| 【转】:利用pgpool实现PostgreSQL的高可用 原作者:Sure 创作时间:2015-12-29 13:40:48+08 |
doudou586 发布于2015-12-30 09:58:48
 评论: 6 评论: 6
 浏览: 25048 浏览: 25048
|
来自sure网友的博文,原文地址:http://my.oschina.net/Suregogo/blog/552765。
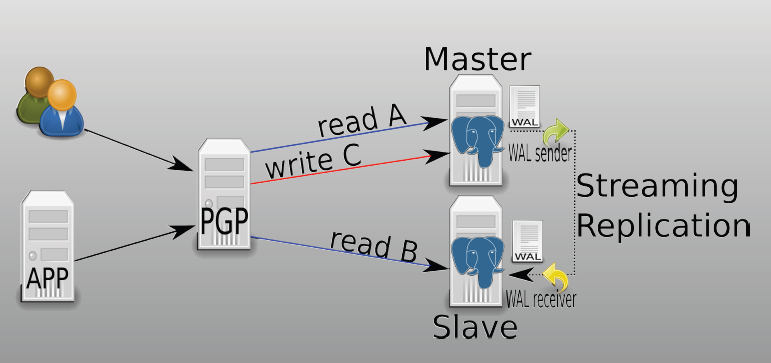
1、单pgpool:
基于流复制的方式,两节点自动切换:
1、单pgpool:
- 环境:
pgpool:192.168.238.129 data1:192.168.238.130 data2:192.168.238.131
- 图例:
- 配置互信:
ssh-copy-id ha@node1 ssh-copy-id ha@node2
- 数据库节点配置,请参照《使用pg_basebackup搭建PostgreSQL流复制环境》。
- pgpool配置:
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/home/ha/pgpool/log' health_check_period = 1 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgdb/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha'
- fail.sh
# Failover command for streaming replication. # This script assumes that DB node 0 is primary, and 1 is standby. # # If standby goes down, do nothing. If primary goes down, create a # trigger file so that standby takes over primary node. # # Arguments: $1: failed node id. $2: new master hostname. $3: path to # trigger file. new_master=$1 trigger_command="/home/ha/pgdb/bin/pg_ctl -D /home/ha/pgdb/data promote -m fast" # Do nothing if standby goes down. if [ $failed_node = 1 ]; then exit 0; fi # Create the trigger file. /usr/bin/ssh -T $new_master $trigger_command exit 0; - 建立pool_passwd
pg_md5 -m -p -u postgres pool_passwd
PS:在9.1之前一直用的是trigger_file,这里建议用promote -m fast的方式,因为 pg_ctl promote -m fast will skip the checkpoint at end of recovery so that we can achieve very fast failover when the apply delay is low. Write new WAL record XLOG_END_OF_RECOVERY to allow us to switch timeline correctly for downstream log readers. If we skip synchronous end of recovery checkpoint we request a normal spread checkpoint so that the window of re-recovery is low. Simon Riggs and Kyotaro Horiguchi, with input from Fujii Masao. Review by Heikki Linnakangas
- 测试
pgpool节点[ha@node0 pgdb]$ pgpool -n -d > /tmp/pgpool.log 2>&1 & [1] 22928 [ha@node0 pgdb]$ psql -h 192.168.238.129 -p 9999 -d postgres -U ha Password for user ha: psql (9.4.5) Type "help" for help. postgres=# insert into test values (8); INSERT 0 1 postgres=# select * from test ; id ---- 1 2 3 4 6 8 (6 rows)
node1节点:
[ha@localhost pgdb]$ ps -ef | grep post root 2124 1 0 Dec26 ? 00:00:00 /usr/libexec/postfix/master postfix 2147 2124 0 Dec26 ? 00:00:00 qmgr -l -t fifo -u postfix 13295 2124 0 06:01 ? 00:00:00 pickup -l -t fifo -u ha 13395 1 0 06:06 pts/3 00:00:00 /home/ha/pgdb/bin/postgres ha 13397 13395 0 06:06 ? 00:00:00 postgres: checkpointer process ha 13398 13395 0 06:06 ? 00:00:00 postgres: writer process ha 13399 13395 0 06:06 ? 00:00:00 postgres: wal writer process ha 13400 13395 0 06:06 ? 00:00:00 postgres: autovacuum launcher process ha 13401 13395 0 06:06 ? 00:00:00 postgres: stats collector process ha 13404 13395 0 06:07 ? 00:00:00 postgres: wal sender process rep 192.168.238.131(59415) streaming 0/21000060 ha 13418 4087 0 06:07 pts/3 00:00:00 grep post [ha@localhost pgdb]$ kill -9 13395
