
作者:汪洋(平安科技数据库技术部经理)
作者简介:
汪洋,中国平安集团旗下平安科技数据库技术部总监。从1994年开始接触Oracle 6数据库,于1998年获取Oracle 7.3 OCP证书,迄今已从事Oracle相关开发运维工作20年。在加入平安之前,就职于Oracle香港高级客户服务部门,为中国、香港以及澳门客户提供数据库架构设计,数据库性能优化等高级服务。加入平安后,负责数据库技术引入,数据库产品选型,数据库架构设计,数据库规范制定,开发、测试、生产环境运维等工作。近年,对开源数据库技术以及DBaaS产生浓厚兴趣,一直致力于相关的研究和引入工作。
PostgreSQL 9.5引入了Block Range Index,简称BRIN,用于字段值和在表中的物理位置具有一定关联关系的大数据量访问。但是BRIN对于不同数据分布带来的性能提升有多少,和传统的BTREE索引比较性能又有什么差别,恐怕大家还没有一个直观的印象。本文将就这些问题尝试给出一些解答,希望可以帮助大家在选择BTREE或者BRIN时不再那么纠结,有据可依。
为了能够在一致的环境中评估BRIN和BTREE对数据访问的差异,使用了两张完全相同的表。它们的结构相同,数据量相同,字段上的数据分布也完全一致,唯一不同的就是一张表上为每个字段创建的都是BRIN类型索引,而另一张表上都是BTREE类型索引。
详细信息如下:
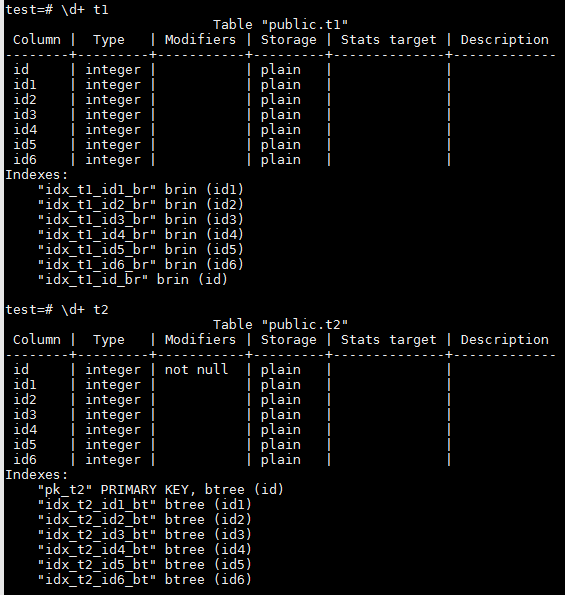
两张表t1和t2的数据是用以下数据来插入,已获得在各个字段上不同的数据分布:
insert into t1 select id, mod(id, 100), round(id/100), mod(id, 1000), round(id/1000), mod(id,30000), round(id/30000) from generate_series(1, 10000000) id; insert into t2 select id, mod(id, 100), round(id/100), mod(id, 1000), round(id/1000), mod(id,30000), round(id/30000) from generate_series(1, 10000000) id;
