| PostgreSQL 查询语句优化 原作者:李浩 创作时间:2016-09-24 15:29:15+08 |
doudou586 发布于2016-09-24 15:29:15
 评论: 5 评论: 5
 浏览: 14954 浏览: 14954
|
即将于 10 月 27 日在上海举办的 Postgres 中国用户大会 2016(PG 大象会)
目前正在进行火热报名中,为方便小伙伴们报名,主办方开通了三个快速报名通
道,尚未报名的伙伴们抓紧啦,10 月 11 日前报名还有 5.5 折优惠哦。
会鸽:http://pgconfcn2016.eventdove.com/
百格:http://www.bagevent.com/event/211925
活动行:http://www.huodongxing.com/event/8352217821400

摘自: 《PostgreSQL 查询引擎源码技术探析》一书
作者:李浩

1.1 概述
PostgreSQL 作为关系数据库中学院派的代表,在 U.C.Berkeley 完成了初始版本,其后 U.C. Berkeley 将其源码交于开源社区,PostgreSQL 现由开源社区对其进 行维护。PostgreSQL 代码具有简洁、结构清晰、浓重的学院派气息等特性。虽然, 其在国内并未像 MySQL 一样广泛在互联网公司内部使用,但是随着国内对 PostgreSQL 的认识加深,越来越多的公司逐渐采用 PostgreSQL 作为其解决方案中 数据的基础架构部件;更有许多公司在 PostgreSQL 的基础上进行二次开发来满足 自己的需求,例如 TeraData 公司的 AsterData 产品,EMC 公司的 GreenPlum 产品 等产品均在 PostgreSQL 基础之上进行架构来实现 MPP(Massively Parallel Processing,MPP)应用,PostgreSQL-‐XL/XC 同样也是一款基于 PostgreSQL 的 MPP 产品;Alibaba 云计算平台也已采用 PostgreSQL 作为 RDB(Relational Database , RDB)的基础构件。同样,Fujitsu、EnterpriseDB 以及 2ndQuadrant 等均提供对 PostgreSQL 的技术解决方案。
同时,随着数据仓库(Dataware house )及 Bussinesss Intelligence (BI)等对 PostgreSQL 处理能力要求的提高,众多开源界内核开发人员以单机 PostgreSQL 为 基础,构建基于 PostgreSQL 的大规模分布式应用 PostgreSQL-‐XL 及 PostgreSQL-‐XC。 上述所有案例无一不表明虽然在 MySQL 大行其道的情况下,PostgreSQL 仍然在 开源关系型数据库市场中占有一席之地并值得我们给予其足够的重视。
作为数据库内核中的重要一环,查询引擎在整个数据库管理系统中起到了 “大脑”的作用。查询语句是否以最优的方式来执行等均与查询引擎有着密不可 分的联系;不同的数据库对同一条查询语句的执行时间各不相同,有快有慢。究 其原因,除了存储引擎之间的差别,查询引擎生成的查询计划和执行计划的优劣 直接影响数据库在查询时的性能表现。不同的查询引擎产生的查询计划千差万别, 表现在查询效率上也千差万别。例如,查询语句中的连接操作(Join Operation ), 不同的查询引擎产生的优化策略会导致执行时间存在着数倍甚至数百倍的差距。
