PostgreSQL9.5版本引入了BRIN索引类型,BRIN是BlockRange Index的简称。通过BRIN的引入,开辟了数据访问的新路径。对于大量数据访问的场景,BRIN能够有效地过滤掉不符合条件的heap page,从而减少需要访问的buffer的数量,进而提升查询效率。更重要的是,BRIN索引本身的结构非常简单和高效,能够节省大量的存储空间。在另一篇文章中已经提到BRIN相比BTREE可以有几千倍的存储空间节约。现在我们就结合案例来看一下BRIN索引的存储组织结构,为什么可以达到如此高效的存储。
本文需要使用到pageinspect插件来对BRIN索引的存储结构进行分析,这里就不再赘述pageinspect插件的安装方法,大家可以参照文档自行安装使用。
在分析BRIN索引结构之前,还是需要先构造案例和测试数据。本文中使用的表结构如下:
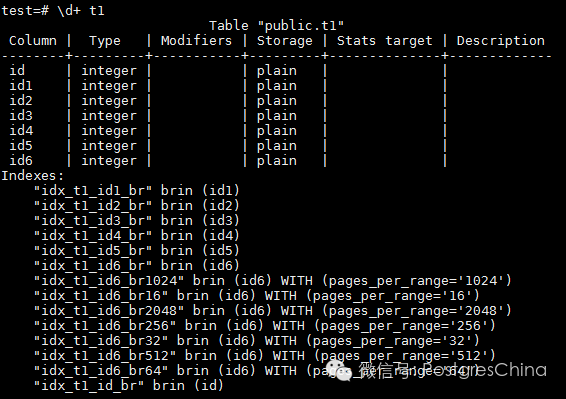
重点关注id6这个字段即可。可以看到在id6字段上,创建了总共8个BRIN类型的索引,稍后会讲解这8个索引各有什么不同。
表中的数据使用如下SQL进行构造:
insert into t1 select id, mod(id, 100), round(id/100), mod(id, 1000), round(id/1000), mod(id,30000), round(id/30000) from generate_series(1, 10000000) id;
表中数据量有10,000,000行,id6这个字段通过产生的序列值除以30000后取整获得。数据分布对BRIN索引大小没有影响,而主要是对索引的条目值有影响。

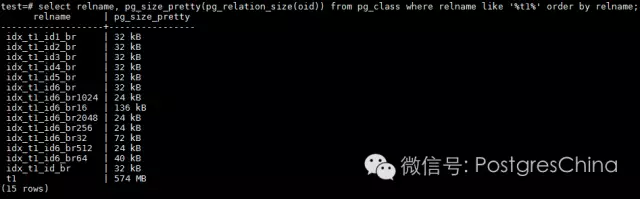
BRIN索引的大小主要受到pages_per_range这个索引storage parameter的影响,缺省情况下,BRIN的pages_per_range是128。也就是说,BRIN索引的一个条目缺省涵盖128个heappage对应字段值的范围。例子中8个不同的BRIN索引使用了不同大小的pages_per_range参数来创建,后缀br16代表pages_per_range=16,后缀br32代表pages_per_range=32,依此类推。而不带后缀的br是使用缺省的128来创建的。出于普遍性考虑,我们先来看pages_per_range=128的BRIN索引结构,也就是idx_t1_id6_br。