pgpool节点:
postgres=# insert into test values (8); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (8); INSERT 0 1 postgres=# insert into test values (8); INSERT 0 1 postgres=# select * from test ; id ---- 1 2 3 4 6 8 8 8 (8 rows)
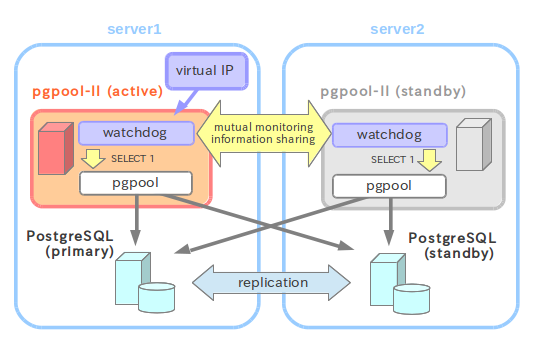
2.两个pgpool节点
- 环境
pgpool:192.168.238.129 pgpool:192.168.238.131 node1:192.168.238.130 node2:192.168.238.131
- 图例
- 配置互信,同上。
- 数据库节点配置,同上。
- pgpool配置: node1
- 配置pgpool(主)
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data/' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data/' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on authentication pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/tmp/log' master_slave_mode = on master_slave_sub_mode = 'stream' sr_check_period =2 sr_check_user = 'ha' sr_check_password = 'ha' health_check_period = 1 health_check_timeout = 20 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgpool/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha' use_watchdog = on wd_hostname = 'node1' #本端 delegate_IP = '192.168.238.151' #利用ifconfig,查看网卡 if_up_cmd = 'ifconfig eth1:0 inet $_IP_$ netmask 255.255.255.0' if_down_cmd = 'ifconfig eth1:0 down' heartbeat_destination0 = 'node2' #对端 heartbeat_device0 = 'eth0' other_pgpool_hostname0 = 'node2' #对端 other_pgpool_port0 =9999 other_wd_port0 = 9000
- 配置pgpool(从)
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data/' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data/' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on authentication pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/tmp/log' master_slave_mode = on master_slave_sub_mode = 'stream' sr_check_period =2 sr_check_user = 'ha' sr_check_password = 'ha' health_check_period = 1 health_check_timeout = 20 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgpool/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha' use_watchdog = on wd_hostname = 'node2' #本端 delegate_IP = '192.168.238.151' #利用ifconfig,查看网卡 if_up_cmd = 'ifconfig eth1:0 inet $_IP_$ netmask 255.255.255.0' if_down_cmd = 'ifconfig eth1:0 down' heartbeat_destination0 = 'node1' #对端 heartbeat_device0 = 'eth1' other_pgpool_hostname0 = 'node1' #对端 other_pgpool_port0 =9999 other_wd_port0 = 9000
- fail.sh
# Failover command for streaming replication. # This script assumes that DB node 0 is primary, and 1 is standby. # # If standby goes down, do nothing. If primary goes down, create a # trigger file so that standby takes over primary node. # # Arguments: $1: failed node id. $2: new master hostname. $3: path to # trigger file. new_master=$1 trigger_command="/home/ha/pgdb/bin/pg_ctl -D /home/ha/data start" # Do nothing if standby goes down. if [ $failed_node = 1 ]; then exit 0; fi # Create the trigger file. /usr/bin/ssh -T $new_master $trigger_command exit 0; - 建立pool_passwd
pg_md5 -m -p -u postgres pool_passwd