作为学院派代表的 PostgreSQL 有着一套复杂的查询优化策略,例如对子链接 的处理,基于代价的优化策略,基于规则的查询优化策略等。对于这些优化策略, PostgreSQL 并非墨守成规,而是也将这些优化策略的实现接口开放给第三方的内 核开发者,使得用户可以灵活地使用适用于特定应用场景的自有优化策略。例如, pg_rewrite 中描述的基于查询语法树的改写(Rewrite)规则 pg_rules,等等。
作为连接服务器层(Server Framework )与存储引擎层(Storage Engine )的 中间层,查询引擎将用户发送来的 SQL 语句按照 scan.l 和 gram.y 中预先定义的 SQL 词法(Lexcial Rules )及语法规则(Grammatic Rules)生成查询引擎系统内部 使用的查询语法树形式(Abstract SyntaxTree ,AST),查询引擎会将该查询语法 树进行预处理:将其转换为查询引擎可处理的形式——查询树 Query。
在由语法树到查询树的转换过程中,查询引擎会将查询语句中的某些部分进 行转换。例如,“*”会被为被扩展为相对应关系表的所有列,并在后续转换的过 程中,根据语法树所标示的类型进行分类处理,如 SELECT 类型语句、UPDATE 类 型语句、CREATE 类型语句等。
在查询引擎语法树到查询树转换后,PostgreSQL 查询引擎会使用 pg_rewrite 中设定的转换规则进行所谓的基于规则的转换,例如,PostgreSQL 查询引擎会将 VIEW 进行转换,为后续的优化提供可能。
在完成了基于规则的优化后,PostgreSQL 查询引擎进入到我们称之为逻辑优 化的阶段。在该阶段中,PostgreSQL 查询引擎将完成对公共表达式的优化,子链 接的上提,对 JOIN/IN/NOT IN的优化处理(进行 Semi-‐Join、Anti-‐Semi-‐Join 处理 等),Lateral Join 的优化等优化操作。
在执行上述优化操作中,我们将遵循一条“简单”法则:先做选择运行(δ Operation), 后做投影运算(π Operation)。经过此阶段的优化操作后,所得到的 查询树为一棵遵循了先选择后投影规则的最优查询树,并以此为基础构建最优查 询访问路径(Cheapest Access Path )。
在完成了对查询树的优化处理并获得最优查询访问路径后,PostgreSQL 查询 引擎接下来要做另外一件非常重要的事情是查询计划的生成(Plans Generating)。 PostgreSQL 查询引擎会依据最优查询访问路径,通过遍历该查询访问路径,来构 建最优查询访问路径对应的查询计划(Query Plans or Plan s)。
在查询计划的生成过程中,PostgresQL 查询引擎会在所有可行的查询访问路 径中选择一条最优的查询访问路径来构建查询计划。不同方式所构建的查询访问 路径的代价不尽相同,例如,执行多表 JOIN 操作时,不同的 JOIN 顺序产生的查 询访问路径不同,而这直接导致了查询访问路径中的中间元组规模的不同;同时, 关系表上索引的有无也将影响查询访问路径的代价,不同的表扫描方式将会极大 地影响执行效率。
通常,我们依据 COST = CPU_cost + IO_cost 公式来选择一条最优的执行路径, 其中,CPU_cost 表示执行该条执行计划需要的 CPU 代价,IO_cost 则为相应的 I/O 代价(启动代价,这里我们将其计入到 IO_cost 中)。
综上所述,一个查询引擎应该包括:查询语句接收模块、词法解析模块、语 法解析模块、查询树改写模块(规则优化模块)、查询优化模块(包括逻辑优化 和物理优化两部分)、查询计划生成模块、元数据管理模块、访问控制模块等基 本模块。当然不同的查询引擎在实现时,这些模块的划分可能不同,但是一个普 通的查询查询都应含有上述模块,图 1-‐1 为一个常规的查询引擎架构图。
