实时数据交换平台 - BottledWater-pg with confluent
作者: digoal
日期: 2016-12-05
标签: PostgreSQL , Bottled Water , Kafka , Confluent , IoT
背景
想必大家都在图书馆借过书,小时候有好看的书也会在小伙伴之间传阅。
借书和数据泵有点类似,一份数据通过数据泵实时的分享给订阅者。
例如在IoT的场景中,有流式分析的需求,也有存储历史数据的需求,同时还有数据挖掘的需求,搜索引擎可能也需要同一份数据,还有一些业务可能也要用到同一份数据。
但是如果把数据统统放到一个地方,这么多的业务,它们有的要求实时处理,有的要求批量处理,有的可能需要实时的更新数据,有的可能要对大数据进行分析。
显然一个产品可能无法满足这么多的需求。就好比数据库就分了关系数据库,NOSQL,OLTP场景,OLAP场景一样。 也是因为一个产品无法满足所有的业务需求。
在企业中通常是借助数据冗余来解决各类场景的需求。
那么如何才能够更好的分享数据,保证数据的一致性,提高分享的实时性呢?
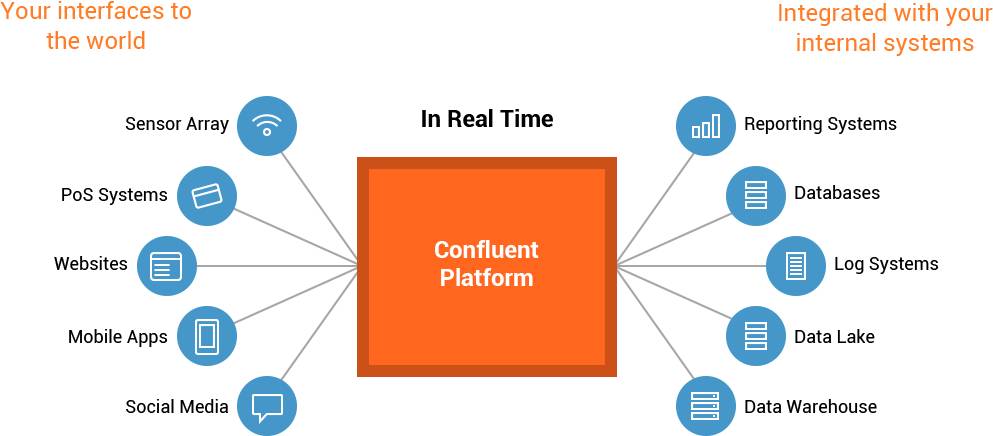
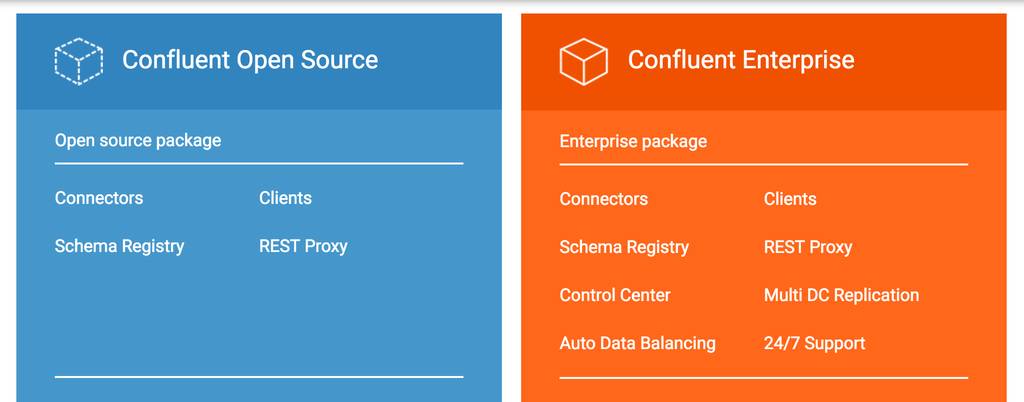
confluent platform
http://docs.confluent.io/3.1.0/platform.html
confluent 是一个实时的数据中转服务,来自各个平台的数据可以使用confluent进行流转,达到分享和交换数据的目的。
例如来自物联网传感器的数据,来自数据库的数据,来自HTTP,移动APP的数据,来自应用日志的数据,来自一些事件触发的数据 等等。
confluent需要依赖一些基本的组件,核心组件如kafka.
