_bench.sql
\set id random(1, 1000000)
select * from t where id=:id;
执行的开销少于0.1ms
postgres=# explain (analyze,buffers) select * from t where id=1000000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Scan using t_id_key on t (cost=0.42..8.44 rows=1 width=37)
(actual time=0.020..0.021 rows=1 loops=1)
Index Cond: (id = 1000000)
Buffers: shared hit=4
Planning time: 0.107 ms
Execution time: 0.055 ms
(5 rows)
3)、测试结果
#直接连接pg /usr/local/pgsql9.6.1/bin/pgbench -h 192.168.1.146 -U postgres -d postgres -p 9610 -M prepared -c 8 -T 60 -f /home/postgres/shell/sele_bench.sql > /home/postgres/146bench_8c_60s_1.txt 2 > &1 #连接pgpool /usr/local/pgsql9.6.1/bin/pgbench -h 192.168.1.21 -U postgres -d postgres -p 9999 -M prepared -c 8 -T 60 -f /home/postgres/shell/sele_bench.sql > /home/postgres/21bench_8c_60s_1.txt 2 > &1
| 项目 | Qps |
|---|---|
| 直连8个并发 | 31634 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 6298 |
| 连接pgpool--两节点16个并发 | 9097 |
| 连接pgpool--三节点24个并发 | 10610 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 7166 |
| 连接pgpool--两节点16个并发 | 11948 |
| 连接pgpool--三节点24个并发(pgpool与pg同一节点)1-1-1权重分发 | 18263 |
| 连接pgpool--三节点8个并发(pgpool与pg同一节点)1-1-2权重分发 | 10262 |
| 连接pgpool--三节点8个并发(pgpool与pg同一节点)0-0-1权重分发 | 13240 |
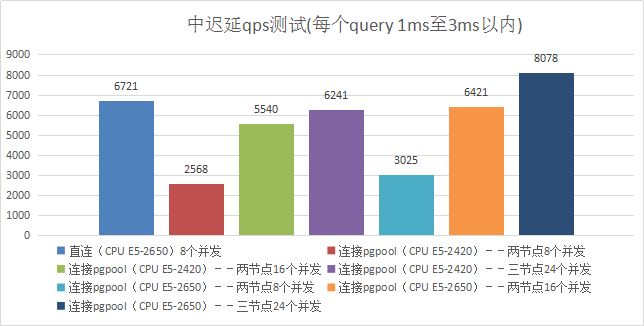
4、中迟延qps测试(每个query 1ms至3ms以内)
1)、生成测试数据
drop table t; create table t (id serial not null ,remark text); insert into t (remark) select md5(random()::text) from generate_series(1,10000); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim sele_bench.sql
\set id random(1, 10000)
select * from t where id=:id;
#执行的开销少于2ms
postgres=# explain (analyze,buffers) select * from t where id=10000;
QUERY PLAN
----------------------------------------------------------------------
Seq Scan on t (cost=0.00..209.00 rows=1 width=37)
(actual time=1.720..1.720 rows=1 loops=1)
Filter: (id = 10000)
Rows Removed by Filter: 9999
Buffers: shared hit=84
Planning time: 0.057 ms
Execution time: 1.743 ms
(6 rows)
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 6721 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 2568 |
| 连接pgpool--两节点16个并发 | 5540 |
| 连接pgpool--三节点24个并发 | 6241 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 3025 |
| 连接pgpool--两节点16个并发 | 6421 |
| 连接pgpool--三节点24个并发 | 8078 |
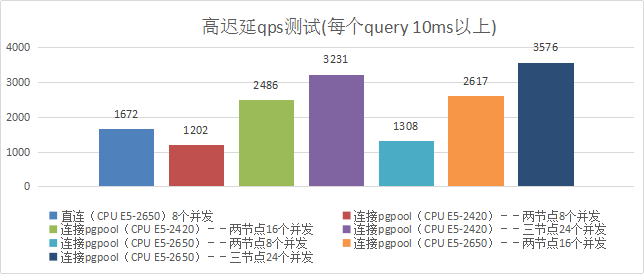
5、高迟延qps测试(每个query 10ms以上)
1)、生成测试数据
