| PG查询引擎理论基础与实践 原作者:李浩 创作时间:2016-11-17 16:12:57+08 |
doudou586 发布于2016-11-17 12:59:57
 评论: 2 评论: 2
 浏览: 8767 浏览: 8767
|
PG查询引擎理论基础与实践
作者: 李浩
(1)介绍
对于查询优化大家可能都不陌生,大家都会有一个认识是:查询优化的工作就是从一堆可行的查询计划中,依据查询代价来选择一个查询代价最小的查询路径作为整个查询语句的最终的查询计划。但这里有一个问题就是:我们如何能够依据所给定查询语句来尽可能的构建出覆盖全面的查询计划,因为只有我们找出尽可能多的查询计划,进而才可能找出一个理论上的最优查询计划来。这些可能查询计划,在优化理论中有一个确切的定义:可行解空间。
而对于查询语句中所给出的关系表,称之为:问题空间。例如:对于 Select * from foo, bar where foo.col= bar.col这样的一条查询语句而言,其中的问题空间为 {foo,bar};并假设存在着两条可行的查询计划PlanA和PlanB,则我们称PlanA和PlanB为可行解空间。
查询优化器的任务就是在给定问题空间能,在所有的可行解空间内寻找到一个解使得该解的查询访问代价最小,根据如上的讨论,我们可以给出查询优化器的主要工作的形式化定义:
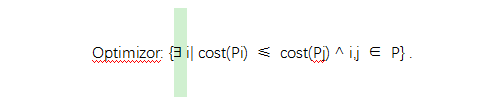
其中,P为我们的可行的解空间 ,cost()为我们查询代价计算函数。即:我们需要找所有的可行查询计划中内寻找到某一个计划,使得该查询计划所对应的查询代价小于其它所有的查询计划所对应的查询代价。如果我们能够找到该查询计划,那么我们将该查询计划称为最优查询计划。
此时,我们把对应上述问题的求解简化为一个组合优化问题,对于求解优化问题,我们有许多的工具,例如:动态规划问题以及当前所使用的由人工智能领域所提供的等新式工具,例如:遗传算法等等。
作为最早讨论最优查询计划的选择的论文,P.G. Selinger的 在《Access Path Select》一文中,作者重点讨论了System R中的最优查询路径的选择问题:单关系表和多表连接这两种情况下的查询访问路径的详细讨论。下面我们就首先介绍一下《Access Path Select》一文中的查询搜索树的构建,之后我们回过头来看看Postgres中有是如何进行最优访问路径寻优。通过,两者的对比发现,诸位读者会发现Postgres可以说是严格的依据《Access Path Select》一文中所给出的方法进行最优查询访问路径的寻优操作。可以毫不夸张的说该文是Postgres查询优化器的理论基础和实现的指导性准则。
在该文章中,作者指出:System R 系统中,在SQL语句中用户并不需要指定元组的访问模式。虽然现在看来,这个事情是理所当然的,但是在当时的情况下,却并不是一件容易的事情,在1974年IBM实验室也就是System R的诞生地发布一种结构化的查询语言,SEQUEL, structured English Query Language,而这也是SQL的前身。该结构化查询语句在后面的岁月里逐渐被大家认可并在1986年经过ANSI的标准化后成为关系数据库查询的语言标准。
当然在System R中,我们也无需指定连接的顺序,这些工作由System R来完成。System R会依据访问路径的代价来选择一个最优的访问方式。而这个基于代价的最优访问路径的模型也渐渐的成为后续关系数据库在查询优化中的既定标准。不同的关系数据库的代价模型在实现过程中也存在着千差万别的不同,但是其基本思想是一致的。