用户可以自定义消息的生产者和消费者,在confluent提供的平台上交换数据。
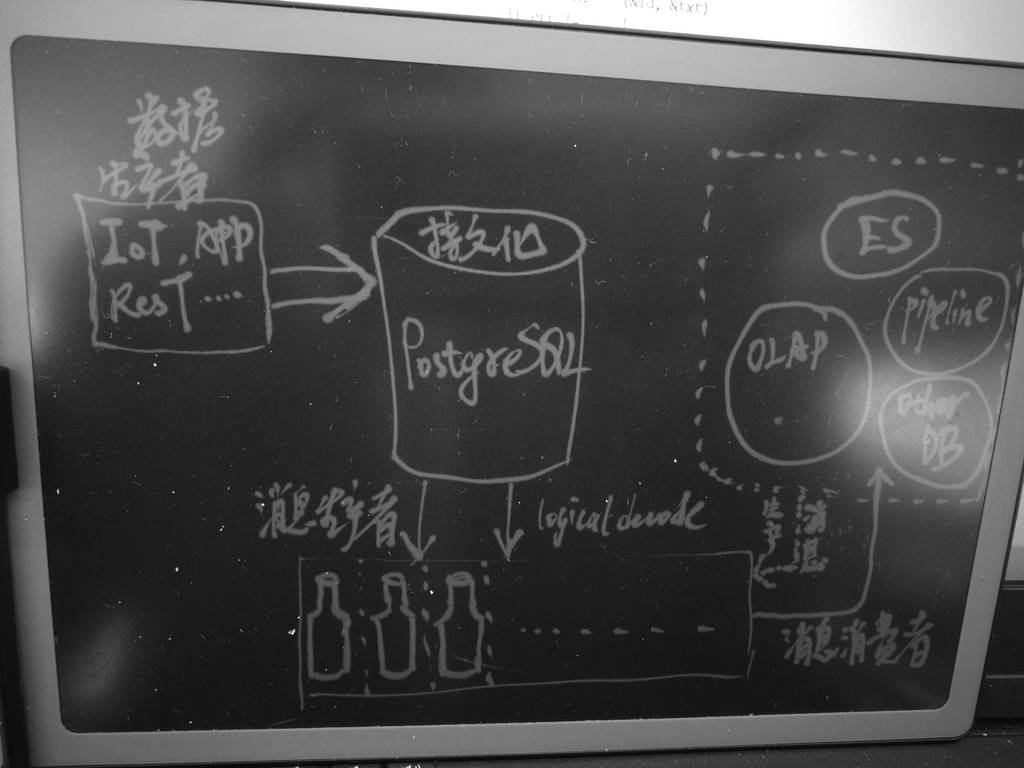
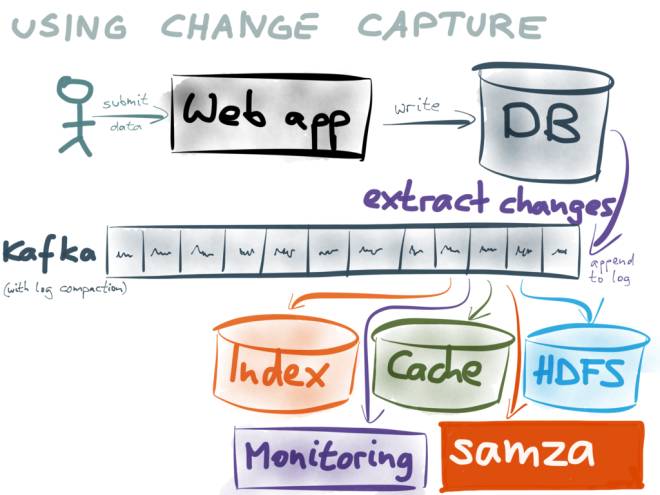
BottledWater-pg
bottledwater-pg是confluent平台的一种消息生产者,针对PostgreSQL数据库,即将PostgreSQL数据库的数据写入confluent Kafka,从而实时的分享给消息订阅者。
支持PostgreSQL 9.4以及以上版本,支持全量快照,以及持续的增量数据写入Kafka。
bottledwater-pg使用PostgreSQL快照技术,可以读取一致性的快照写入Kafka。使用数据库logical decode技术,从PostgreSQL的WAL日志中,解析为ROW数据写入Kafka。
在Kafka中,每个topic代表一张数据库的表。
数据在使用decode从WAL取出后,写入Kafka之前,使用Avro将数据ROW打包成JSON, or Protobuf, or Thrift, or any number of formats,再写入Kafka。
Avro支持的数据类型比较丰富,可以很好的支撑PostgreSQL丰富的数据类型。
为什么使用Avro请参考? http://radar.oreilly.com/2014/11/the-problem-of-managing-schemas.html
BottledWater-pg依赖环境
BottledWater-pg是PG的一个插件,它的目的是解析WAL,同时使用Avro封装为json/Protobuf/Thrift/其他formats。 并写入Kafka。
因此它依赖这些库或软件
PostgreSQL 9.4+ development libraries (PGXS and libpq). (Homebrew: brew install postgresql;
Ubuntu: sudo apt-get install postgresql-server-dev-9.5 libpq-dev)
libsnappy, a dependency of Avro. (Homebrew: brew install snappy;
Ubuntu: sudo apt-get install libsnappy-dev)
avro-c (1.8.0 or later), the C implementation of Avro. (Homebrew: brew install avro-c;
others: build from source)
Jansson, a JSON parser. (Homebrew: brew install jansson; Ubuntu: sudo apt-get install libjansson-dev)
libcurl, a HTTP client. (Homebrew: brew install curl; Ubuntu: sudo apt-get install libcurl4-openssl-dev)
librdkafka (0.9.1 or later), a Kafka client. (Ubuntu universe: sudo apt-get install librdkafka-dev,
but see known gotchas; others: build from source)
部署BottledWater-pg
gcc,cmake
最好部署较新版本的,否则可能会有编译问题。
gcc 6.2.0
python 2.7.12
cmake 3.6.3
vi /etc/ld.so.conf
/home/digoal/gcc6.2.0/lib
/home/digoal/gcc6.2.0/lib64
/home/digoal/python2.7.12/lib
ldconfig
export LD_LIBRARY_PATH=/home/digoal/gcc6.2.0/lib:/home/digoal/gcc6.2.0/lib64:
/home/digoal/python2.7.12/lib:$LD_LIBRARY_PATH
export PATH=/home/digoal/gcc6.2.0/bin:/home/digoal/python2.7.12/bin:
/home/digoal/cmake3.6.3/bin:$PGHOME/bin:$PATH:.