基本上,一个BRIN索引由三部分结构组成:meta page,revmap page和regular page。我们可以通过pageinspect的函数来获取BRIN索引上不同的page类型。从上面的截图得知,idx_t1_id6_br总共有4个page,大小为32K。来看一下每个page的类型。
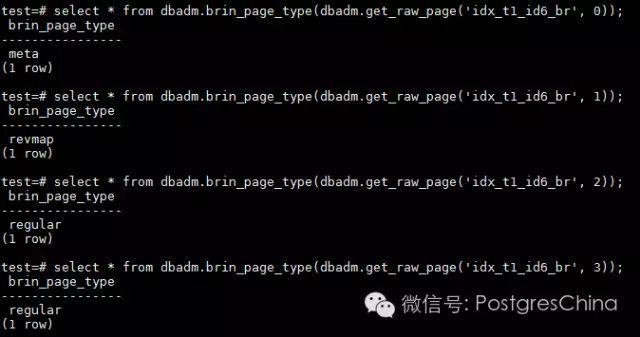
可以看到,第一个是metapage,第二个是revmap page,而第三、第四个是regularpage。再来看一下每个page的内容。首先看下metapage能够告诉我们一些什么。

Meta page告诉了我们四个信息:
- Metapage的Magic Number;
- BRIN索引的版本号,本例中是1;
- 这个BRIN索引的pages_per_range设置,本例是128;
- 最后一个revmap page的位置,本例是1。这也和我们之前获取page type的数据相匹配,第二个page也就是page 1是revmap page。而之后的两个page则为regular page。PG中,page的编号从0开始;
再来看一下revmap page的内容。
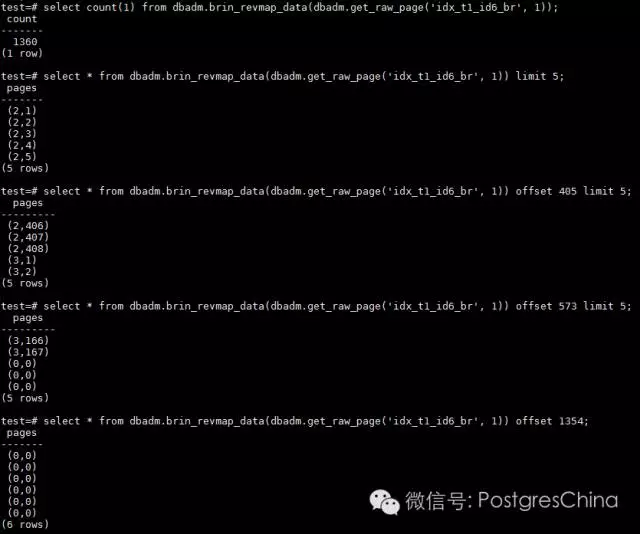
由于内容较多,没有全部显示,只对几个关键的部分进行了截取来分析revmap的结构组成。在访问BRIN索引时,从meta page中我们可以知道revmap page数量总共有多少,而从revmap page中,我们可以知道BRIN索引的条目在各个regular page上的分布,从而知道应该访问哪个regular page而找到对应的条目,并且获得对应heap page范围的字段值信息。
本例中,只有一个revmappage。在revmap page上可以得知,从第1到第408个索引条目存放于编号为2的regularpage上;而编号为3的regular page上存放了167个索引条目,也就是第409到第575个索引条目。一个revmap page总共可以存放1360个条目的位置信息。这是对这些数据的直观解释,但这些数据是如何得出以及能够告诉我们一些什么呢?