drop table t; create table t (id serial not null ,remark text); insert into t (remark) select md5(random()::text) from generate_series(1,60000); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim sele_bench.sql
\set id random(1, 60000)
select * from t where id=:id;
#执行的开销10ms以上
postgres=# explain (analyze,buffers) select * from t where id=60000;
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1250.00 rows=1 width=37)
(actual time=10.371..10.372 rows=1 loops=1)
Filter: (id = 60000)
Rows Removed by Filter: 59999
Buffers: shared hit=500
Planning time: 0.076 ms
Execution time: 10.399 ms
(6 rows)
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 1672 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 1202 |
| 连接pgpool--两节点16个并发 | 2486 |
| 连接pgpool--三节点24个并发 | 3231 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 1308 |
| 连接pgpool--两节点16个并发 | 2617 |
| 连接pgpool--三节点24个并发 | 3576 |
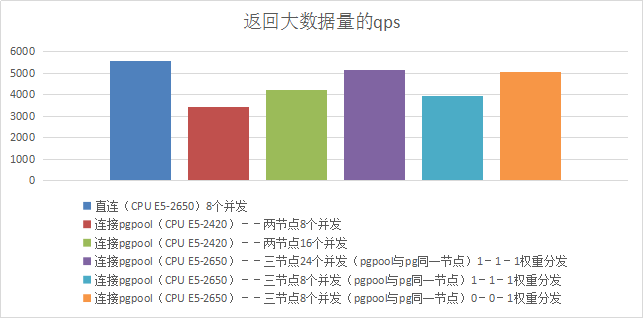
6、返回大数据量的qps
1)、生成测试数据
drop table t;
create table t (id serial not null unique ,remark text);
insert into t (remark) select repeat('hello pg,我是阿弟', 1000) from
generate_series(1,10000);
vacuum;
analyze;
每条数据大约12K
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim sele_bench.sql \set id random(1, 10000) select * from t where id=:id;
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 5586 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 3447 |
| 连接pgpool--两节点16个并发 | 4246 |
| 连接pgpool--三节点24个并发(pgpool与pg同一节点)1-1-1权重分发 | 5180 |
| 连接pgpool--三节点8个并发(pgpool与pg同一节点)1-1-2权重分发 | 3961 |
| 连接pgpool--三节点8个并发(pgpool与pg同一节点)0-0-1权重分发 | 5051 |
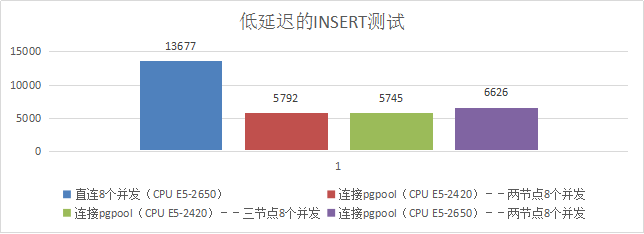
7、低延迟的INSERT测试
1)、生成测试数据
drop table t; create table t (id serial not null unique,remark text); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim insert_bench.sql insert into t(remark) values(md5(random()::text));
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 13677 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 5792 |
| 连接pgpool--三节点8个并发 | 5745 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 6626 |
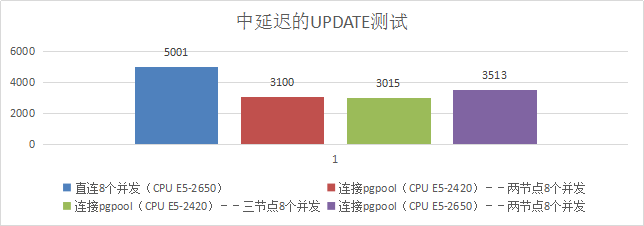
8、中延迟的UPDATE测试
1)、生成测试数据
drop table t; create table t (id serial not null ,remark text); insert into t (remark) select md5(random()::text) from generate_series(1,10000); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim update_bench.sql
\set id random(1, 10000)
update t set remark=md5(random()::text) where id=:id
#执行开销