System R在接收到查询语句后,在完成对于其词法和语法的检查,在查询语句不存在任何错误的时候,System R会将From-List中所提及的关系表进行连接运算的排列组合,并依据各关系表的统计信息对这些排列组合求解其查询访问代价。而这也就是后续各个关系数据库在查询优化中所采用的求解方法。在完成最优查询访问路径的求解后,System R将创建执行计划,Access Specification Language, ASL。对于该文中所描述执行计划的创建的过程以及对于存储系统(Research Storage System, RSS)相关概念的讨论,在这里我们就不在详细给出,还请诸位读者参考原文。
单表的查询访问代价计算
其中, PAGE_FETCHES为所获取元组数量;W为I/O和CPU代价之间的权重比例;RSI_CALL为满足谓词条件的元组数量。这里由于System R中CPU时间主要是涉及到的RSI(Research Storage Interface)调用的时间,因此我们使用满足谓词条件的元组数量来标识。
当然在执行的过程中,我们所执行的扫描操作所返回给用户的元组必须满足WHERE子句中的谓词语句。当然,索引扫描时,同样所返回的元组也必须满足索引中所给出的谓词条件。
在System R的优化器执行的过程中,系统会由元数据表中来查询相关关系表的统计信息。这些统计信息主要有如下几个来源:(1)关系表的初始加载阶段;(2)索引创建时;而这些统计信息后由用户执行UPDATE STATISTICS命令来更新相关的统计信息。在System R中,当用户执行相关的INSERT,DELETE,UPDATE命令时,系统并不会更新相关的统计信息,而这点与我们现在的数据系统有所不同。因为,在System R中考虑到我们在更新统计信息时候,会存在着一些锁操作,而这些锁操作又会进一步的造成系统的性能下降。
同样在System R中给出了不同形式的谓词表达式的选择率计算公式,在这里我们就不给出详尽的解释了,我们将会在另外的文章中给出一个详尽的讨论。下面就介绍一下本文讨论的重点:查询访问路径候选解的构建。
连接的查询访问路径
1976年,Blasgen和Eswaran在测试了在不同维度下的一系列的2-way连接操作后,结果表明:对于那些较小关系表来说,总是存在着一般的连接方法是属于最优或者是次优的。在System R中会使用该方法并将其扩展到N-way连接。
我们将在连接操作中被首先获取元组的表,称之为:外表;而将另外一个依赖外表元组的称为:内表。而将描述内外表之间的连接关系,称之为:连接谓词。而将连接谓词中所涉及的列,称之为:连接列。
第一个连接方法为:嵌套循环连接,Nested Loops。首先,由外表中获取一条元组,然后扫描内表并查找出内表中的元组,使得该元组与外表元组满足连接谓词。
第二种连接方法为:归并扫描,将内外表以连接列为基础,对该列中的数据进行排序,而后将外表与内表中的元组进行连接谓词的判定。归并扫描的方式,使用于连接谓词为:等式表达式。
基于上述的两路连接操作,我们可以构建一个N路的连接操作。
当查询语句的FROM子句中存在着n个数量的关系表,则可以构成n的指数数量的不同连接顺序(通过对这些关系进行排列组合的方式来构成不同顺序的连接操作)。当然,对于这些可行连接的搜索空间可以通过一定的方法进行缩减。例如:当我们已经完成了前K个关系表的连接操作后,那么第k+1个关系表所构成的连接关系与前K个关系表的连接顺序无关。而这也是我们进行高效的最优查询访问路径的查找的理论出发点。
System R中采用一种启发式算法来减少我们所需要考虑的连接顺序的搜索空间。我们仅仅考虑的连接顺序是:内表上存在着与已经构成连接关系存在着由连接谓词所描述的连接关系。例如:在连接关系 T1,T2,…, Tn中,我们仅仅考虑:连接关系Ti1,Ti2,…,Tin,当对于所有的j (j=2,…,n)
例如:对于T1,T2,T3的关系表,在T1与T2;T2和T3之间存在着不同的连接谓词约束(在不同的连接列至少)。那么下面的连接操作我们将不会进行考虑。T1-T3-T2和T3-T1-T2。对于第一中情况,由于T1与T3之间并不存在着连接关系约束,因此该种连接数顺序不会被考虑;同理,我们也不会考虑第二种情况。
