| PostgreSQL MVCC快照机制浅析 原作者:何小栋 创作时间:2019-01-22 09:50:54+08 |
redraiment 发布于2019-01-22 09:50:54
 评论: 2 评论: 2
 浏览: 9354 浏览: 9354
|
作者简介
- 作者:何小栋
- 博客:http://blog.itpub.net/6906
- 简介:长期从事政务、金融等行业项目管理、产品研发和架构设计工作,对Oracle、PostgreSQL以及大数据等相关技术有深入研究。现就职于广州云图数据技术有限公司,系统架构师。
摘要
快照隔离是数据库实现并发控制的一种常用技术。本文简单探讨了快照理论模型、PostgreSQL的工程实践以及由此推广至Postgres-XL的可能改进思路等。
一、快照模型
快照,顾名思义表示某个时间点的状态。在日常生活中,我们使用相机拍摄,拍下来的画面可以理解为拍摄对象的快照;与此类似,连接数据库执行操作(如查询)时数据库的状态也可以视为快照。
为了方便讨论,假定数据库事务隔离级别为READ COMMITTED,考虑以下场景:
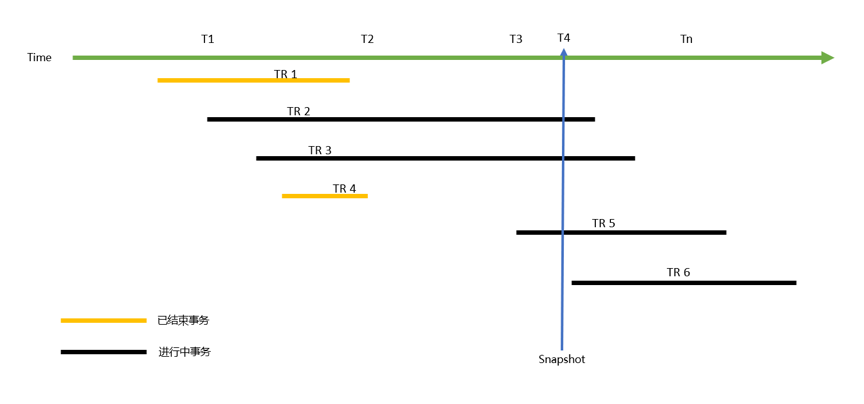
假设在时间点T4执行操作OP,在T4获取数据库状态快照:
其中,TR1/TR4为已完结事务,TR2/TR3/TR5是正在进行中的事务,TR6是在T4后发生的事务.显然,TR1和TR4事务对数据库的修改对操作OP可见;TR6是未来发生的事务,对操作OP不可见;TR2/TR3/TR5正在进行中,同样也不可见。
就此场景而言,理论上我们只需要知道"拍摄"快照的时间T4,就可以控制数据库变化的可见性,简单而言就是:在此时间前完结的事务,可见,在此时间之后的事务,不可见。
二、PostgreSQL工程实践
按上一小节的介绍,可以看到事务的执行具有顺序性和单调递增性,在日常生活中,时间也“自然”就具备了顺序性和单调递增性,但在PG中,事务号XID并没有使用时间戳等信息而是使用了自然数列(1,2,…,n)。
快照模型
考虑以下场景(简单起见,假设无论是只读还是修改事务,均分配事务号):
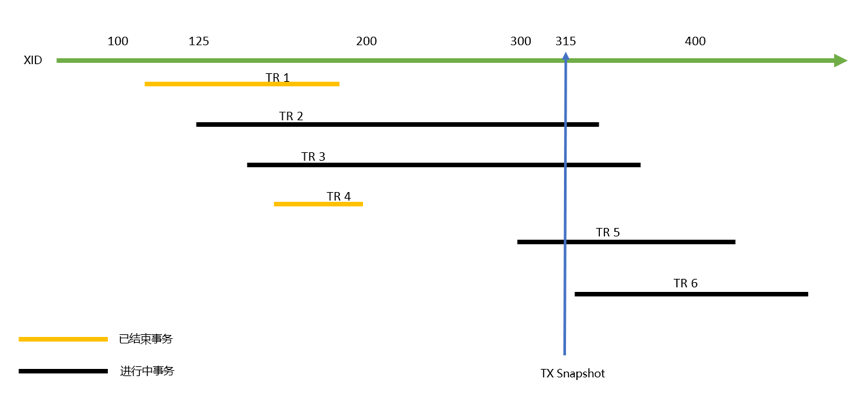
XID=315的事务执行操作(以下简称OP),要求获取数据库快照,与上一个场景类似,TR1和TR4事务执行的数据库修改对操作OP可见;TR6是未来发生的事务,对操作OP不可见;TR2/TR3/TR5正在进行中,同样也不可见。理论上,只需要知道该查询的事务号(如315)就可以控制可见性。
工程实践
在工程实践上,PostgreSQL并没有简单的使用事务号作为快照。一是因为只读事务系统并没有分配事务号,二是事务号在PG中是一种资源(事务号的定义为无符号32bit整型,需循环再用),能避免分配和使用的尽可能避免使用。因此PG使用了最后一个已结束的事务号+1(即snapshot中的xmax)作为历史和未来的分界:
- 大于等于xmax的,属于未来事务,不可见;
- 小于xmax的,已结束事务可见,进行中事务不可见。
另外,出于性能的考虑,为了进一步区分小于xmax的事务,避免遍历小于xmax的所有事务信息,引入了xmin和xip_list:
1) 小于xmin的事务,视为已结束事务,可见; 2) 大于等于xmin小于xmax,进行中的事务,不可见,否则可见。
仍以上述场景为例(详见下图):
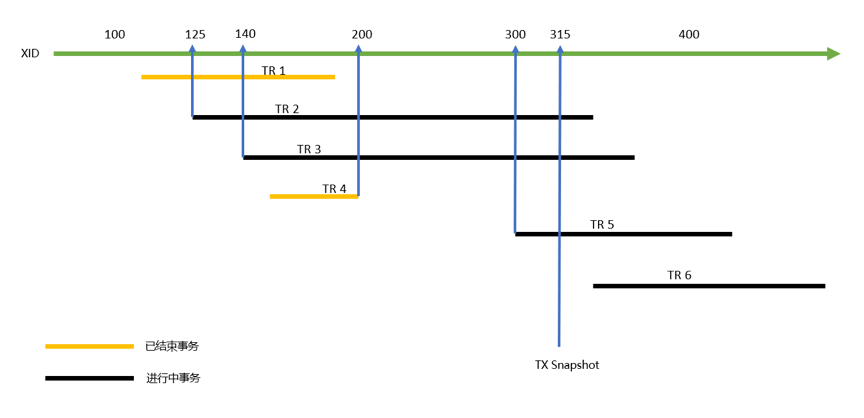
最后已结束事务为200,最早仍活跃事务为125,则:
xmax = 200 + 1 = 201
xmin = 125
snapshot = 125 : 201 : 140
系统函数
对于事务号和快照的获取,PostgreSQL提供相应的系统函数。
获取事务号
txid_current:获取事务号,如未分配,则分配一个
11:39:02 (xdb@[local]:5432)testdb=#* select txid_current();