snappy
可选,一种比较高效的压缩和解压缩库。
由于avro还支持xz,可不安装snappy
/*
snappy
http://google.github.io/snappy/
wget https://github.com/google/snappy/archive/1.1.3.tar.gz
tar -zxvf 1.1.3.tar.gz
cd snappy-1.1.3
yum install -y libtool gcc-c++
./autogen.sh
./configure --prefix=/home/digoal/snappy_home
make
make install
- add LIBDIR to the `LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the `LD_RUN_PATH' environment variable
during linking
- use the `-Wl,-rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to `/etc/ld.so.conf'
*/
libjansson (libjansson >=2.3)
json parser,必须安装,建议测试时安装在默认目录,否则可能遇到编译问题,或者设置rpath。
http://www.digip.org/jansson/
wget http://www.digip.org/jansson/releases/jansson-2.9.tar.bz2
tar -jxvf jansson-2.9.tar.bz2
cd jansson-2.9
./configure --prefix=/home/digoal/jansson
make
make install
- add LIBDIR to the 'LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the 'LD_RUN_PATH' environment variable
during linking
- use the '-Wl,-rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to '/etc/ld.so.conf'
export PKG_CONFIG_PATH=/home/digoal/jansson/lib/pkgconfig:$PKG_CONFIG_PATH
pkg-config --cflags --libs jansson
-I/home/digoal/jansson/include -L/home/digoal/jansson//home/digoal/jansson/lib -ljansson
建议测试时安装在默认路径中,如下。
./configure
make
make install
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
liblzma
yum install -y xz-*
boost
可以不装,如果你要安装Avro的doc时才需要安装boost。
/*
boost
http://www.boost.org/
https://sourceforge.net/projects/boost/files/boost/1.62.0/
wget http://downloads.sourceforge.net/project/boost/boost/1.62.0/boost_1_62_0.tar.bz2
?r=https%3A%2F%2Fsourceforge.net%2Fprojects%2Fboost%2Ffiles%2Fboost%2F1.62.0%2F
&ts=1480929211&use_mirror=ncu
tar -jxvf boost_1_62_0.tar.bz2
cd boost_1_62_0/libs/regex/build
如果要使用静态库,请执行make -fgcc.mak
如果要使用静态库,请执行make -fgcc-shared.mak
ll gcc
drwxr-xr-x 2 digoal users 4.0K Dec 5 17:18 boost_regex-gcc-1_53
drwxr-xr-x 2 digoal users 4.0K Dec 5 17:17 boost_regex-gcc-1_53_shared
drwxr-xr-x 2 digoal users 4.0K Dec 5 17:19 boost_regex-gcc-d-1_53
drwxr-xr-x 2 digoal users 4.0K Dec 5 17:18 boost_regex-gcc-d-1_53_shared
-rw-r--r-- 1 digoal users 2.6M Dec 5 17:18 libboost_regex-gcc-1_53.a
-rwxr-xr-x 1 digoal users 1.3M Dec 5 17:17 libboost_regex-gcc-1_53.so
-rw-r--r-- 1 digoal users 17M Dec 5 17:19 libboost_regex-gcc-d-1_53.a
-rwxr-xr-x 1 digoal users 7.4M Dec 5 17:18 libboost_regex-gcc-d-1_53.so
libboost_regex-gcc-1_53.a , 这是release版的静态库
libboost_regex-gcc-1_53.so , 这是release版的动态库(共享库)
libboost_regex-gcc-d-1_53.a , 这是debug版的静态库
libboost_regex-gcc-d-1_53.so , 这里debug版的动态库(共享库)
*/
avro (1.8.0 or later)
http://avro.apache.org/
http://www.apache.org/dyn/closer.cgi/avro/
wget http://mirrors.hust.edu.cn/apache/avro/avro-1.8.1/avro-src-1.8.1.tar.gz
tar -zxvf avro-src-1.8.1.tar.gz
cd avro-src-1.8.1/lang/c
mkdir build
cd build
/*
cmake .. -DCMAKE_INSTALL_PREFIX=/home/digoal/avro -DCMAKE_BUILD_TYPE=Release
-DSNAPPY_LIBRARIES=/home/digoal/snappy_home/lib
-DSNAPPY_INCLUDE_DIR=/home/digoal/snappy_home/include
*/
yum install -y zlib-devel.x86_64
cmake .. -DCMAKE_INSTALL_PREFIX=/home/digoal/avro -DCMAKE_BUILD_TYPE=Release -DTHREADSAFE=true
make
make test
make install
The "RelWithDebInfo" build type will build an optimized copy of the
library, including debugging symbols. Use the "Release" build type if
you don't want debugging symbols. Use the "Debug" build type if you
want a non-optimized library, with debugging symbols.