对于 T1, T2, T3,共有如下的连接可能: T1- T2- T3 ; T1- T3- T2; T2- T1- T3 ; T2- T3- T1 ; T3- T1- T2; T3- T2- T1;
下面我们就对各种情况进行分析:
System R通过构建一棵查询搜索树并以该查询树为基础并结合代价信息进行最优查询访问的计算。而这棵查询搜索树,完整的表现了我们查询搜索空间内的所有可行解。该查询搜索树是在已完成连接的关系表的数量的基础之上进行迭代构建而成。
首先,最优查询访问路径是以单个关系表构成开始;接下来,以此为基础,计算其它基表与以建立连接关系的基表之间的最优查询访问路径;之后,我们计算包含三个关系表的连接操作集合。如此,从而获得最终的查询访问路径。例如:通过计算上述的所有包含两个基表的连接操作集合与第三个基表之间的连接操作,我们可以得到包含三个基表的连接关系。例如:对于T1,T2,T3。首先我们现在计算只含有一个基表关系的:T1, T2, T3;之后,我们获得包含两个基表的连接关系(T1,T2),(T1,T3), (T2,T3),(T3,T1);在以上述包含两个基表连接操作集合为基础构建包含三个基表连接操作的集合(T1,T2,T3)…。下面我们就以实例来介绍查询搜索树的构建过程。例如:存在着如下的查询语句:
其中EMP: 有 NAME, DNO, JOB, SAL三列;DEPT: DNO, DNAME, LOC三列;JOB: JOB, TITLE两列;
相关最优路径的构建过程如下:
(1)首先,计算单个表的最优路径。
对于EMP表来说,其有三类访问路径:DNO列上的索引访问, JOB列上的索引访问,以及全表访问。 相应的顺序是:DNO,JOB。在DNO上的索引提供了对于DNO的排序方式,而对于JOB上的索引则提供了对于JOB的排序方式。 而对于EMP的全部扫描则提供了未排序访问方式。
对于DEP表,我们有两类访问路径:索引访问和全部扫描。 在 DNO上的索引扫描路径和全部扫描路径。
对于JOB表,有两类访问路径:索引访问路径和全部扫描,在JOB上的索引扫描路径以及全部扫描路径。下图为单个基表的查询搜索树形式。
其中的index为索引扫描操作,segment scan为顺序扫描操作。在求解完所有的单表情况后;(2)接下来,我们考虑:多表连接;即将单个基表依据连接关系,将其连接到其它基表上。如图二所示。寻找的原则是:第二个基表与第一个基表之间存在着连接谓词约束。本例中, EMP-JOB连接是最优连接,因为我们通过JOB表上的JOB进行索引扫描。对于EMP与DEP关系的连接,我们假设DNO索引扫描是最优路径。因此,对于两个表的连接路径情况如下图所示。
采用相同的方式我们可以给出包含三个基表关系的查询搜索树,这里不在给出,还请参考原文。EMP , DEP , JOB可以构成的有效路径,即候选解如下:
(EMP.DNO=DEP.DNO and EMP.JOB= JOB.JOB):
(1)EMP-DEP-JOB (OK);(2)EMP-JOB-DEP (OK);(3)DEP-EMP-JOB (OK);(4)DEP-JOB-EMP (Bad, Pruned);(5)JOB-EMP-DEP (OK);(6)JOB-DEP-EMP (Bad, Pruned)。其中OK表示是可以构成的合法路径,而Bad则表示非法路径,需要被删除。
此时,这里可能有些读者会立刻明白,上述所讨论的方法与是我们在PostgreSQL查询引擎中所看到的查询优化时所使用的动态规划算法相同吗?没错,无论是Postgres还是其他的商业数据库都是以该文章为基础来构建最优查询路径的寻优。可以毫不夸张的说改文章是其它后续数据库查询引擎的基石。下面我们就以Postgres为实际案例,通过对于Postgres中的实现来验证上述文章。
