
作者: digoal
日期: 2016-10-06
标签: PostgreSQL , 9.6 , 平滑 fsync , write , smooth fsync
背景
汽车换挡是否平顺,通常取决于档位数,或者换挡技术。档位数越多,换挡时感觉会约平顺,档位数较少的情况下,换挡可能会有比较明显的顿挫感觉。
数据库也一样,有些时候可能就会出现卡顿的现象,比如尖锐(堆积)的IO需求时。
本文将给大家介绍9.6在fsync, write方面的平顺性改进,减少尖锐的IO需求。
数据库为了保证数据可靠性,同时还要保证好的读写性能,以及读写的一致性,经过多年的发展,REDO日志,shared buffer基本已经成为数据库的标配。
为了保证数据的可靠性,通常需要在将dirty page刷盘前,保证其REDO先刷盘,然后再通过LRU算法异步的老化shared buffer中的dirty page。
为了保证好的读写性能,通常会需要shared buffer,写先落在shared buffer中,而不是直接同步修改数据页,因为数据页很离散。 数据库会把把离散的IO转换成顺序的REDO IO。
那么问题来了,什么时候会调用fsync,什么时候会调用write呢?为什么9.6会需要优化平滑的fsync, write呢?
数据库哪些场合调用fsync,write?
write
调用write的地方较多,我举一些非常重度的write场景,也是9.6重点优化的地方。
1. shared buffer
bgwriter后台进程会将shared buffer中的脏页根据设置的唤醒时间,老化算法,写调度设置,将老化的dirty page写到操作系统。 (调用系统的write接口) 。
backend process 进程,当请求shared buffer中的page时,如果没有足够的空闲page则会主动触发与bgwriter一样的操作,将老化的dirty page写到操作系统。 (调用系统的write接口) 。
2. wal buffer
walwriter后台进程,将wal buffer中的脏页根据设置的唤醒时间,将wal buffer中的dirty page写到操作系统。 (调用系统的write接口) 。
注意walwriter的fsync接口是可配置的,有buffer writer也有direct IO。 如果配置了direct io则直接落盘,不会写到操作系统的dirty page。
大内存主机隐藏的write问题
因为write实际上是写到了操作系统中,操作系统再调度将脏页落盘。操作系统调度刷脏页涉及到几个内核参数,同时还涉及到文件系统。
vm.dirty_background_ratio = 10 # 表示当脏页比例达到了内存的10%,系统触发background flush线程刷脏页
vm.dirty_ratio = 20 # 当脏页比例达到20%,用户进程在调用write时,会触发flush磁盘的操作。
vm.dirty_writeback_centisecs = 50 # background flush线程的唤醒间隔(单位:百分之一秒)
vm.dirty_expire_centisecs = 6000 # background flush线程将存活时间超过该值的脏页刷盘(类似LRU)(单位:百分之一秒)
如果系统内存非常大,当触发后台线程刷脏页时,可能需要刷很多脏页,导致尖锐的IO需求。
因此,我们可以通过修改内核参数达到削尖的目的。
vm.dirty_background_bytes = 102400000 # 当脏页数达到了100MB,系统触发background flush线程刷脏页
但是这样设置可能还不够,因为数据库是可以并发操作的(wal writer, bgwriter, backend processes都可能并发的调用write),也就是说高峰时产生脏页的速度可能远远大于操作系统后台线程flush的速度。
因此这种情况下os dirty page还是可能堆积,爆发尖锐的IO需求。
fsync
1. create database
创建数据库时,需要COPY 模板库DIR,每个文件COPY一部分后,会调用sync_file_range,最后调用fsync持久化。
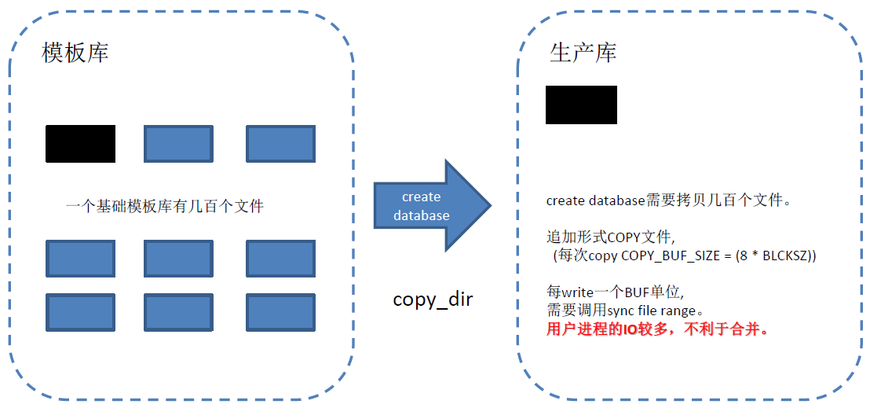
如果模板库文件数多,或者文件很大,可能导致产生较多的os dirty page。
2. checkpoint
2.1 首先标记shared buffer中的脏页
2.2 对已标记为脏页的PAGE,调用write