- 从之前的数据知道,t1表有73530个heap page。idx_t1_id6_br这个BRIN索引是缺省按照pages_per_range=128来创建的。从这些信息可以计算出,需要ceiling(73530/128::decimal)=575个索引条目。这和我们从revmap从获得的数据是匹配的;
- 因为一个regular page可以存放408个索引条目,所以575个条目需要两个regular page来存放。也和revmap page中获得的数据一致;
- 由于一个revmap page可以存放1360个索引条目的位置信息,因此对于一个revmap page来讲,可以管理1360*128(pages_per_range)*8KB(pagesize)/1024=1360MB的表。当前t1表的大小是574MB,只要表小于1360MB,一个revmap page就足够了;
再来看一下regular page的内容。
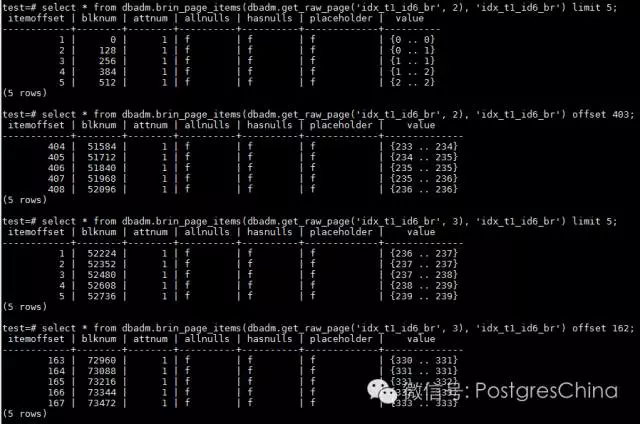
解读一下:
- blknum是一个索引条目的起始heappage编号。例如第一个条目涵盖从0到127的heap page,所以blknum等于0;
- attnum是指一个条目中存放的是第几个字段的信息。本例中,由于只索引了一个字段id6,所以attnum全部为1。如果索引两个字段,会有attnum为2的情况;
- allnulls是告诉我们在一个条目涵盖的128个heap page对应的索引字段上是否全部为NULL值。本例因为全部有值,所以allnulls都是false;
- hasnulls顾名思义,告诉我们在一个条目涵盖的128个heap page对应的索引字段上是否含有NULL值。本例因为全部有值,所以allnulls都是false;
- value这个字段可以说是BRIN中最重要、最精华的部分,它存储了一个条目涵盖的128个heap page对应字段的最小值和最大值。PG就是根据这个value值来判断SQL的执行器(executor)是否需要扫描这128个heappage。拿第一个条目来说明,由于id6是通过顺序递增的值除以30000后取整获得,只要值小于30000这个字段的值都为0,一个heappage上可以存放136行数据,128个heap page存放的行数是17408,17408<30000,所以BRIN的第一个索引条目最小值和最大值都为0。其他的条目也可以如此计算。这样,当执行例如id6=1的查询过滤时,PG便知道无需扫描这个BRIN索引条目所涵盖的128个heap page,而只需要扫描第2、第3和第4索引条目涵盖的合共384个heap page就可以,从而提升查询效率。
以上是在缺省pages_per_range=128情况下对于BRIN索引进行的结构分析。对于其他pages_per_range设置,道理也是一样的。我们就拿一个pages_per_range=16的快速分析一下,不妨先按照之前的计算方法预估一下:
- page0为metapage,版本号为1,pagesperrange是16;
- lastrevmappage的计算方法是ceiling(73530/16/1360::decimal)=4。其中,73530是表heap page的数量,16是pages_per_range的值,而1360是一个revmap page可以存放的BRIN索引条目位置的数量;
- 由于lastrevmappage=4,所以regular page是从page 5开始,数量为ceiling(73530/16/408::decimal)=12个。408是每个regular page可以存放的BRIN索引条目数;
- 综上,idx_t1_id6_br16整个索引应该有1+4+12=17个page;
我们从实际数据看一下是否如此:
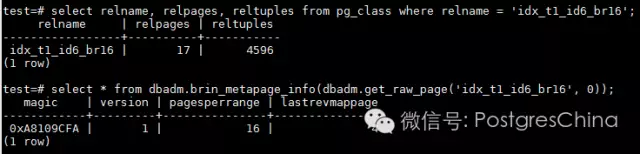
果然如此,而reltuples=ceiling(73530/16::decimal)=4596,也就是BRIN的索引条目数。
再看一下regular page中索引的条目
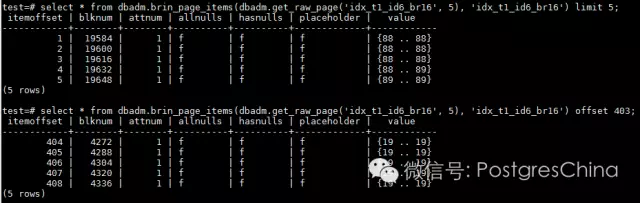
可以发现,索引条目并没有完全按照表中heap page的次序来排列。第一个索引条目已经到了heap page 1224了,而不是从0开始。那么,page 0-16的索引在哪儿呢?而如何找出在BRIN索引中heap page的顺序呢?revmap可以告诉我们答案。