下面我们以为示例来介绍Postgres中关于查询搜索树的构建相关源码,而这部分功能是整个Postgres查询引擎的关键。一个尽可能覆盖所有候选搜索空间的查询引擎将有助于我们获得理论上的最优查询访问路径。并且查询搜索空间与查询语句所涉及到的基表数量成指数关系。因此,高效同样也作为查询引擎所追求的另外一个目标。
在上述例句经过查询子查询和子连接的处理后,我们将得到一个查询语句中所涉及的基表关系列表。我们将以此为基础在该列表上构建查询搜索树。
make_rel_from_joinlist函数,构建相应的连接关系。该函数的实现,正是以上述Selinger的上述论文为基础来构建:动态规划算法--- standard_join_search。
join_search_one_level函数作为standard_join_search函数中处理在动态规划算法中的任意一层的函数,即上述文章中所讨论:单个表连接关系,两表连接关系,三表连接关系等等。
在该函数中other_rels变量描述了当前所要计算的层级的上一层层级关系表列表,即如果当前所要计算的层级为level,则other_rels为level-1层级。
对于上述的查询语句,第一层级中的关系列表如下(注意与图三之间的区别):
因此在函数standard_join_search中,我们首先计算:sc与class是否能够构成连接关系。由于sc与class之上均存着连接约束,但是sc与class之间不存在着任何的连接约束条件。因此,sc和class之间不能够构成合法的连接关系,而这判断条件正是由上述论文中所提及到的内容所描述;接下来计算 sc 与 student之间的连接关系。
这里由于sc 与student之间并不存在着直接的连接关系(joinclause,rel->join_list中所描述的内容,因此我们需要检查 EM对象中是否存在着相关的连接关系(或者连接约束))。此时,由于存在着sc.sno in (select sno from student ...) 这样的约束关系。因此{sc, student}以进行构成连接关系处理,即论文中所提及的有效候选集的情况。
当所给定的两个基表之间可以构成连接关系的可能时,由make_join_rel函数进行真正的连接关系建立工作(即:给定两个基表,首先进行连接合法性判定,当合法时,构建一个新的连接关系,即上述论文中在动态规划算法中的每一层级中所构建的连接关系具体计算实现)。当然这里还由 join_is_legal来判定该连接的合法性进行判断。如果这两个关系表不能构成合法的连接关系,即使其存在着相应的 EC对象(即等式关系。例如sc.sno = student.sno 这样的等式约束条件)。
在 join_is_legal 函数中不但要判定相应的连接关系是否合法,同样需要确定相应的连接类型和连接顺序。例如:{sc, student} nest-loop, 或者是{student, sc} nest-loop这样的形式。
在 join_is_legal中首先会检查现有的所有的外链接关系。因为,该外连接关系已然决定了两表间的连接顺序,例如: sc Left join student,那么我们就不能构成student Left join sc的连接。
我们所给出的测试基表并不总是能满足与已有的外连接关系。例如下图所示:所给定基表与现有的连接关系无关或者是所给定关系表只是外连接关系中的一部分,此时我们无法将所给定的基表构成连接关系。