On Unix, you can request thread-safe versions of the Avro library's
global functions by defining the THREADSAFE cmake variable. Just add
the following to your cmake invokation:
-DTHREADSAFE=true
libcurl
yum install -y libcurl-devel.x86_64
librdkafka
git clone https://github.com/edenhill/librdkafka
/*
./configure --prefix=/home/digoal/librdkafka_home
make -j 32
make install
export PKG_CONFIG_PATH=/home/digoal/avro/lib/pkgconfig:
/home/digoal/librdkafka_home/lib/pkgconfig:
/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
*/
测试时建议按照在默认目录,否则可能又会有编译错误的问题。
./configure
make
make install
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
PostgreSQL
安装略
bottledwater-pg
由于bottledwater-pg是PostgreSQL的一个插件,所以首先要安装PostgreSQL。
git clone https://github.com/confluentinc/bottledwater-pg
cd bottledwater-pg
make
make install
vi /etc/ld.so.conf
/home/digoal/avro/lib
or
export LD_LIBRARY_PATH=/home/digoal/avro/lib:$LD_LIBRARY_PATH
可能需要重启数据库,加载bottledwater.so
在数据库中创建插件
psql
postgres=# create extension bottledwater ;
CREATE EXTENSION
部署confluent platform
这一步是基础,搭建好confluent,后面才能测试一下bottledwater-pg生产消息,以及从confluent platform消费消息的过程。
http://docs.confluent.io/3.1.0/installation.html
部署PostgreSQL流复制
bottledwater-pg需要从wal解析logical row,所以必须配置WAL_LEVEL=logical级别。
同时wal sender进程数必须>=1。
worker process数必须>=1。
同时由于bottledwater为了保证可以支持断点续传,以及确保没有转换的WAL日志不会被主库删掉或覆盖掉,需要用到replication slot,因此需要配置replication_slots>=1。
postgresql.conf
max_worker_processes = 8
wal_level = logical
max_wal_senders = 8
wal_keep_segments = 256
max_replication_slots = 4
同时为了保证数据库的WAL订阅者可以通过流复制协议连接到数据库,需要配置pg_hba.conf
pg_hba.conf
local replication digoal trust
host replication digoal 127.0.0.1/32 trust
host replication digoal 0.0.0.0/0 md5
创建replication角色用户
create role digoal login replication encrypted password 'digoal123';
使用bottledwater-pg生产消息
bottledwater-pg客户端命令的目的是从WAL解析日志,写入Kafka。
command option需要配置如何连接到数据库(使用流复制连接),output格式,topic-prefix(建议为库名),是否需要初始化快照,是否允许没有主键的表,kafka broker的连接地址和端口,schema-registry的连接地址和端口。以及一些kafka相关的配置。
cd bottledwater-pg/kafka
./bottledwater --help
Exports a snapshot of a PostgreSQL database, followed by a stream of changes,
and sends the data to a Kafka cluster.
Usage:
./bottledwater [OPTION]...
Options:
-d, --postgres=postgres://user:pass@host:port/dbname (required)
Connection string or URI of the PostgreSQL server.
-s, --slot=slotname Name of replication slot (default: bottledwater)
The slot is automatically created on first use.
-b, --broker=host1[:port1],host2[:port2]... (default: localhost:9092)
Comma-separated list of Kafka broker hosts/ports.
-r, --schema-registry=http://hostname:port (default: http://localhost:8081)
URL of the service where Avro schemas are registered.
Used only for --output-format=avro.
Omit when --output-format=json.
-f, --output-format=[avro|json] (default: avro)
How to encode the messages for writing to Kafka.
-u, --allow-unkeyed Allow export of tables that don't have a primary key.
This is disallowed by default, because updates and
deletes need a primary key to identify their row.
-p, --topic-prefix=prefix
String to prepend to all topic names.
e.g. with --topic-prefix=postgres, updates from table
'users' will be written to topic 'postgres.users'.
-e, --on-error=[log|exit] (default: exit)
What to do in case of a transient error, such as
failure to publish to Kafka.
-x, --skip-snapshot Skip taking a consistent snapshot of the existing
database contents and just start streaming any new
updates. (Ignored if the replication slot already
exists.)
-C, --kafka-config property=value
Set global configuration property for Kafka producer
(see --config-help for list of properties).
-T, --topic-config property=value
Set topic configuration property for Kafka producer.
--config-help Print the list of configuration properties. See also:
https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
-h, --help
Print this help text.
bottledwater配置文件说明如下
./bottledwater --config-help 2>&1 |less
## Global configuration properties
Property | C/P | Range | Default | Description
-----------------------------------------|-----|-----------------|--------------:|--------------------------
builtin.features | * | | gzip, snappy, ssl, sasl, regex | Indicates the builtin features for this build of librdkafka. An application can either query this value or attempt to set it with its list of required features to check for library support.
*Type: CSV flags*
client.id | * | | rdkafka | Client identifier.
*Type: string*
metadata.broker.list | * | | | Initial list of brokers. The application may also use `rd_kafka_brokers_add()` to add brokers during runtime.
*Type: string*
bootstrap.servers | * | | | Alias for `metadata.broker.list`
message.max.bytes | * | 1000 .. 1000000000 | 1000000 | Maximum transmit message size.
*Type: integer*
message.copy.max.bytes | * | 0 .. 1000000000 | 65535 | Maximum size for message to be copied to buffer. Messages larger than this will be passed by reference (zero-copy) at the expense of larger iovecs.
*Type: integer*
receive.message.max.bytes | * | 1000 .. 1000000000 | 100000000 | Maximum receive message size. This is a safety precaution to avoid memory exhaustion in case of protocol hickups. The value should be at least fetch.message.max.bytes * number of partitions consumed from + messaging overhead (e.g. 200000 bytes).
*Type: integer*
max.in.flight.requests.per.connection | * | 1 .. 1000000 | 1000000 | Maximum number of in-flight requests the client will send. This setting applies per broker connection.
*Type: integer*
max.in.flight | * | | | Alias for `max.in.flight.requests.per.connection`
metadata.request.timeout.ms | * | 10 .. 900000 | 60000 | Non-topic request timeout in milliseconds. This is for metadata requests, etc.
*Type: integer*
topic.metadata.refresh.interval.ms | * | -1 .. 3600000 | 300000 | Topic metadata refresh interval in milliseconds. The metadata is automatically refreshed on error and connect. Use -1 to disable the intervalled refresh.
*Type: integer*
metadata.max.age.ms | * | | | Alias for `topic.metadata.refresh.interval.ms`
topic.metadata.refresh.fast.cnt | * | 0 .. 1000 | 10 | When a topic looses its leader this number of metadata requests are sent with `topic.metadata.refresh.fast.interval.ms` interval disregarding the `topic.metadata.refresh.interval.ms` value. This is used to recover quickly from transitioning leader brokers.
*Type: integer*
topic.metadata.refresh.fast.interval.ms | * | 1 .. 60000 | 250 | See `topic.metadata.refresh.fast.cnt` description
*Type: integer*
topic.metadata.refresh.sparse | * | true, false | true | Sparse metadata requests (consumes less network bandwidth)
*Type: boolean*
topic.blacklist | * | | | Topic blacklist, a comma-separated list of regular expressions for matching topic names that should be ignored in broker metadata information as if the topics did not exist.