txid_current
--------------
2330
(1 row)
txid_current_if_assigned:获取事务号,如未分配,则返回NULL
11:24:11 (xdb@[local]:5432)testdb=# select txid_current_if_assigned();
txid_current_if_assigned
--------------------------
(1 row)
获取快照
通过函数txid_current_snapshot可获取当前的快照信息:
11:05:16 (xdb@[local]:5432)testdb=# select txid_current_snapshot();
txid_current_snapshot
-----------------------
2404:2404:
(1 row)
11:24:11 (xdb@[local]:5432)testdb=#
输出格式为xmin:xmax:xip_list
其中:
- xmin:最早仍活跃的事务ID,早于此XID的事务要么被提交并可见,要么回滚/丢弃。
- xmax:最后已结束事务(COMMITTED/ABORTED)的事务ID + 1。
- xip_list:在"拍摄"快照时仍进行中的事务ID。该列表包含xmin和xmax之间的活动事务ID。
总结一下,简单来说,对于给定的XID:
- XID ∈ [1,xmin),过去的事务,对此快照均可见;
- XID ∈ [xmin,xmax),不考虑子事务的情况,仍处于IN_PROGRESS状态的,不可见;COMMITED状态,可见;ABORTED状态,不可见;
- XID ∈ [xmax,∞),未来的事务,对此快照均不可见。
数据结构
在代码实现上,PostgreSQL使用SnapshotData结构体存储快照信息
SnapshotData结构体定义如下:
//SnapshotData结构体指针
typedef struct SnapshotData *Snapshot;
typedef struct SnapshotData
{
//判断tuple是否可见的函数
SnapshotSatisfiesFunc satisfies; /* tuple test function */
//XID ∈ [2,min)是可见的
TransactionId xmin; /* all XID < xmin are visible to me */
//XID ∈ [xmax,∞)是不可见的
TransactionId xmax; /* all XID >= xmax are invisible to me */
/*
* For normal MVCC snapshot this contains the all xact IDs that are in
* progress, unless the snapshot was taken during recovery in which case
* it's empty. For historic MVCC snapshots, the meaning is inverted, i.e.
* it contains *committed* transactions between xmin and xmax.
* 对于普通的MVCC快照,xip存储了所有正在进行中的XIDs,除非在恢复期间产生的快照(这时候数组为空)
* 对于历史MVCC快照,意义相反,即它包含xmin和xmax之间的*已提交*事务。
*
* note: all ids in xip[] satisfy xmin <= xip[i] < xmax
* 注意: 所有在xip数组中的XIDs满足xmin <= xip[i] < xmax
*/
TransactionId *xip;
...