除此之为,当我们找到一个外连接约束,其包含了我们所给定的需要参与连接计算基表关系;若之前并不存在着这样的关系时,而且我们所给定的连接关系中已然包含了现有的外连接关系,则所给定的基表可以构成一个合法的连接。例如:{T1, T2}和T3,如果存在着T2和T3之间已然存在着外连接关系时,则{T1,T2}和T3也可以构造一个合法的连接关系。我们本例中的测试基表为sc ,student,如果当前存在着连接关系sc in (select sno from student) 则,sc 和student则可以构成一个合法的连接关系, 且两基表在连接关系中的位置不需进行交互。否则,交互两基表之间的位置。下述代码描述了以上的讨论。
更进一步,当我们的外连接关系为SEMI-JOIN时候,我们需要进一步的测试:连接关系上的right hand上的是否可以使用uniq-path方式进行处理,因为此种方式有助于我们更加快速的完成连接。
同样,除了需要检查的外链接关系外,我们还需检查lateral 形式的连接关系。当检查完这些所有的关系后,我们完成对于所给定的两个基表之间能否构成合法的连接关系检查。
当两者是可以构成合法的连接关系,但在两基表之上并未外连接约束条件时,我们为这两关系表构建 JOIN_INNER型连接关系。build_join_rel函数依据上述连接顺序和连接类型等信息构建基表间的连接关系并将构建好的连接关系添加到root-> join_rel_list中。
这里还请读者仔细体会这些输入参数的含义。
此时,我们就完成了给定两个基表,构建其连接关系的计算。而这正是我们make_join_rel函数的基础:给定两个基表构建可能的连接关系。
函数add_paths_to_joinrel完成将已确定连接关系的两基表构建其所有可能的访问路径。 这正是后续的求解最优访问路径的基础。
到这里,我们就完成了动态规划算法中某一层中的两个基表连接关系的求解并对其中相关参数进行了设置。当完成上述求解后,下面我们还需要计算busy连接方式。在每层中还需要考虑busy plan的情况。由于我们是处于第2层,因为并不会构成所谓的busy连接方式。
完成第2层级的连接关系计算后的情形如上图。然后开始计算第三层的连接关系,使用第二层已经计算好的连接关系与第一层进行计算。
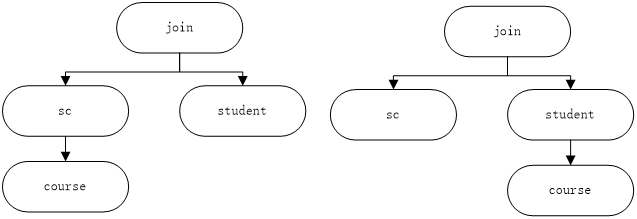
首先计算{sc, student} 与 sc直接的关系,由于sc已经存在与连接关系中,因此对于这样的情况我们将不会进行后续处理。此时,进行下一个关系表的处理。 {sc, student}与class 之间是否可以构成连接关系。
由于 {sc, student}与class之间并不会存在着相应的任何约束条件,因此我们无法将 {sc, student}与class之间形成连接关系。此时,我们进行将{sc, student}与student进行相应的判定。同理,由于我们已经将sc与student之间构成了连接关系。此时,对于第2层计算时的student,同样无需进行处理。在我们计算 {sc, student} 与course的时候,由于sc与course之间存在这 sc.cno in (select cno from course...) 这样的连接约束关系。 因此,我们将 {sc, student} 与course构成一个新的连接关系,{sc, student, course}。
这样我们处理完第二层中的第一个元素 {sc, student}, 接下来处理该层的第二个有效元素 {sc, course}。其处理的流程同样如上述,这里我们就不在详细给出分析,而是直接给出相应的连接后的结果。
需要诸位读者注意的是:上述这些操作,均是在该基表之上存在着约束关系的时候,无论是基表关系上的约束关系亦或是RELATION_JOIN类型基表之上的约束关系。而当这些基表之上不存在着约束关系的时候,说明这些基表本身就不会与任何的其它基表发生约束性连接关系,故而我们使用的是笛卡尔积的方式来进行连接构成 --- make_rels_by_clauseless_joins 实现笛卡尔乘积的连接方式。