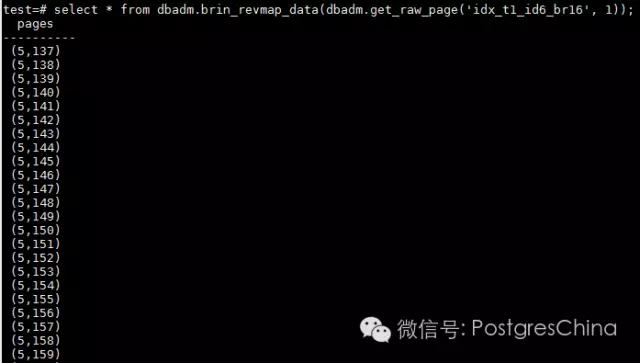
这个数据告诉我们,0-15heap page对应的BRIN索引条目是从索引的regularpage 5并且第137个条目开始的。根据revmappage的指示我们可以对BRIN索引regular page中的顺序获得完全的了解。
之前提到,根据不同的pages_per_range设置,在id6字段上总共创建了8个不同的BRIN索引。我们不再一一分析,这里再看另外一个极端的例子,就是pages_per_range=2048的情况。剩下的如果大家有兴趣,可以自行构造数据进行分析。
- 首先,还是meta page,pagesperrange应该是2048;
- 由于pages_per_range是2048,所以需要的BRIN索引条目是ceiling(73530/2048::decimal)=36,只需一个revmap page就可以涵盖;
- 至于regular page的数量,由于只需要36个索引条目,而一个BRIN的regular page可以管理408个条目,因此也只需要一个regular page就可以涵盖t1表所有的heap page;
- 因此,idx_t1_id6_br2048索引的page数量是1+1+1=3;
来看一下实际情况是否如此:
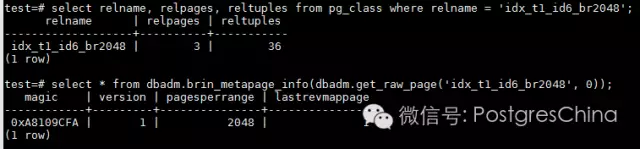
这个BRIN索引总共3个page,索引条目是36个,与前面分析的一致。
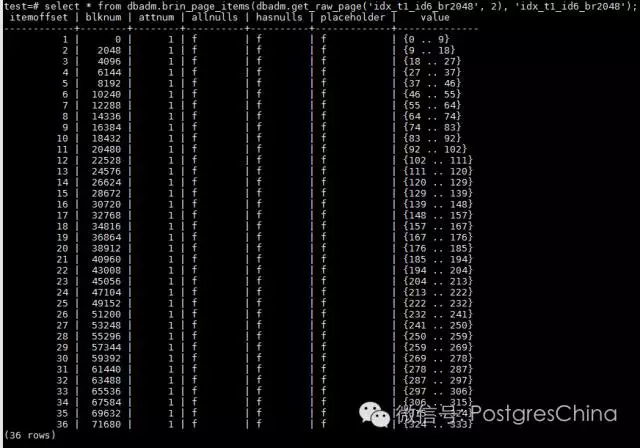
从regularpage的索引条目上来看,由于一个条目涵盖了2048个heappage,而一个heap page可以存放136个数据行,因此一个条目相当于涵盖278,528行数据对应字段的值。拿第一个条目来说明,value存放的最小值和最大值范围是在0和floor(2048*136/30000)=9之间,实际的数据也证明了这一点。

https://zulin.tiancebbs.cn/sh/205.html https://changshushi.tiancebbs.cn/hjzl/460008.html https://zulin.tiancebbs.cn/sh/1318.html https://www.tiancebbs.cn/ershouwang/471691.html https://bynr.tiancebbs.cn/qths/469653.html https://jiaozuo.tiancebbs.cn/qths/472034.html https://changshushi.tiancebbs.cn/hjzl/461535.html https://aihuishou.tiancebbs.cn/sh/3247.html https://www.tiancebbs.cn/ershoufang/467980.html https://changshushi.tiancebbs.cn/hjzl/460098.html https://zulin.tiancebbs.cn/sh/1100.html https://taicang.tiancebbs.cn/hjzl/456816.html https://zulin.tiancebbs.cn/sh/2917.html https://changshushi.tiancebbs.cn/hjzl/461484.html https://zulin.tiancebbs.cn/sh/5064.html https://px.tiancebbs.cn/qths/460790.html https://sh.tiancebbs.cn/hjzl/458422.html