如果shared buffer很大,并且业务形态导致数据库产生脏页速度很快的话,检查点会瞬间产生很多的os dirty page。
2.3 对相关的fd,调用fsync,持久化
数据库检查点进程调用fsync,如果OS后台线程没有将检查点过程中write出去的脏页落盘,数据库检查点进程fsync会产生大量的刷盘IO。
3. wal writer
wal writer会根据配置的fsync系统调用方法、调度间隔,将wal buffer中的数据刷到XLOG文件。
如果wal buffer配置较大,同时数据库高并发的产生大量的REDO,则WAL writer也会产生大量的写盘IO。
fsync隐藏的问题
1. 如果模板库文件数多,或者文件很大,create database可能导致瞬间产生较多的os dirty page,在文件write完后,调用fsync导致大量的写盘IO。
2. 如果shared buffer很大,并且业务形态导致数据库产生脏页速度很快的话,检查点会瞬间产生很多的os dirty page。
3. 数据库检查点进程调用fsync,如果OS后台线程没有将检查点过程中write出去的脏页落盘,数据库检查点进程fsync会产生大量的刷盘IO。
4. 如果wal buffer配置较大,同时数据库高并发的产生大量的REDO,则WAL writer也会产生大量的写盘IO。
尖锐IO需求问题分析
前面分析了数据库write, fsync在特定的场景(通常是写非常重的场景)中,可能导致大量的IO需求。
这些需求其实是因为数据库为了提高性能,大量的时候了BUFFER,并且没有很好的处理BUFFER堆积,导致蜂拥而至的写盘IO请求。
通过配置OS的backend flush线程的调度参数,可以缓解,但是不能彻底根治(无法抵御高并发的写,有点像三英占吕布的感觉,吕布再强也干不过高并发的写操作产生的os dirty page)。
那么9.6是如何改进的呢?
9.6平滑fsync,write优化
1. 新增 sync_file_range 异步写的调度策略
Where feasible, trigger kernel writeback after a configurable number of writes, to prevent accumulation of dirty data in kernel disk buffers (Fabien Coelho, Andres Freund)
PostgreSQL writes data to the kernel's disk cache, from where it will be flushed to physical storage in due time.
Many operating systems are not smart about managing this and allow large amounts of dirty data to accumulate before deciding to flush it all at once,
causing long delays for new I/O requests until the flushing finishes.
This change attempts to alleviate this problem by explicitly requesting data flushes after a configurable interval.
On Linux, sync_file_range() is used for this purpose, and the feature is on by default on Linux because that function has few downsides.
This flushing capability is also available on other platforms if they have msync() or posix_fadvise(),
but those interfaces have some undesirable side-effects so the feature is disabled by default on non-Linux platforms.
The new configuration parameters backend_flush_after, bgwriter_flush_after, checkpoint_flush_after, and wal_writer_flush_after control this behavior.