{sc, course}与sc,由于sc已然存在与连接关系中,故而此处操作属于无效。继续进行下一候选值,class的计算。 {sc, course} 与class,从查询语句中可以看出其并未与任何{sc, course}中的基表发生任何的关联。因此,{sc, course}与class属于无效连接。而这也是Selinger在论文中明确指出的。 同理,{sc, course}与student之间存在着: sc与student的连接关系,sc与course之间的连接。因此,{sc, course}与student可以构成合法的连接关系。最后,{sc, course}与course这属于不需进行在进行连接计算的。
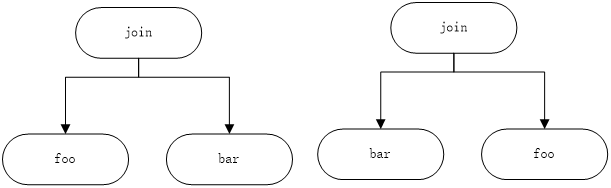
在进行第三层的计算时候,我们需要计算{sc, student} 和course 或者 {sc, course}和student之间可能的busy连接。因为,此时有足够数量的基表,可以进行busy plan计算。而两个基表是无法进行busy连接的计算的。
例如:foo 和bar,无论我们怎么组合,我们都只能得到如下的形式:
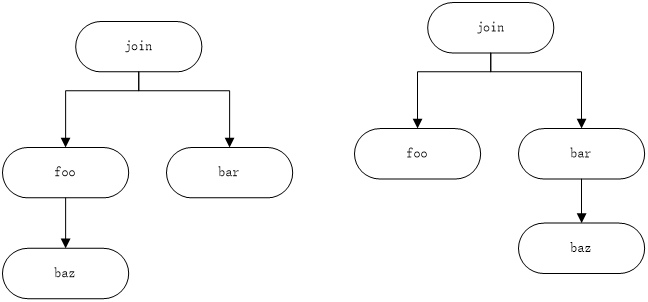
而对于 foo, bar, baz可可以形成如下的形式。对于具有的求解busy plan这里我们不进行展开讨论,因为我们的重点不在这里,留给读者思考。
第三层计算时候的busy plan形式
同理,我们可以给出第四层的计算结果
当我们将所有的基表都已处理完成后,完成对于基表的动态规划算法求解过程。 并在每次产生的连接关系时,创建其对于的查询访问路径,并记录下最优查询访问路径,当我们完成对于所有基表的处理后,我们将获得一个最优的查询访问路径。而这些本论文中所给出的讨论内容。 该方法均被后续的关系数据库查询引擎中大量使用。
由上述对于Selinger论文的简单讨论和Postgres所给出的实现代码,我们可以看出:作为该论文在查询优化器上的实现,Postgres完整而忠实的实现了Selinger论文中所提及的相关操作。我们从Postgres查询引擎的实现源码中可以看出,其所采用的动态规划算法以及基于代价的查询优化均与这篇论文相同。
同时,从当今众多的数据库的查询引擎可以看出,这些查询引擎均受到该篇论文的影响,无论是从设计理念还是实现细节方面。因此,仔细的研读Selinger的这篇论文对于理解查询引擎有着非常重要的意义,推荐想深入了解查询引擎的相关人员阅读。
(2)《Access Path Select》一文介绍
SELECT NAME, TITLE, SAL, DNAME
FROM EMP, DEPT, JOB
WHERE TITLE=‘CLERK’
AND LOCYDENVER
AND EMP.DNO=DEPT.DNO
AND EMP.JOB=JOB.JOB
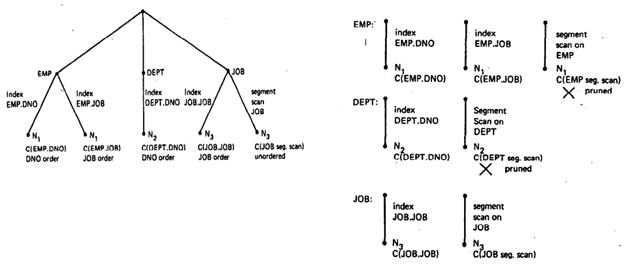
图一:单个基表的查询搜索树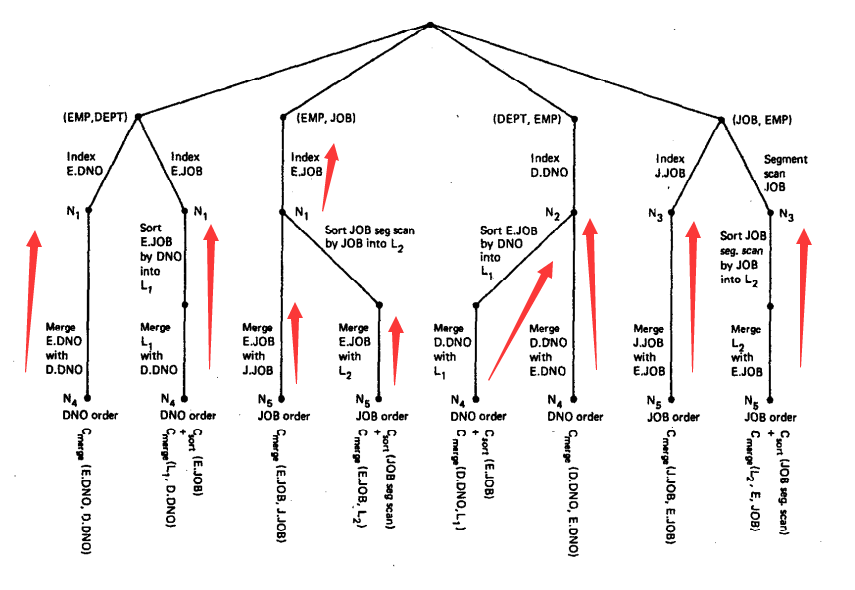
图二:含有两个基表关系的查询搜索树(3)PostgreSQL实现介绍
SELECT classno, classname, avg(score) as avg_score
FROM sc, (SELECT * FROM class WHERE class.gno='grade one') as sub
WHERE sc.sno in (SELECT sno FROM student WHERE student.classno=sub.classno) and sc.cno in (select course.cno from course where course.cname='computer')
….