*Type: pattern list*
debug | * | generic, broker, topic, metadata, queue, msg, protocol, cgrp, security, fetch, feature, all | | A comma-separated list of debug contexts to enable. Debugging the Producer: broker,topic,msg. Consumer: cgrp,topic,fetch
*Type: CSV flags*
socket.timeout.ms | * | 10 .. 300000 | 60000 | Timeout for network requests.
*Type: integer*
socket.blocking.max.ms | * | 1 .. 60000 | 100 | Maximum time a broker socket operation may block. A lower value improves responsiveness at the expense of slightly higher CPU usage.
*Type: integer*
socket.send.buffer.bytes | * | 0 .. 100000000 | 0 | Broker socket send buffer size. System default is used if 0.
*Type: integer*
socket.receive.buffer.bytes | * | 0 .. 100000000 | 0 | Broker socket receive buffer size. System default is used if 0.
*Type: integer*
socket.keepalive.enable | * | true, false | false | Enable TCP keep-alives (SO_KEEPALIVE) on broker sockets
*Type: boolean*
socket.nagle.disable | * | true, false | false | Disable the Nagle algorithm (TCP_NODELAY).
*Type: boolean*
socket.max.fails | * | 0 .. 1000000 | 3 | Disconnect from broker when this number of send failures (e.g., timed out requests) is reached. Disable with 0. NOTE: The connection is automatically re-established.
*Type: integer*
broker.address.ttl | * | 0 .. 86400000 | 1000 | How long to cache the broker address resolving results (milliseconds).
*Type: integer*
broker.address.family | * | any, v4, v6 | any | Allowed broker IP address families: any, v4, v6
*Type: enum value*
reconnect.backoff.jitter.ms | * | 0 .. 3600000 | 500 | Throttle broker reconnection attempts by this value +-50%.
*Type: integer*
statistics.interval.ms | * | 0 .. 86400000 | 0 | librdkafka statistics emit interval. The application also needs to register a stats callback using `rd_kafka_conf_set_stats_cb()`. The granularity is 1000ms. A value of 0 disables statistics.
*Type: integer*
enabled_events | * | 0 .. 2147483647 | 0 | See `rd_kafka_conf_set_events()`
*Type: integer*
error_cb | * | | | Error callback (set with rd_kafka_conf_set_error_cb())
*Type: pointer*
throttle_cb | * | | | Throttle callback (set with rd_kafka_conf_set_throttle_cb())
*Type: pointer*
stats_cb | * | | | Statistics callback (set with rd_kafka_conf_set_stats_cb())
*Type: pointer*
log_cb | * | | | Log callback (set with rd_kafka_conf_set_log_cb())
*Type: pointer*
log_level | * | 0 .. 7 | 6 | Logging level (syslog(3) levels)
*Type: integer*
log.thread.name | * | true, false | false | Print internal thread name in log messages (useful for debugging librdkafka internals)
*Type: boolean*
log.connection.close | * | true, false | true | Log broker disconnects. It might be useful to turn this off when interacting with 0.9 brokers with an aggressive `connection.max.idle.ms` value.
*Type: boolean*
socket_cb | * | | | Socket creation callback to provide race-free CLOEXEC
*Type: pointer*
connect_cb | * | | | Socket connect callback
*Type: pointer*
closesocket_cb | * | | | Socket close callback
*Type: pointer*
open_cb | * | | | File open callback to provide race-free CLOEXEC
*Type: pointer*
opaque | * | | | Application opaque (set with rd_kafka_conf_set_opaque())
*Type: pointer*
default_topic_conf | * | | | Default topic configuration for automatically subscribed topics
*Type: pointer*
internal.termination.signal | * | 0 .. 128 | 0 | Signal that librdkafka will use to quickly terminate on rd_kafka_destroy(). If this signal is not set then there will be a delay before rd_kafka_wait_destroyed() returns true as internal threads are timing out their system calls. If this signal is set however the delay will be minimal. The application should mask this signal as an internal signal handler is installed.
*Type: integer*
api.version.request | * | true, false | false | Request broker's supported API versions to adjust functionality to available protocol features. If set to false the fallback version `broker.version.fallback` will be used. **NOTE**: Depends on broker version >=0.10.0. If the request is not supported by (an older) broker the `broker.version.fallback` fallback is used.
*Type: boolean*
api.version.fallback.ms | * | 0 .. 604800000 | 1200000 | Dictates how long the `broker.version.fallback` fallback is used in the case the ApiVersionRequest fails. **NOTE**: The ApiVersionRequest is only issued when a new connection to the broker is made (such as after an upgrade).
*Type: integer*
broker.version.fallback | * | | 0.9.0 | Older broker versions (<0.10.0) provides no way for a client to query for supported protocol features (ApiVersionRequest, see `api.version.request`) making it impossible for the client to know what features it may use. As a workaround a user may set this property to the expected broker version and the client will automatically adjust its feature set accordingly if the ApiVersionRequest fails (or is disabled). The fallback broker version will be used for `api.version.fallback.ms`. Valid values are: 0.9.0, 0.8.2, 0.8.1, 0.8.0.
*Type: string*
security.protocol | * | plaintext, ssl, sasl_plaintext, sasl_ssl | plaintext | Protocol used to communicate with brokers.
*Type: enum value*
ssl.cipher.suites | * | | | A cipher suite is a named combination of authentication, encryption, MAC and key exchange algorithm used to negotiate the security settings for a network connection using TLS or SSL network protocol. See manual page for `ciphers(1)` and `SSL_CTX_set_cipher_list(3).