通过以下4个参数,控制这4中进程的write操作
backend_flush_after, (单位:BLCKSZ )
当某backend process write dirty page的数量超过配置阈值时,触发调用OS sync_file_range,告诉os backend flush 线程异步刷盘。
从而削减os dirty page堆积。
bgwriter_flush_after, (单位:BLCKSZ )
当bgwriter process write dirty page的数量超过配置阈值时,触发调用OS sync_file_range,告诉os backend flush 线程异步刷盘。
从而削减os dirty page堆积。
checkpoint_flush_after, (单位:BLCKSZ )
当checkpointer process write dirty page的数量超过配置阈值时,触发调用OS sync_file_range,告诉os backend flush 线程异步刷盘。从而削减os dirty page堆积。
wal_writer_flush_after (单位:size)
当wal writer process write dirty page的数量超过配置阈值时,触发调用OS sync_file_range,告诉os backend flush 线程异步刷盘。
从而削减os dirty page堆积。
9.6以前的版本,我们可以认为他们是没有克制的滥用write调用,高峰时比较容易出现os backend flush线程跟不上的节奏。
9.6改成了有节制的使用write,即每隔一段,会提醒后台线程刷脏页。
但是由于使用的是sync_file_range的异步接口,问题可能不能完全解决,再改进一下,当os dirty page超过多少的时候,触发sync_file_range的同步调用可能更好(起到抑制产生脏页的速度的左右)。
2. 检查点write属于同一个fd的dirty page时,排序后再write,从而降低离散的IO。
Perform checkpoint writes in sorted order (Fabien Coelho, Andres Freund)
Previously, checkpoints wrote out dirty pages in whatever order they happen to appear in shared buffers, which usually is nearly random.
That performs poorly, especially on rotating media.
This change causes checkpoint-driven writes to be done in order by file and block number, and to be balanced across tablespace.
Postgres大象会2016官方报名通道:http://www.huodongxing.com/event/8352217821400
扫描报名


https://zulin.tiancebbs.cn/sh/5130.html
https://taishitun.tiancebbs.cn/
https://chaolian.tiancebbs.cn/mayi-news.xml
https://huale.tiancebbs.cn/
https://gyqgaoxin.tiancebbs.cn/mayi-news.xml
https://dpbdxiasha.tiancebbs.cn/mayi-category.xml
https://dancheng.tiancebbs.cn/mayi-category.xml
https://ay.tiancebbs.cn/qths/503018.html
https://haining.tiancebbs.cn/mayi-news.xml
https://zhuzhou.tiancebbs.cn/mayi-news.xml
https://www.tiancebbs.cn/ershouwang/503226.html
https://aihuishou.tiancebbs.cn/sh/1257.html
https://www.tiancebbs.cn/ershoufang/499491.html
https://jj.tiancebbs.cn/qitafuwu/140654.html
https://aihuishou.tiancebbs.cn/sh/2529.html
https://su.tiancebbs.cn/hjzl/467159.html
https://aihuishou.tiancebbs.cn/sh/6966.html
https://bj.tiancebbs.cn/qths/54567.html
http://www.wukong-b2b.com/resume/12874/
https://kuixin.tiancebbs.cn/mayi-info.xml
https://qpxy.tiancebbs.cn/mayi-category.xml
https://www.tiancebbs.cn/ershoufang/503324.html
https://cq.tiancebbs.cn/qths/503751.html
https://aihuishou.tiancebbs.cn/sh/5858.html
https://gaoyaoqu.tiancebbs.cn/mayi-news.xml
https://xichuan.tiancebbs.cn/mayi-info.xml
https://aihuishou.tiancebbs.cn/sh/6876.html
https://hg.tiancebbs.cn/qths/504483.html
https://guoluo.tiancebbs.cn/mayi-info.xml
https://lf.tiancebbs.cn/qt/140645.html
https://shijingzhen.tiancebbs.cn/mayi-news.xml
https://aihuishou.tiancebbs.cn/sh/6000.html
http://www.wukong-b2b.com/job/search.php?areaid=25