}
xmin/xmax/xip分别对应txid_current_snapshot()函数输出的xmin/xmin/xip_list。
三、Postgres-XL可能的改进
XL的意思是:eXtensible Lattice,可以扩展的格子,意思将PostgreSQL应用在多节点上的分布式数据库。Postgres-XL 是一个完全满足ACID的、开源的、可方便进行水平扩展的、多租户安全的、基于PostgreSQL的数据库解决方案。
其体系结构如下图所示:
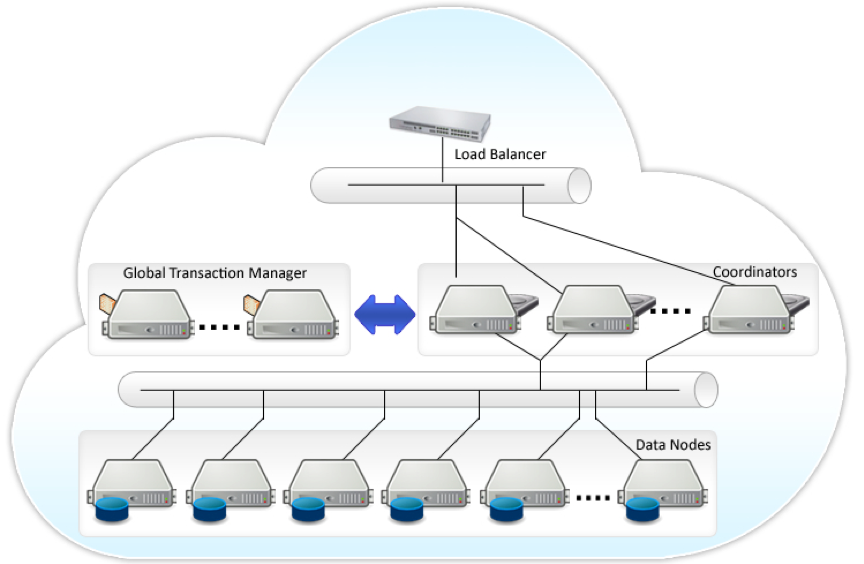
图四 Postgres-XL体系结构(来自https://www.postgres-xl.org/overview/)
Postgres-XL沿袭了PostgreSQL的事务模型,仍使用自然数列作为事务号XID,因此存在作为中心点的全局事物管理器GTM(Global Transaction Monitor),负责处理事务ID和快照。GTM作为中心的存在容易成为整个数据库集群的性能瓶颈,不利于系统的扩展,因此改进的一个方向是考虑GTM所负责的事务ID和快照管理是否可以通过各个节点自行处理?
不考虑广义相对论,在地球上,时间是绝对公平和单调"递增"的,这个属性与自然数列类似,因此我们可以考虑利用本机的时间戳作为事务号生成的输入,保证事务号按顺序的单调递增和唯一性。
下面是时间戳的定义(来自百度百科):
时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总毫秒数。通俗的讲, 时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据。 它的提出主要是为用户提供一份电子证据, 以证明用户的某些数据的产生时间。 在实际应用上, 它可以使用在包括电子商务、 金融活动的各个方面, 尤其可以用来支撑公开密钥基础设施的 “不可否认” 服务。
时间戳使用无符号64位的整型(uint64)表示。
事务ID的获取
假设集群中有N个节点,按Postgres-XL的体系结构,每个节点均部署了Coordinator协调器,自然可以想到的是节点在接收到客户端请求,在需要获取事务号时,由本地Coordinator获取本地时间戳,通过一定的机制(HLC算法/TSO服务/分布式协议…)保证该时间戳的顺序性和唯一性,然后把该时间戳通过算法(最简单的算法是对2^32进行求余数)转换为PG的事务号。这时候每一个Coordinator在处理获取事务号时都是自己事务的中心,减少了对GTM这个中心点的依赖。
快照管理
快照管理与获取事务ID类似,某个节点在需要获取快照时,该节点的Coordinator根据时间戳获取快照中的xmax,然后通过协调其他各个节点的Coordinator获取xmin/xip_list,组成最终的snapshot,然后以该snapshot作为其他节点的输入,由各节点根据该snapshot执行相应的查询(与PG机制保持一致)。
诚然,上述思路只是理论上的推导,在工程实践仍有非常多的细节(比如各个节点之间的时间同步/如何减少网络开销等等)需要考虑。
四、参考资料
- Mvcc Unmasked:https://momjian.us/main/writings/pgsql/mvcc.pdf
- PG Source Code:https://doxygen.postgresql.org
- Postgres-XL:https://www.postgres-xl.org/overview/
- 分布式系统的时间:https://www.jianshu.com/p/8500882ab38c

请在登录后发表评论,否则无法保存。