*Type: string*
ssl.key.location | * | | | Path to client's private key (PEM) used for authentication.
*Type: string*
ssl.key.password | * | | | Private key passphrase
*Type: string*
ssl.certificate.location | * | | | Path to client's public key (PEM) used for authentication.
*Type: string*
ssl.ca.location | * | | | File or directory path to CA certificate(s) for verifying the broker's key.
*Type: string*
ssl.crl.location | * | | | Path to CRL for verifying broker's certificate validity.
*Type: string*
sasl.mechanisms | * | | GSSAPI | SASL mechanism to use for authentication. Supported: GSSAPI, PLAIN. **NOTE**: Despite the name only one mechanism must be configured.
*Type: string*
sasl.kerberos.service.name | * | | kafka | Kerberos principal name that Kafka runs as.
*Type: string*
sasl.kerberos.principal | * | | kafkaclient | This client's Kerberos principal name.
*Type: string*
sasl.kerberos.kinit.cmd | * | | kinit -S "%{sasl.kerberos.service.name}/%{broker.name}" -k -t "%{sasl.kerberos.keytab}" %{sasl.kerberos.principal} | Full kerberos kinit command string, %{config.prop.name} is replaced by corresponding config object value, %{broker.name} returns the broker's hostname.
*Type: string*
sasl.kerberos.keytab | * | | | Path to Kerberos keytab file. Uses system default if not set.**NOTE**: This is not automatically used but must be added to the template in sasl.kerberos.kinit.cmd as ` ... -t %{sasl.kerberos.keytab}`.
*Type: string*
sasl.kerberos.min.time.before.relogin | * | 1 .. 86400000 | 60000 | Minimum time in milliseconds between key refresh attempts.
*Type: integer*
sasl.username | * | | | SASL username for use with the PLAIN mechanism
*Type: string*
sasl.password | * | | | SASL password for use with the PLAIN mechanism
*Type: string*
group.id | * | | | Client group id string. All clients sharing the same group.id belong to the same group.
*Type: string*
partition.assignment.strategy | * | | range,roundrobin | Name of partition assignment strategy to use when elected group leader assigns partitions to group members.
*Type: string*
session.timeout.ms | * | 1 .. 3600000 | 30000 | Client group session and failure detection timeout.
*Type: integer*
heartbeat.interval.ms | * | 1 .. 3600000 | 1000 | Group session keepalive heartbeat interval.
*Type: integer*
group.protocol.type | * | | consumer | Group protocol type
*Type: string*
coordinator.query.interval.ms | * | 1 .. 3600000 | 600000 | How often to query for the current client group coordinator. If the currently assigned coordinator is down the configured query interval will be divided by ten to more quickly recover in case of coordinator reassignment.
*Type: integer*
enable.auto.commit | C | true, false | true | Automatically and periodically commit offsets in the background.
*Type: boolean*
auto.commit.interval.ms | C | 0 .. 86400000 | 5000 | The frequency in milliseconds that the consumer offsets are committed (written) to offset storage. (0 = disable)
*Type: integer*
enable.auto.offset.store | C | true, false | true | Automatically store offset of last message provided to application.
*Type: boolean*
queued.min.messages | C | 1 .. 10000000 | 100000 | Minimum number of messages per topic+partition in the local consumer queue.
*Type: integer*
queued.max.messages.kbytes | C | 1 .. 1000000000 | 1000000 | Maximum number of kilobytes per topic+partition in the local consumer queue. This value may be overshot by fetch.message.max.bytes.
*Type: integer*
fetch.wait.max.ms | C | 0 .. 300000 | 100 | Maximum time the broker may wait to fill the response with fetch.min.bytes.
*Type: integer*
fetch.message.max.bytes | C | 1 .. 1000000000 | 1048576 | Initial maximum number of bytes per topic+partition to request when fetching messages from the broker. If the client encounters a message larger than this value it will gradually try to increase it until the entire message can be fetched.
*Type: integer*
max.partition.fetch.bytes | C | | | Alias for `fetch.message.max.bytes`
fetch.min.bytes | C | 1 .. 100000000 | 1 | Minimum number of bytes the broker responds with. If fetch.wait.max.ms expires the accumulated data will be sent to the client regardless of this setting.
*Type: integer*
fetch.error.backoff.ms | C | 0 .. 300000 | 500 | How long to postpone the next fetch request for a topic+partition in case of a fetch error.
*Type: integer*
offset.store.method | C | none, file, broker | broker | Offset commit store method: 'file' - local file store (offset.store.path, et.al), 'broker' - broker commit store (requires Apache Kafka 0.8.2 or later on the broker).
*Type: enum value*
consume_cb | C | | | Message consume callback (set with rd_kafka_conf_set_consume_cb())
*Type: pointer*
rebalance_cb | C | | | Called after consumer group has been rebalanced (set with rd_kafka_conf_set_rebalance_cb())
*Type: pointer*
offset_commit_cb | C | | | Offset commit result propagation callback. (set with rd_kafka_conf_set_offset_commit_cb())
*Type: pointer*
enable.partition.eof | C | true, false | true | Emit RD_KAFKA_RESP_ERR__PARTITION_EOF event whenever the consumer reaches the end of a partition.
*Type: boolean*
queue.buffering.max.messages | P | 1 .. 10000000 | 100000 | Maximum number of messages allowed on the producer queue.
*Type: integer*
queue.buffering.max.kbytes | P | 1 .. 2147483647 | 4000000 | Maximum total message size sum allowed on the producer queue.
*Type: integer*
queue.buffering.max.ms | P | 1 .. 900000 | 1000 | Maximum time, in milliseconds, for buffering data on the producer queue.