图三:基表关系列表
图四:第一层级中关系列表
RelOptInfo *old_rel = (RelOptInfo *) lfirst(r);
if (old_rel->joininfo != NIL || old_rel->has_eclass_joins ||
has_join_restriction(root, old_rel))
{ //如果关系表上存在着约束条件,且两个关系表存在着直接的连接关系,则求解
…
make_rels_by_clause_joins (…) ;
…
} else {
//采用笛卡尔乘积的方式来构成连接关系
}
if (!bms_overlap(old_rel->relids, other_rel->relids) &&
(have_relevant_joinclause(root, old_rel, other_rel) ||
have_join_order_restriction(root, old_rel, other_rel))) //判定两个关系是否存在着直接或者间接的连接关系。
{
(void) make_join_rel (root, old_rel, other_rel);
}
foreach(l, root->join_info_list)
{
SpecialJoinInfo *sjinfo = (SpecialJoinInfo *) lfirst(l);
…// 判定该连接是否能够构成合法的连接并确定连接顺序和连接类型
}

图五:给定关系为已有外连接的一部分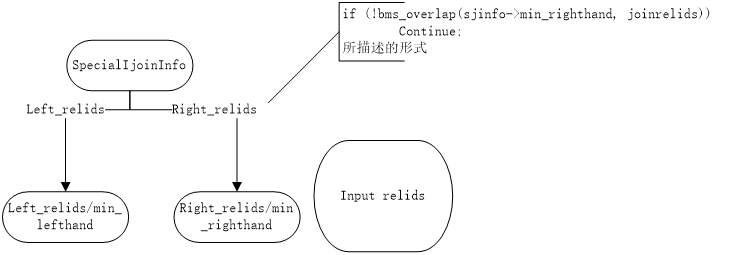
图六:所给定的关系表与已有的外连接无任何关联
if (bms_is_subset(sjinfo->min_lefthand, rel1->relids) &&
bms_is_subset(sjinfo->min_righthand, rel2->relids))
{
if (match_sjinfo)
return false; /* invalid join path */
match_sjinfo = sjinfo;
reversed = false;
}
else if (bms_is_subset(sjinfo->min_lefthand, rel2->relids) &&
bms_is_subset(sjinfo->min_righthand, rel1->relids))
{
if (match_sjinfo)
return false; /* invalid join path */
match_sjinfo = sjinfo;
reversed = true;
}
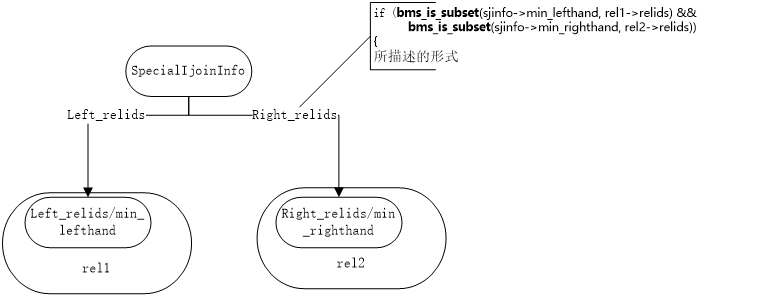
图七:给定基表满足与外连接的包含条件
RelOptInfo *
build_join_rel(PlannerInfo *root,
Relids joinrelids,
RelOptInfo *outer_rel,
RelOptInfo *inner_rel,
SpecialJoinInfo *sjinfo,
List **restrictlist_ptr)
{
…
}
joinrel = makeNode(RelOptInfo);
joinrel->reloptkind = RELOPT_JOINREL;
...
root->join_rel_list = lappend(root->join_rel_list, joinrel);
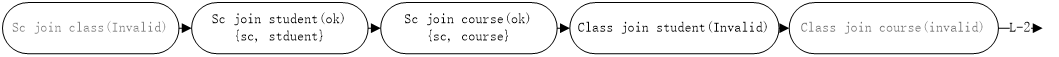
图八:第二层级基表关系
图九:第二层级基表关系之{sc, student}处理
图十:第二层级基表关系之{sc, course}处理

(4)总结

请在登录后发表评论,否则无法保存。