explain (analyze,buffers) update t set remark =md5(random()::text) where id=1;
QUERY PLAN
------------------------------------------------------------------------------
Update on t (cost=0.00..209.01 rows=1 width=42)
(actual time=1.885..1.885 rows=0 loops=1)
Buffers: shared hit=85
-> Seq Scan on t (cost=0.00..209.01 rows=1 width=42)
(actual time=1.856..1.857 rows=1 loops=1)
Filter: (id = 1)
Rows Removed by Filter: 9999
Buffers: shared hit=84
Planning time: 0.086 ms
Execution time: 1.924 ms
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 5001 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 3100 |
| 连接pgpool--三节点8个并发 | 3015 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 3513 |
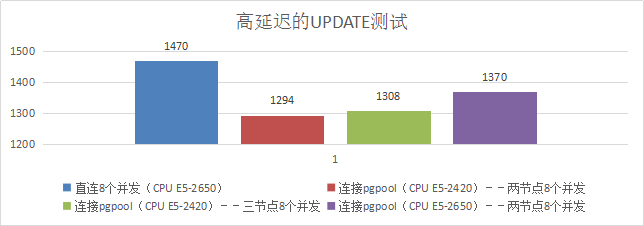
9、高延迟的UPDATE测试
1)、生成测试数据
drop table t; create table t (id serial not null ,remark text); insert into t (remark) select md5(random()::text) from generate_series(1,60000); vacuum; analyze;
2)、编写测试脚本
[postgres@pgbench-01 shell]$ vim update_bench.sql
\set id random(1, 60000)
update t set remark=md5(random()::text) where id=:id
#执行开销
postgres=# explain (analyze,buffers) update t set remark =md5(random()::text)
where id=60000;
QUERY PLAN
-------------------------------------------------------------------------------
Update on t (cost=0.00..1250.01 rows=1 width=42)
(actual time=10.616..10.616 rows=0 loops=1)
Buffers: shared hit=506 read=1 dirtied=1
-> Seq Scan on t (cost=0.00..1250.01 rows=1 width=42)
(actual time=10.485..10.487 rows=1 loops=1)
Filter: (id = 60000)
Rows Removed by Filter: 59999
Buffers: shared hit=500
Planning time: 0.124 ms
Execution time: 10.656 ms
(8 rows)
3)测试结果
| 项目 | Qps |
|---|---|
| 直连8个并发 | 1470 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz 6核心 | |
| 连接pgpool--两节点8个并发 | 1294 |
| 连接pgpool--三节点8个并发 | 1308 |
| Pgpool服务器CPU--Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 8核心 | |
| 连接pgpool--两节点8个并发 | 1370 |
五、性能分析及应用总结
1、select通信捉包分析
发送select * from t where id=100这样的语句
#客户端-〉pgpool
17:38:25.026869 IP 192.168.1.11.36426 > 192.168.1.21.distinct: Flags [P.], seq 35:70,
ack 124, win 29, length 35
#Pgpool-〉pg
17:38:25.085689 IP 192.168.1.21.hexarc > 192.168.1.146.9610: Flags [P.], seq 1:36,
ack 1, win 31, length 35
#执行结果返回
#Pg->pgpool
17:38:25.086287 IP 192.168.1.146.9610 > 192.168.1.21.hexarc: Flags [P.], seq 1:124,
ack 36, win 39, length 123
17:38:25.086299 IP 192.168.1.21.hexarc > 192.168.1.146.9610: Flags [.],
ack 124, win 31, length 0