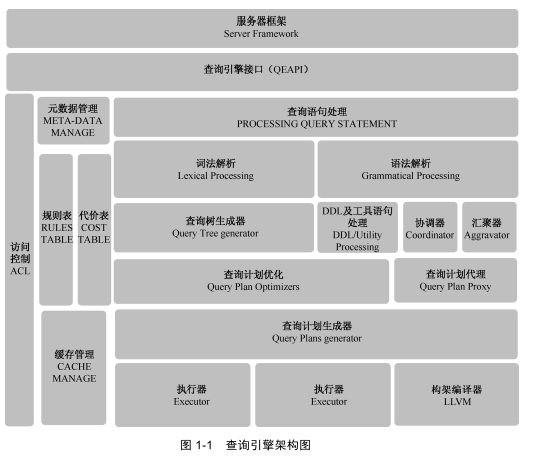
1.2 查询语句优化
当查询引擎接收到一条用户查询请求后,查询引擎会依据该查询语句的类型 进行分类处理;但在处理查询语句之前,考虑到复杂查询语句求解最优访问路径 时的代价,有些查询引擎会使用查询计划缓存机制(Query Plans Caching 或 Query Paths Caching ):数据库管理系统提供原生的最优查询访问路径代价缓存机制或 使用第三方的查询计划缓存解决方案。但在使用此缓存机制时需要注意:查询语 句需满足一定条件,例如满足不含有易失函数(Volatile Function),语句中涉及 的基表定义发生变化后的正确处理等条件后,才能对其使用缓存机制,否则可能 导致查询结果不正确。
查询引擎对不同类型的查询语句有着不同的处理机制,对于工具类查询语句 以及非工具类查询语句,PostgreSQL 有着截然不同的处理流程。
1.2.1 工具类语句
当查询语句为工具类查询(Utility Stat ements)语句时,查询引擎将经过词法 分析和语法分析后获得的查询语句作为其执行计划。工具类查询语句由 ProcessUtility 函数调用 standard_ProcessUtility 依据该语句的类型进行分类处理。 例如,对于 CreateTableSpace、Truncate、PrePare、Execute、Grant 等命令,查询 引擎将分别使用 CreateTableSpace、ExecuteTruncate、PrepareQuery、ExecuteQuery、 ExecuteGrantStmt 等函数对这些命令进行分类处理。那么哪些语句可归为工具类 语句呢?
PostgreSQL 将如下语句归为工具类型语句并将其交由 standard_ProcessUtility 函数处理。
工具类语句中包含:事务(Transaction)类语句,例如,开始事务、提交事 务、回滚事务、创建 SavePoint 等;游标(Cursor)类语句,例如,打开游标、 遍历游标、关闭游标等;内联过程语句类语句(Inline Procedural -‐Langauge);表 空间(TableSpace)操作类型语句,例如,创建表空间、删除表空间、修改表空 间参数等;Truncate 类语句;注释类语句;数据库对象安全标签类语句(Security Label to a Database Object );SQL Copy 类语句;Prepare 类型语句;权限或角色操 作相关类语句;数据库操作类语句,例如,创建数据库、删除数据库等;索引维 护类语句;Explain 语句;Vacuum 语句。
PostgreSQL 调用相应的命令处理函数对上述工具类语句进行分类处理,因此, 对于 standard_ProcessUtility 函数的实现,读者可轻松地猜到如下的实现方式,对 应其中的某类具体实现,在这里就不再详细给出,还请读者自行分析。函数原型 如程序片段 1-‐1 所示。
void
standard_ProcessUtility(Node *parsetree,
const char *queryString,
ProcessUtilityContext context,
...
)
{
switch (nodeTag(parsetree))
{
case T_TransactionStmt: {...} break;
case T_PlannedStmt: {...} break;
...
case T_DropTableSpaceStmt:{...}break;
...