https://longwanrongdong.tiancebbs.cn/
https://nd.tiancebbs.cn/qths/497159.html
https://zulin.tiancebbs.cn/sh/7480.html
https://www.tiancebbs.cn/ershouwang/502491.html
https://wengan.tiancebbs.cn/mayi-store.xml
https://tianningsierreshe.tiancebbs.cn/
https://haidingqubj.tiancebbs.cn/mjhs/201610.html
https://su.tiancebbs.cn/hjzl/474629.html
https://bxqshi.tiancebbs.cn/mayi-category.xml
https://dayao.tiancebbs.cn/mayi-info.xml
https://zy.tiancebbs.cn/qths/504207.html
https://zulin.tiancebbs.cn/sh/2170.html
https://sxyc.tiancebbs.cn/qths/502357.html
https://aihuishou.tiancebbs.cn/lsxqys/mayi-store.xml
https://cd.tiancebbs.cn/news/36663.html
https://cd.tiancebbs.cn/news/39678.html
https://zulin.tiancebbs.cn/sh/6736.html
https://sywugang.tiancebbs.cn/mayi-info.xml
https://taicang.tiancebbs.cn/hjzl/456898.html
https://zulin.tiancebbs.cn/sh/200.html
https://aihuishou.tiancebbs.cn/sh/3314.html
https://aihuishou.tiancebbs.cn/sh/3323.html
https://su.tiancebbs.cn/hjzl/460841.html
https://sh.tiancebbs.cn/hjzl/461351.html
https://www.tiancebbs.cn/qtfwxx/473273.html
https://aihuishou.tiancebbs.cn/sh/844.html
https://www.tiancebbs.cn/ershouwang/467657.html
https://zulin.tiancebbs.cn/sh/4537.html
https://zulin.tiancebbs.cn/sh/4408.html
https://www.tiancebbs.cn/ershouwang/470794.html
https://su.tiancebbs.cn/hjzl/469207.html
https://aihuishou.tiancebbs.cn/sh/1543.html
https://www.tiancebbs.cn/ershoufang/469391.html
https://zulin.tiancebbs.cn/sh/2226.html
https://zulin.tiancebbs.cn/sh/4174.html
https://muxiyuan.tiancebbs.cn/
https://guiyu.tiancebbs.cn/
https://fenlei.tiancebbs.cn/loudi/
http://ouyu.hftcbmw.cn/hgqza/
http://fuyang.tjtcbmw.cn/mjq/
https://bbqita.tiancebbs.cn/
https://fenlei.tiancebbs.cn/scpzr/
https://bulaotun.tiancebbs.cn/
http://js.sytcxxw.cn/qingyuan/
https://longzhuhuayuan.tiancebbs.cn/
http://jinqiang.ahtcbmw.cn/cqjb/
http://shenghuo.china-bbs.com/linyi/
https://honglan.tiancebbs.cn/qiandongnan/
http://yz.cqtcxxw.cn/qiye/
https://fenlei.tiancebbs.cn/rszp/
http://ruanwen.xztcxxw.cn/gxlz/
http://ruanwen.xztcxxw.cn/sjzpw/
https://www.tiancebbs.cn/ershoufang/474541.html
https://shaoyang.tiancebbs.cn/qths/464212.html
https://www.tiancebbs.cn/ershoufang/467380.html
https://ha.tiancebbs.cn/qths/451082.html
https://erds.tiancebbs.cn/qths/452001.html
https://su.tiancebbs.cn/hjzl/464824.html
https://www.tiancebbs.cn/ershoufang/472781.html
https://www.tiancebbs.cn/pgqz/53086.html
https://www.tiancebbs.cn/ershoufang/468865.html
https://taicang.tiancebbs.cn/hjzl/467408.html
https://zulin.tiancebbs.cn/aboutus/2.html
https://zulin.tiancebbs.cn/sh/3220.html
https://www.tiancebbs.cn/ershoufang/472980.html
https://www.tiancebbs.cn/qtfwxx/473331.html
https://yf.tiancebbs.cn/qths/468014.html
https://aihuishou.tiancebbs.cn/sh/983.html
https://zulin.tiancebbs.cn/sh/4923.html