- 测试
#数据库、pgpool启动 [ha@node0 pgdb]$ psql -h 192.168.238.151 -p 9999 -d postgres -U ha Password for user ha: psql (9.4.5) Type "help" for help. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# --杀掉node1的数据库进程 postgres=# insert into test values (9); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 --杀掉node1的pgpool进程 postgres=# insert into test values (9); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=#
请在登录后发表评论,否则无法保存。
1# __
xcvxcvsdf 回答于 2025-02-12 10:36:54+08
https://aihuishou.tiancebbs.cn/sh/5918.html
https://ncyingshan.tiancebbs.cn/mayi-news.xml
https://aihuishou.tiancebbs.cn/wjcz/mayi-news.xml
https://ganzhou.tiancebbs.cn/qths/504219.html
https://cd.tiancebbs.cn/news/42834.html
https://aihuishou.tiancebbs.cn/flzldx/
https://zulin.tiancebbs.cn/sh/2502.html
https://jingouhe.tiancebbs.cn/
https://cd.tiancebbs.cn/news/35235.html
https://guixi.tiancebbs.cn/mayi-info.xml
https://aihuishou.tiancebbs.cn/store/2775/info-page-454.html
https://heming.tiancebbs.cn/mayi-info.xml
https://linhuzhenwz.tiancebbs.cn/
https://sh.tiancebbs.cn/hjzl/480660.html
https://www.tiancebbs.cn/news/42158.html
https://huangge.tiancebbs.cn/
https://www.tiancebbs.cn/ershoufang/501903.html
2# __
xcvxcvsdf 回答于 2025-01-16 01:55:44+08
https://aihuishou.tiancebbs.cn/xzkfqxz/mayi-news.xml
https://www.tiancebbs.cn/qtfwxx/502439.html
https://aihuishou.tiancebbs.cn/hcszbhcs/
https://aihuishou.tiancebbs.cn/yhstz/mayi-store.xml
https://bsqchengdong.tiancebbs.cn/
https://shoudujichang.tiancebbs.cn/mayi-store.xml
https://aihuishou.tiancebbs.cn/huaihuashi/mayi-category.xml
https://hyqzhenlongzhen.tiancebbs.cn/
https://aihuishou.tiancebbs.cn/smxhns/mayi-news.xml
https://jinpu.tiancebbs.cn/mayi-info.xml
https://aihuishou.tiancebbs.cn/xysgxq/
https://aihuishou.tiancebbs.cn/sh/4108.html
https://bsqchengbei.tiancebbs.cn/mayi-store.xml
https://xiaoyi.tiancebbs.cn/mayi-store.xml
https://fengqing.tiancebbs.cn/
https://ninghai.tiancebbs.cn/
https://cd.tiancebbs.cn/news/41775.html
3# __
xcvxcvsdf 回答于 2024-10-31 18:07:07+08
http://cf.lstcxxw.cn/ysqz/
http://fuyang.tjtcbmw.cn/wenshan/
http://jinqiang.ahtcbmw.cn/hulunbeier/
http://shimai.zjtcbmw.cn/naqu/
https://honglan.tiancebbs.cn/xuzhou/
http://nalei.zjtcbmw.cn/haikou/
https://baishuizhaipubu.tiancebbs.cn/
http://fs.shtcxxw.cn/lasa/
http://ouyu.hftcbmw.cn/csjz/
http://huaguang.jxtcbmw.cn/ntx/
http://gx.lztcxxw.cn/sxcz/
http://taiying.njtcbmw.cn/hndm/
http://cf.lstcxxw.cn/gling/
http://tuiguang.hntcxxw.cn/dalian/
http://bjtcxxw.cn/hljsys/
http://jingren.hftcbmw.cn/zhangye/
http://shenghuo.china-bbs.com/twlj/
4# __
xcvxcvsdf 回答于 2024-10-20 11:24:36+08