https://dl.tiancebbs.cn/qths/468856.html https://tl.tiancebbs.cn/qths/468833.html https://aihuishou.tiancebbs.cn/sh/4767.html https://hn.tiancebbs.cn/qths/452029.html https://aihuishou.tiancebbs.cn/sh/4346.html https://zulin.tiancebbs.cn/sh/3668.html https://yuanchengqu.tiancebbs.cn/qths/468417.html https://zulin.tiancebbs.cn/sh/3155.html https://su.tiancebbs.cn/qths/471046.html https://changshushi.tiancebbs.cn/hjzl/461474.html https://xinyu.tiancebbs.cn/qths/470428.html https://aihuishou.tiancebbs.cn/sh/3147.html https://su.tiancebbs.cn/hjzl/470216.html https://zulin.tiancebbs.cn/sh/4122.html https://aihuishou.tiancebbs.cn/sh/3903.html https://www.tiancebbs.cn/ershouwang/471626.html https://taicang.tiancebbs.cn/qths/467827.html
研究生自我鉴定:https://www.nanss.com/xuexi/736.html 诗情画意的网名:https://www.nanss.com/mingcheng/928.html 师德总结:https://www.nanss.com/gongzuo/707.html 好书推荐及理由:https://www.nanss.com/xuexi/1158.html 论文致谢万能模板:https://www.nanss.com/xuexi/767.html 简短有意义的ID:https://www.nanss.com/mingcheng/624.html 好听网名大全:https://www.nanss.com/mingcheng/1398.html 战队名字:https://www.nanss.com/mingcheng/945.html 正能量又不俗的小组名:https://www.nanss.com/xuexi/748.html 工作述职:https://www.nanss.com/gongzuo/606.html 女人气质昵称:https://www.nanss.com/mingcheng/920.html 押韵的网名:https://www.nanss.com/mingcheng/1236.html 让人一看就舒服的网名:https://www.nanss.com/mingcheng/572.html 校园里的甜:https://www.nanss.com/xuexi/970.html 我以为我可以的句子:https://www.nanss.com/wenan/1275.html 游戏靓名:https://www.nanss.com/mingcheng/1453.html 广场设计说明:https://www.nanss.com/shenghuo/545.html 岁岁年年的唯美句子:https://www.nanss.com/yulu/1264.html 王者荣耀好听的昵称:https://www.nanss.com/mingcheng/998.html 高考加油成语:https://www.nanss.com/xuexi/886.html 毕业祝福语:https://www.nanss.com/yulu/765.html 女生可爱游戏名字:https://www.nanss.com/mingcheng/1439.html 非主流女名字:https://www.nanss.com/mingcheng/1182.html 爱人昵称:https://www.nanss.com/mingcheng/1359.html 课后反思:https://www.nanss.com/gongzuo/737.html 经典团队口号:https://www.nanss.com/gongzuo/1150.html 好听的花名:https://www.nanss.com/shenghuo/508.html 应用文写作课程总结:https://www.nanss.com/xuexi/537.html 两个字的游戏名:https://www.nanss.com/mingcheng/951.html 神id:https://www.nanss.com/mingcheng/1318.html