#Pgpool-〉客户端
17:38:25.027795 IP 192.168.1.21.distinct > 192.168.1.11.36426: Flags [P.], seq 124:177,
ack 70, win 29, length 53
17:38:25.027812 IP 192.168.1.11.36426 > 192.168.1.21.distinct: Flags [.],
ack 177, win 29, length 0
17:38:25.027819 IP 192.168.1.21.distinct > 192.168.1.11.36426: Flags [P.], seq 177:241,
ack 70, win 29, length 64
17:38:25.027826 IP 192.168.1.11.36426 > 192.168.1.21.distinct: Flags [.],
ack 241, win 29, length 0
17:38:25.027832 IP 192.168.1.21.distinct > 192.168.1.11.36426: Flags [P.], seq 241:247,
ack 70, win 29, length 6
17:38:25.027839 IP 192.168.1.11.36426 > 192.168.1.21.distinct: Flags [.],
ack 247, win 29, length 0
当客户端向pgpool发出select * from t where id=100;这样的查询时,pgool会把语句转发给pg--这个通信没问题。但当数据返回时pgpool的处理就有问题了,pg直接一次返回给pgpool,但pgpool竟然分三次返回。
2、insert通信捉包分析
发送这样的insert into t(remark) values(md5(random()::text));语句
#客户端-〉pgpool 17:11:40.851896 IP 192.168.1.11.42150 > 192.168.1.21.distinct: Flags [P.], seq 196:252, ack 582, win 29, length 56 #Pgpool-〉pg 17:11:40.898114 IP 192.168.1.21.dtserver-port > 192.168.1.146.9610: Flags [P.], seq 1185:1241, ack 1023, win 31, length 56 #执行结果返回 #Pg->pgpool 17:11:40.906169 IP 192.168.1.146.9610 > 192.168.1.21.dtserver-port: Flags [P.], seq 1023:1045, ack 1241, win 39, length 22 17:11:40.906183 IP 192.168.1.21.dtserver-port > 192.168.1.146.9610: Flags [.], ack 1045, win 31, length 0 #Pgpool-〉客户端 17:11:40.860338 IP 192.168.1.21.distinct > 192.168.1.11.42150: Flags [P.], seq 582:598, ack 252, win 29, length 16 17:11:40.860353 IP 192.168.1.11.42150 > 192.168.1.21.distinct: Flags [.], ack 598, win 29, length 0 17:11:40.860360 IP 192.168.1.21.distinct > 192.168.1.11.42150: Flags [P.], seq 598:604, ack 252, win 29, length 6 17:11:40.860364 IP 192.168.1.11.42150 > 192.168.1.21.distinct: Flags [.], ack 604, win 29, length 0
当客户端向pgpool发出insert into t(remark) values(md5(random()::text));这样的插入语句时,pgool会把语句转发给pg--这个通信没问题。但当返回执行结果通知时就有问题了,pg直接一次返回给pgpool,但pgpool这次分二次返回,update、delete的通信也跟insert一致。
3、pgpool测试应用总结
1)、pgpool返回结果时会拆包,这个跟pgboucner或者haproxy不拆包有区别。
2)、pgpool及时发送零碎小数据包,减少数据存入缓冲区,通常情况下系统性能会更高,但如果高并发时,由于每个包都带有包头和交互次数增加,反而就会占用更大的网络io。
3)、就测试来看,pgpool比较适合于对于查询开销比较大(1ms以上),或者查询返回的流量比较大的应用。
社区资源
Pgpool相关
http://www.pgpool.net
http://www.pgpool.net/docs/latest/tutorial-zh_cn.html
http://francs3.blog.163.com/blog/static/4057672720149285445881/
Pgbench使用文档
http://www.postgres.cn/docs/9.6/pgbench.html

请在登录后发表评论,否则无法保存。