default:{...} break;
}
}
1.2.2 查询类语句的处理
对于非工具类查询语句,即普通查询类语句,除了经历与工具类查询语句一 样的语法分析过程和词法分析过程,还需完成:将原始语法树转换为查询语法树; 以查询语法树为基础对其进行逻辑优化;对查询语句进行物理优化;查询计划创 建等过程。
经过词法分析(Lexical Processing)和语法分析(Grammatical Processing )后, PostgreSQL 需要将原始语法树转换为查询语法树并在转换过程中进行语义方面的合法性检查。 例如,基表(Base Relation )的有效性检查,目标列(Target List) 的有效性检查及展开,基表的 Namespace 冲突检查等。
transformStmt 函数依据查询语句的类型进行相应语法树到查询树的转换工作, 例如,由 transformSelectStmt 函数完成对 SELECT 类型查询语句的转换操作,由函 数 transformInsertStmt 完成对 INSERT 类型语句的语法树的转换。
查询引擎将对 SELECT 类型查询语句中不同的语法部分进行分类处理。由 transform-‐ TargetList 函数对目标列子句进行转换处理;transformWhereClause 函 数完成 WHERE、HAVING 子句的语法树转换处理;transformLimitClause 函数完成 Limit 和 Offset 语句的转换工作;transformSortClause 函数和 transformGroupClause 分别完成对 ORDER BY 语句及 GROUP BY 语句的转换。经过上述转换后,我们将 获得一棵(或数棵)由原始语法树转换而得到的 Query 类型查询树,并以此为基 础进入到查询优化的下一阶段:基于规则的查询改写。
原始语法树经过上述转换操作后,查询引擎获得 Query 类型的查询树,接下 来,查询将依据系统中定义的规则,对该查询树进行依据规则的改写操作,例如, 视图的改写等。元数据表 pg_rules 中描述了当前系统中具有的规则说明。除了使 用 CREATE RULE 、ALTER RULE 、DROP RULE 命令来维护该规则系统,我们还可以 通过“暴力”手段,直接修改 pg_rules 元数据表来“维护”规则系统。在完成基 于规则的改写后,查询引擎将进入下一阶段的优化:查询逻辑优化(Logical Optimization)。
逻辑优化阶段中,会对所有导致查询变慢的语句进行等价变换,依据数据库 理论中给出的经典优化策略:选择下推,从而尽可能减少中间结果的产生。即所 谓的先做选择操作,后做投影操作。优化原则如图 1-‐2 所示。
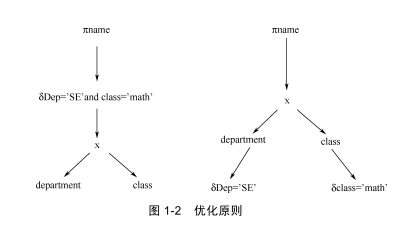
首先,查询引擎由函数 pull_up_sublinks 分别对 IN 和 EXISTS 类型子链接 (SubLink)进行优化处理:将子链接转为 SEMI-‐JOIN,使得子链接中的子查询有 机会与父查询语句进行合并优化。函数 pull_up_sublinks 中,PostgreSQL 在确定 子链接满足 SEMI-‐JOIN 转换的条件后,分别由 convert_ANY_sublink_to_join 函数 及 convert_EXISTS_sublink_to_join 函数将 IN 和 EXISTS 类型的子链接转换为 SEMI-‐JOIN 类型的 JOIN 连接。经过转换后,查询效率较低的 IN/EXISTS 子链接操 作转换为查询效率较高的 JOIN 操作。
完成子链接转换后,查询引擎将使用函数 pull_up_subqueries 对查询树中的 子查询(SubQuery)进行上提操作,将子查询中的基表(Base Relation )上提至 父查询中,从而使子查询中的基表有机会与父查询中的基表进行合并,由查询引 擎统一进行优化处理。
接下来,查询引擎使用 preprocess_expression 函数对查询树中的表达式进行 预处理,例如,将表达式进行规则化,常量表达式求值优化等。
在完成对查询树中表达式的优化处理后,查询引擎将对查询约束条件进行相 关优化处理。例如,约束条件的下推,约束条件的合并、推导及无效约束条件的 移除等。随后,查询引擎将优化处理后的约束条件绑定到其对应的基表之上,即 所谓的约束条件的分配(Distribute the Restriction Clauses )。在完成上述操作后, 查询引擎将进入全新的优化阶段:查询物理优化(Physical Optimization )。