https://guangning.tiancebbs.cn/qths/452636.html
https://aihuishou.tiancebbs.cn/sh/4358.html
https://gz.tiancebbs.cn/b2bxj/54731.html
https://changshushi.tiancebbs.cn/hjzl/458619.html
https://zulin.tiancebbs.cn/sh/2618.html
https://zulin.tiancebbs.cn/sh/4351.html
https://aihuishou.tiancebbs.cn/sh/274.html
https://www.tiancebbs.cn/ershoufang/468265.html
https://sh.tiancebbs.cn/hjzl/462753.html
https://changshushi.tiancebbs.cn/hjzl/462812.html
https://xwqbj.tiancebbs.cn/qihuotouzi/56169.html
https://www.tiancebbs.cn/ershoufang/468388.html
https://zulin.tiancebbs.cn/sh/4635.html
https://zulin.tiancebbs.cn/sh/2166.html
https://zulin.tiancebbs.cn/sh/2748.html
https://liangshan.tiancebbs.cn/qths/456367.html
https://changshushi.tiancebbs.cn/hjzl/462799.html
http://huaguang.jxtcbmw.cn/hnzzsa/
https://fenlei.tiancebbs.cn/qzq/
http://ouyu.hftcbmw.cn/guiyang/
http://jingren.hftcbmw.cn/wuxi/
https://haixing.tiancebbs.cn/
http://fuyang.tjtcbmw.cn/qdfw/
http://ly.shtcxxw.cn/daxinganling/
https://huaibeizhoubian.tiancebbs.cn/
https://pdxqmeiyuan.tiancebbs.cn/
http://km.lstcxxw.cn/shangqiu/
https://hrbwc.tiancebbs.cn/
http://nalei.zjtcbmw.cn/nwgzp/
http://cf.lstcxxw.cn/heihe/
http://ouyu.hftcbmw.cn/scls/
http://shenghuo.china-bbs.com/shshongjiang/
http://xinguang.sctcbmw.cn/wuhan/
http://shenghuo.china-bbs.com/jjqzw/
生涯人物访谈报告:https://www.nanss.com/xuexi/581.html 让人一看就赞的晚安说说:https://www.nanss.com/wenan/1099.html 网名大全情侣:https://www.nanss.com/mingcheng/1469.html 难过的词语:https://www.nanss.com/xuexi/530.html 恶魔猎手名字:https://www.nanss.com/mingcheng/1196.html 经典寓言故事:https://www.nanss.com/xuexi/879.html 励志短句致自己奋斗:https://www.nanss.com/xuexi/1300.html 大班下学期家长会发言稿:https://www.nanss.com/gongzuo/1161.html 期末复习计划:https://www.nanss.com/xuexi/706.html 英文求职信:https://www.nanss.com/gongzuo/866.html 满月酒答谢词:https://www.nanss.com/shenghuo/1121.html 气质网名:https://www.nanss.com/mingcheng/1209.html 微信伤感网名:https://www.nanss.com/mingcheng/881.html 女微信名字简单气质:https://www.nanss.com/mingcheng/753.html 打动女孩子的话:https://www.nanss.com/wenan/1039.html 超拽冷漠网名:https://www.nanss.com/mingcheng/610.html 昵称女生:https://www.nanss.com/mingcheng/1175.html 游戏情侣名字大全:https://www.nanss.com/mingcheng/1247.html 很好的句子:https://www.nanss.com/yulu/1052.html 儿女尽孝的短语:https://www.nanss.com/yulu/868.html 父母用很朴实的话鼓励孩子:https://www.nanss.com/yulu/999.html 失望的网名:https://www.nanss.com/mingcheng/674.html 一个人安静淡然句子:https://www.nanss.com/yulu/1307.html 我的成长之路普通话三分钟:https://www.nanss.com/xuexi/726.html 学生评价:https://www.nanss.com/gongzuo/521.html 相见恨晚的诗句:https://www.nanss.com/xuexi/851.html 送别短信:https://www.nanss.com/shenghuo/1326.html 王者荣耀游戏名字:https://www.nanss.com/mingcheng/953.html 抖音容易上热门的句子:https://www.nanss.com/wenan/1342.html 交友宣言:https://www.nanss.com/shenghuo/1032.html
 评论: 9
评论: 9
 浏览: 9104
浏览: 9104