http://ly.shtcxxw.cn/eerduosi/
http://ruanwen.xztcxxw.cn/hljdq/
http://tuiguang.hntcxxw.cn/bjdx/
http://yz.cqtcxxw.cn/zc/
http://nalei.zjtcbmw.cn/jszj/
http://shimai.zjtcbmw.cn/jiujiang/
http://ruanwen.xztcxxw.cn/baicheng/
http://huilong.sctcbmw.cn/cqwl/
http://jinqiang.ahtcbmw.cn/jszp/
https://ccgaoxin.tiancebbs.cn/
http://cf.lstcxxw.cn/gzmnxc/
https://lfjingjikaifa.tiancebbs.cn/
http://shengshun.njtcbmw.cn/bazhong/
https://gaoguanzhen.tiancebbs.cn/
http://ruanwen.xztcxxw.cn/hbwh/
http://shengshun.njtcbmw.cn/zhangjiajie/
https://suo.tiancebbs.cn/
5# __
xcvxcvsdf 回答于 2024-10-12 17:46:25+08
https://chizhou.tiancebbs.cn/qths/466543.html
https://aihuishou.tiancebbs.cn/sh/2674.html
https://su.tiancebbs.cn/hjzl/457917.html
https://www.tiancebbs.cn/ershoufang/472275.html
https://www.tiancebbs.cn/ershoufang/473599.html
https://aihuishou.tiancebbs.cn/sh/430.html
https://zulin.tiancebbs.cn/sh/4599.html
https://aihuishou.tiancebbs.cn/sh/1159.html
https://sh.tiancebbs.cn/hjzl/458441.html
https://cd.tiancebbs.cn/hzwf/56570.html
https://www.tiancebbs.cn/wangzhantuiguang/440765.html
https://su.tiancebbs.cn/hjzl/470205.html
https://zulin.tiancebbs.cn/sh/4954.html
https://dapuxian.tiancebbs.cn/qths/459378.html
https://pt.tiancebbs.cn/qths/451718.html
https://zulin.tiancebbs.cn/sh/1304.html
https://www.tiancebbs.cn/ershouwang/470658.html
6# __
xiaowu 回答于 2024-04-21 07:34:52+08
游园活动方案:https://www.nanss.com/gongzuo/1111.html 专业技术人员年度考核个人总结:https://www.nanss.com/gongzuo/1334.html 成语故事:https://www.nanss.com/xuexi/582.html 独一无二的王者昵称:https://www.nanss.com/mingcheng/1416.html 男人网名:https://www.nanss.com/mingcheng/854.html 游戏角色名字:https://www.nanss.com/mingcheng/1023.html 论文结尾:https://www.nanss.com/xuexi/522.html 情侣名字:https://www.nanss.com/mingcheng/835.html 好词摘抄:https://www.nanss.com/xuexi/686.html 繁体字网名设计:https://www.nanss.com/mingcheng/1388.html 男生超拽网名:https://www.nanss.com/mingcheng/1173.html 网名大全男:https://www.nanss.com/mingcheng/512.html 师范生实习日志:https://www.nanss.com/gongzuo/865.html 雨天幽默正能量的句子:https://www.nanss.com/yulu/534.html 好听二字干净网名:https://www.nanss.com/mingcheng/853.html 繁体字网名:https://www.nanss.com/mingcheng/662.html 教学质量分析报告:https://www.nanss.com/gongzuo/1339.html qq男网名:https://www.nanss.com/mingcheng/1166.html 软件名称:https://www.nanss.com/gongzuo/1137.html 实习日记100篇通用版:https://www.nanss.com/xuexi/831.html 快手最吸引粉丝的网名:https://www.nanss.com/mingcheng/816.html 网络游戏名字:https://www.nanss.com/mingcheng/1252.html 蜘蛛开店续编故事:https://www.nanss.com/xuexi/718.html 男女合唱的歌:https://www.nanss.com/shenghuo/651.html 金工实习报告总结:https://www.nanss.com/gongzuo/749.html 班组意见:https://www.nanss.com/xuexi/957.html 关于不挑食的名言:https://www.nanss.com/xuexi/1084.html 咖啡语录:https://www.nanss.com/yulu/1308.html 团队合作的心得和感悟:https://www.nanss.com/gongzuo/910.html 世界第一大洲:https://www.nanss.com/shenghuo/1341.html