查询物理优化阶段最主要的任务是选择出一条查询代价最优的查询访问路 径(Query Access Path ,Path)。依据逻辑优化阶段所得的查询树为基础构建一条 最小查询访问代价的查询路径。为了能够正确且高效地计算出不同查询访问路径 下的查询代价,查询引擎依据基表之上存在的约束条件,估算出获取满足该约束 条件的元组需要的 I/O 代价和 CPU 代价。我们以概率论和统计分析为工具,通过 元数据表 pg_statistic 中的统计信息计算出满足该约束条件的元组占整个元组的 比重,以此来估算该约束条件下的元组数量。通常,我们使用选择率(Selectivity) 来描述上述的比重。
在完成对查询语句中涉及的各个基表的物理参数和约束条件的设置后,查询 引擎将考察各个基表所能形成的连接关系。若计算后,两个基表可形成连接关系, 则查询引擎将进一步尝试确立连接类型并完成对此种连接条件下的查询代价估 算。例如,两个基表是否可以构成 MergeJoin?HashJoin?还是传统的 NestLoopJoin? 上述就是我们通常所说的查询路径寻优的过程。当查询语句中涉及的基表数量较 小时,由于其对应的最优解(最优查询访问路径)搜索空间较小,PostgreSQL 将 采用动态规划算法(Dynamic Programming )来求解最优查询访问路径;但当查 询中涉及的基表数量较多时(该阈值将在后续章节进行讨论),将导致最优解的 搜索空间以指数倍(Exponential)增长。此时,传统的动态规划算法将无法满足 求解要求。为解决由于基表数量的增加所带来最优解求解时间的极速增长, PostgreSQL 查询引擎引入了基因遗传算法(Genetic Algorithm )来加速最优解的 求解。
在成功地获得一条(相对)最优的查询访问路径后。接下来,查询引擎将以 该查询访问路径为蓝本,构建查询访问路径所对应的查询计划。
1.3 创建查询计划
作为查询引擎所有工作的最终结果——查询计划描述了对查询语句的求解 过程。按照查询计划所描述的步骤,执行引擎只需“按部就班”地操作即可获取 最终的查询结果。
与查询语句在逻辑优化和物理优化阶段不同,查询计划创建阶段的模块的功 能相对单一,无须较多的查询优化理论知识,只需依照最优查询访问路径所描述 的步骤,分类创建其对应的查询计划节点(Plans),最后将所有查询计划节点合 并形成最后的查询计划树。
在 create_plan 函数中,查询引擎将依据查询访问路径中的各个节点类型,分 类创建其对应的查询计划:由 create_seqscan_plan 函数创建顺序扫描查询计划; 由 create_mergejoin_plan 函数创建 MergeJoin 查询计划;create_hashjoin_plan 函 数则以 HashJoin 类型的查询访问路径为参数构建 HashJoin 查询计划。
在获得查询计划后,PostgreSQL 将查询计划送入执行器(Executor)中,执 行器依据查询计划执行给出的表扫描操作获取满足条件的元组后按照指定的格 式进行输出。
1.4 小结
我们将上述的优化过程简短地描述为如下流程:
- (1)由应用程序建立到 PostgreSQL 服务器的连接。应用服务器发送查询请 求至 PostgresSQL 服务器并从 PostgreSQL 服务器接收查询结果。
- (2)查询引擎将查询语句依据所定义的词法规则和语法规则构建原始查询 语法树。
- (3)查询分析阶段,查询引擎将原始语法树转换为查询树。
- (4)查询改写阶段,查询引擎将查询树依据系统中预先定义的规则对查询树 进行转换。
- (5)优化器(Planner)接收改写后的查询树并依据该查询树完成查询逻辑 优化。
- (6)优化器(Planner)继续对已完成逻辑优化的查询树进行查询物理优化 并求解最优查询访问路径。
- (7)执行器(Executor)依据最优查询访问路径进行表扫描操作并将获取的 数据按一定格式创建返回值,然后将结果返回应用程序。
那么上述讨论的查询引擎所完成的工作是如何将数据库查询优化理论具体 化的呢?那些 pull_up 函数和约束条件的处理又是如何完成的呢?是否所有的子 链接和子查询都可以进行转换?两个基表构成连接所需要满足什么样的条件呢? PostgreSQL 查询引擎在系统实现上又有什么值得我们学习的地方呢?带着种种 的疑问,下面开始我们的查询引擎内核分析之旅吧。

请在登录后发表评论,否则无法保存。