*Type: integer*
message.send.max.retries | P | 0 .. 10000000 | 2 | How many times to retry sending a failing MessageSet. **Note:** retrying may cause reordering.
*Type: integer*
retries | P | | | Alias for `message.send.max.retries`
retry.backoff.ms | P | 1 .. 300000 | 100 | The backoff time in milliseconds before retrying a message send.
*Type: integer*
compression.codec | P | none, gzip, snappy | none | compression codec to use for compressing message sets. This is the default value for all topics, may be overriden by the topic configuration property `compression.codec`.
*Type: enum value*
batch.num.messages | P | 1 .. 1000000 | 10000 | Maximum number of messages batched in one MessageSet. The total MessageSet size is also limited by message.max.bytes.
*Type: integer*
delivery.report.only.error | P | true, false | false | Only provide delivery reports for failed messages.
*Type: boolean*
dr_cb | P | | | Delivery report callback (set with rd_kafka_conf_set_dr_cb())
*Type: pointer*
dr_msg_cb | P | | | Delivery report callback (set with rd_kafka_conf_set_dr_msg_cb())
*Type: pointer*
## Topic configuration properties
Property | C/P | Range | Default | Description
-----------------------------------------|-----|-----------------|--------------:|--------------------------
request.required.acks | P | -1 .. 1000 | 1 | This field indicates how many acknowledgements the leader broker must receive from ISR brokers before responding to the request: *0*=Broker does not send any response/ack to client, *1*=Only the leader broker will need to ack the message, *-1* or *all*=broker will block until message is committed by all in sync replicas (ISRs) or broker's `in.sync.replicas` setting before sending response.
*Type: integer*
acks | P | | | Alias for `request.required.acks`
request.timeout.ms | P | 1 .. 900000 | 5000 | The ack timeout of the producer request in milliseconds. This value is only enforced by the broker and relies on `request.required.acks` being != 0.
*Type: integer*
message.timeout.ms | P | 0 .. 900000 | 300000 | Local message timeout. This value is only enforced locally and limits the time a produced message waits for successful delivery. A time of 0 is infinite.
*Type: integer*
produce.offset.report | P | true, false | false | Report offset of produced message back to application. The application must be use the `dr_msg_cb` to retrieve the offset from `rd_kafka_message_t.offset`.
*Type: boolean*
partitioner_cb | P | | | Partitioner callback (set with rd_kafka_topic_conf_set_partitioner_cb())
*Type: pointer*
opaque | * | | | Application opaque (set with rd_kafka_topic_conf_set_opaque())
*Type: pointer*
compression.codec | P | none, gzip, snappy, inherit | inherit | Compression codec to use for compressing message sets.
*Type: enum value*
auto.commit.enable | C | true, false | true | If true, periodically commit offset of the last message handed to the application. This committed offset will be used when the process restarts to pick up where it left off. If false, the application will have to call `rd_kafka_offset_store()` to store an offset (optional). **NOTE:** This property should only be used with the simple legacy consumer, when using the high-level KafkaConsumer the global `enable.auto.commit` property must be used instead. **NOTE:** There is currently no zookeeper integration, offsets will be written to broker or local file according to offset.store.method.
*Type: boolean*
enable.auto.commit | C | | | Alias for `auto.commit.enable`
auto.commit.interval.ms | C | 10 .. 86400000 | 60000 | The frequency in milliseconds that the consumer offsets are committed (written) to offset storage.
*Type: integer*
auto.offset.reset | C | smallest, earliest, beginning, largest, latest, end, error | largest | Action to take when there is no initial offset in offset store or the desired offset is out of range: 'smallest','earliest' - automatically reset the offset to the smallest offset, 'largest','latest' - automatically reset the offset to the largest offset, 'error' - trigger an error which is retrieved by consuming messages and checking 'message->err'.
*Type: enum value*
offset.store.path | C | | . | Path to local file for storing offsets. If the path is a directory a filename will be automatically generated in that directory based on the topic and partition.
*Type: string*
offset.store.sync.interval.ms | C | -1 .. 86400000 | -1 | fsync() interval for the offset file, in milliseconds. Use -1 to disable syncing, and 0 for immediate sync after each write.
*Type: integer*
offset.store.method | C | file, broker | broker | Offset commit store method: 'file' - local file store (offset.store.path, et.al), 'broker' - broker commit store (requires "group.id" to be configured and Apache Kafka 0.8.2 or later on the broker.).
*Type: enum value*
consume.callback.max.messages | C | 0 .. 1000000 | 0 | Maximum number of messages to dispatch in one `rd_kafka_consume_callback*()` call (0 = unlimited)
*Type: integer*
### C/P legend: C = Consumer, P = Producer, * = both
|
消费消息
由于confluent中存储的是avro封装的binary格式,所以消费时,需要使用解析avro的消费者。
./bin/kafka-avro-console-consumer --topic test --zookeeper localhost:2181
--property print.key=true
风险评估
1. 首次连接数据库时,会自动创建slot,同时自动开始将快照数据写入Kafka,如果数据库很大,这个过程会很漫长。
2. 为了得到一致的数据,会开启repeatable read的事务隔离级别,如果是9.6,并且配置了snapshot too old参数,可能导致快照拷贝失败。
3. 由于是逻辑DECODE,被复制的表必须包含逐渐,或指定非空唯一约束列,作为复制时的KEY。
4. 增,删,改在WAL中被解析为:
insert : key + full row
delete : old.key
update : old.key + new.key+full row
如果使用--allow-unkeyed跳过了主键,那么delete该表时,不会将任何数据写入Kafka,插入和更新则将所有列发给Kafka。
5. DDL操作不会记录到wal日志中,如果你需要将DDL也写入Kafka怎么办?
你可以使用event trigger,发生ddl时,将DDL封装并写入表中,然后这些表的DML会写入Kafka,从而实现DDL的传递。
6. 如果要删除生产者,务必删除数据库中对应的slot ,否则PostgreSQL会一直保留slot未读取的日志。 导致WAL目录撑爆。
7. 如果数据库产生的REDO没有被及时的解析并写入Kafka,可能导致未取走的数据库的wal文件一直留在数据库服务器,甚至导致数据库空间撑爆。
请谨慎使用slot,同时请将监控做得健壮。
8. Kafka topic与table一一对应,命名规则如下
由于命名中只有三个部分 [topic_prefix].[postgres_schema_name].table_name 没有考虑库名,所以如果有多个数据库时,建议配置top_prefix,和库名对应即可。
For each table being streamed, Bottled Water publishes messages to a corresponding Kafka topic.
The naming convention for topics is [topic_prefix].[postgres_schema_name].table_name:
table_name is the name of the table in Postgres.
postgres_schema_name is the name of the Postgres schema the table belongs to; this is omitted
if the schema is "public" (the default schema under the default Postgres configuration). N.B.
this requires the avro-c library to be at least version 0.8.0.
topic_prefix is omitted by default, but may be configured via the --topic-prefix command-line option.
A prefix is useful:
to prevent name collisions with other topics, if the Kafka broker is also being used for other purposes
besides Bottled Water.
if you want to stream several databases into the same broker, using a separate Bottled Water instance
with a different prefix for each database.
to make it easier for a Kafka consumer to consume updates from all Postgres tables, by using a topic
regex that matches the prefix.
For example:
with no prefix configured, a table named "users" in the public (default) schema would be streamed to a
topic named "users".
with --topic-prefix=bottledwater, a table named "transactions" in the "point-of-sale" schema would be
streamed to a topic named "bottledwater.point-of-sale.transactions".
(Support for namespaces in Kafka has been proposed that would replace this sort of ad-hoc prefixing,
but it's still under discussion.)
参考
- https://www.confluent.io/blog/bottled-water-real-time-integration-of-postgresql-and-kafka/
- http://docs.confluent.io/3.1.0/platform.html
- https://github.com/confluentinc/bottledwater-pg/tree/master#building-from-source
- http://docs.confluent.io/3.0.1/quickstart.html
- https://www.postgresql.org/message-id/797DF957-CE33-407F-99DB-7C7125E37ACE@kleppmann.com

https://su.tiancebbs.cn/hjzl/459546.html
https://su.tiancebbs.cn/hjzl/471204.html
https://aihuishou.tiancebbs.cn/sh/603.html
https://zulin.tiancebbs.cn/sh/866.html
https://www.tiancebbs.cn/ershouwang/469807.html
https://tacheng.tiancebbs.cn/qths/473771.html
https://www.tiancebbs.cn/ershouwang/473461.html
https://zulin.tiancebbs.cn/sh/1934.html
https://sx.tiancebbs.cn/qths/453954.html
https://taicang.tiancebbs.cn/hjzl/465212.html
https://fengshunxian.tiancebbs.cn/qths/465820.html
https://www.tiancebbs.cn/ershouwang/472651.html
https://sh.tiancebbs.cn/hjzl/471421.html
https://aihuishou.tiancebbs.cn/store/2775/info-page-49.html
https://zulin.tiancebbs.cn/sh/4428.html
https://zulin.tiancebbs.cn/sh/4563.html
https://heyuan.tiancebbs.cn/qths/471818.html
几分在心头:https://www.nanss.com/xuexi/2065.html 强国有我作文:https://www.nanss.com/xuexi/2602.html 核桃的功效与作用:https://www.nanss.com/yinshi/2926.html 风景作文:https://www.nanss.com/xuexi/2821.html 仿写句子大全:https://www.nanss.com/yulu/2534.html 给母亲的一封信:https://www.nanss.com/shenghuo/2889.html 推荐一个好地方四年级作文400字:https://www.nanss.com/xuexi/2059.html 春天的诗句:https://www.nanss.com/xuexi/2806.html 入党申请书:https://www.nanss.com/xuexi/2607.html 大学生实习总结:https://www.nanss.com/gongzuo/2990.html 漫画的启示作文500字五年级:https://www.nanss.com/xuexi/2793.html 蚕豆的功效与作用:https://www.nanss.com/shenghuo/2932.html 论文总结:https://www.nanss.com/xuexi/2920.html 生日快乐祝福语:https://www.nanss.com/yulu/2648.html 实践总结:https://www.nanss.com/xuexi/2557.html 钢铁是怎样炼成的读后感:https://www.nanss.com/xuexi/2795.html 社区矫正工作总结:https://www.nanss.com/shenghuo/2442.html 想念一个人的暖心说说:https://www.nanss.com/wenan/2246.html 国旗下的讲话:https://www.nanss.com/xuexi/2828.html 纪律作风整顿心得体会:https://www.nanss.com/gongzuo/2104.html 转正述职报告:https://www.nanss.com/gongzuo/2763.html 实习证明模板:https://www.nanss.com/xuexi/2773.html 形形色色的人:https://www.nanss.com/xuexi/2679.html 清洁工作文:https://www.nanss.com/xuexi/2940.html 市场调研报告:https://www.nanss.com/shenghuo/2706.html 入党介绍人的介绍意见:https://www.nanss.com/xuexi/2774.html 面试问题:https://www.nanss.com/gongzuo/2938.html 班主任培训总结:https://www.nanss.com/gongzuo/2582.html 有志者事竟成作文:https://www.nanss.com/xuexi/2950.html 读后感300字:https://www.nanss.com/xuexi/2952.html
 评论: 2
评论: 2
 浏览: 9620
浏览: 9620