- 表数据量是1000万;
- id字段是顺序增长;
- id1是100取模,id2是除以100然后取整;
- id3是1000取模,id4是除以1000然后取整;
- id5是30000取模,id6是除以30000然后取整;
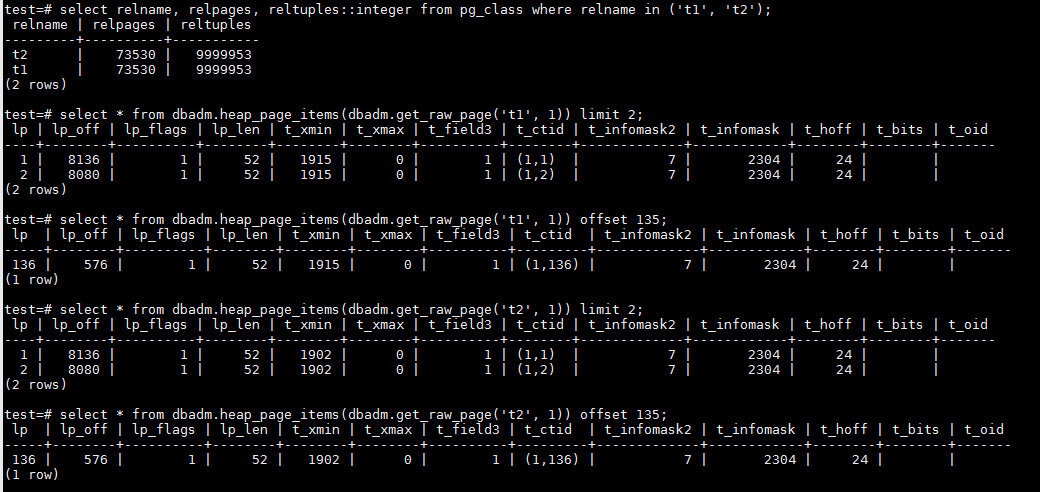
从pageinspect来看,数据在两张表中的存储也是完全相同的,每个page存放136条记录。
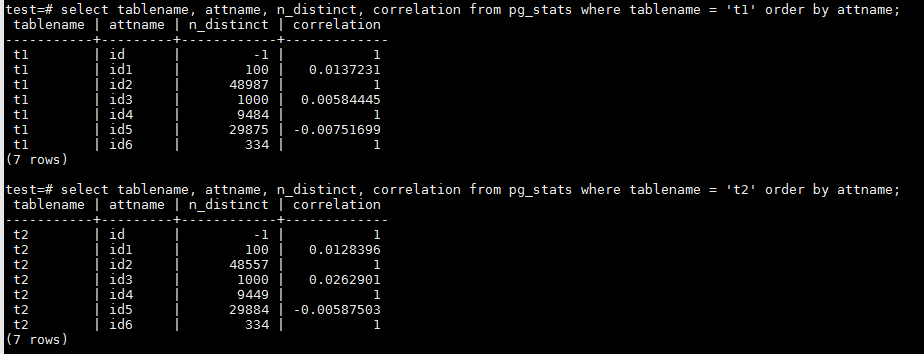
可以看到,虽然结构、数据量和数据分布完全相同,但vacuum analyze之后统计信息由于取样的原因还是稍有不同,属于正常现象。不是100%精确。 但BRIN和BTREE索引在大小上却有天壤之别,BRIN相比BTREE索引在空间占用上小很多。
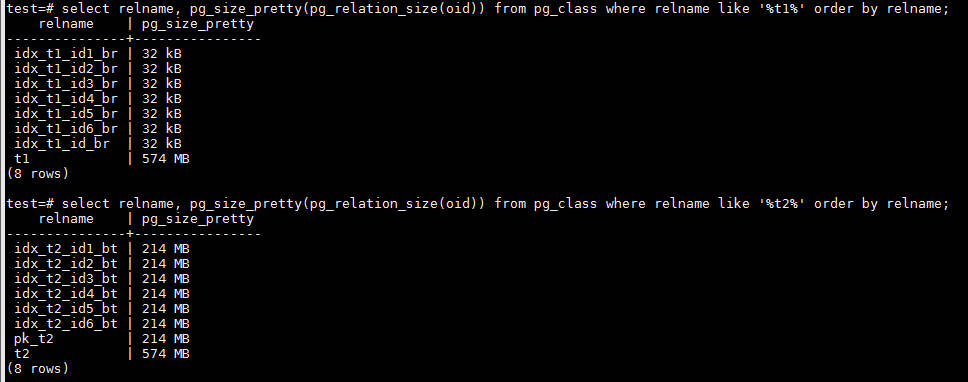
表的大小一样,都是574MB。但每个字段上BRIN索引只有32KB,而相应的BTREE索引却占据214MB空间,是BRIN索引的6848倍!这里不讲BRIN索引的存储方式,留待以后专题讨论。本文只关注两种索引类型大小的巨大差异和表中各字段不同的数据分布。
我们先来看一下不同数据分布下等值查询的情况。需要指出的是,除了id字段外,其他字段值不是唯一的,所以等值查询也会出现范围扫描。
1、首先是在id字段上的等值查询
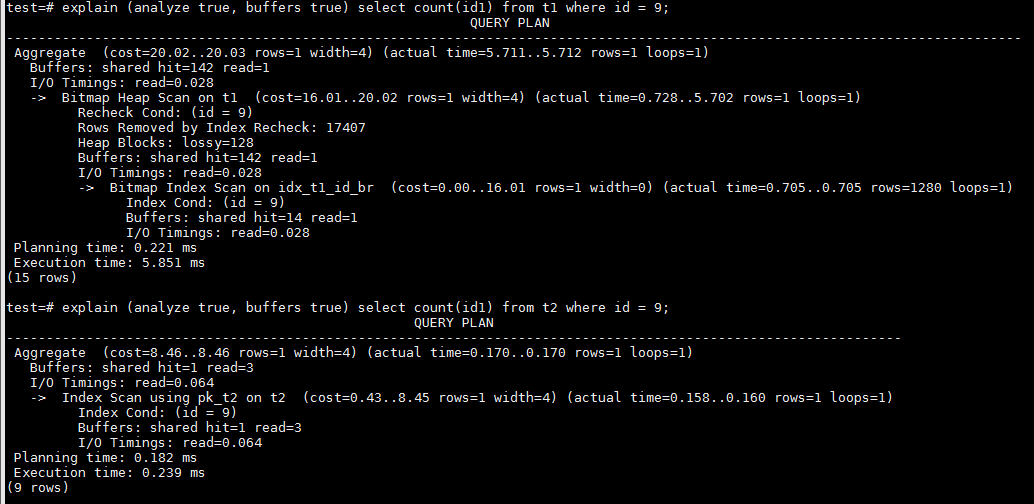
id字段是顺序增加,所以是唯一的。由于是唯一扫描,BTREE的性能应该是好的。而BRIN因为其的Lossy特性,需要扫描更多的数据页。BRIN缺省是128个数据页面做为一个范围,所以即算是等值查询,最少也需要扫描128个heap页面。从实际性能数据上看,通过BRIN索引运行查询访问了143个buffer,而BTREE只有4个buffer,效率很高。BTREE的执行时间也比BRIN要少很多。因此,对于等值的唯一查询,BTREE在性能上有显著优势。
2、在id1上的等值查询。前面讲过,由于值不唯一,实际上是范围扫描。而且由于id1字段对100取模的关系,几乎每个数据页面都包含9这个值。也就是说,无论BRIN还是BTREE,都要访问几乎所有的数据块。我们来看一下性能的实际表现。
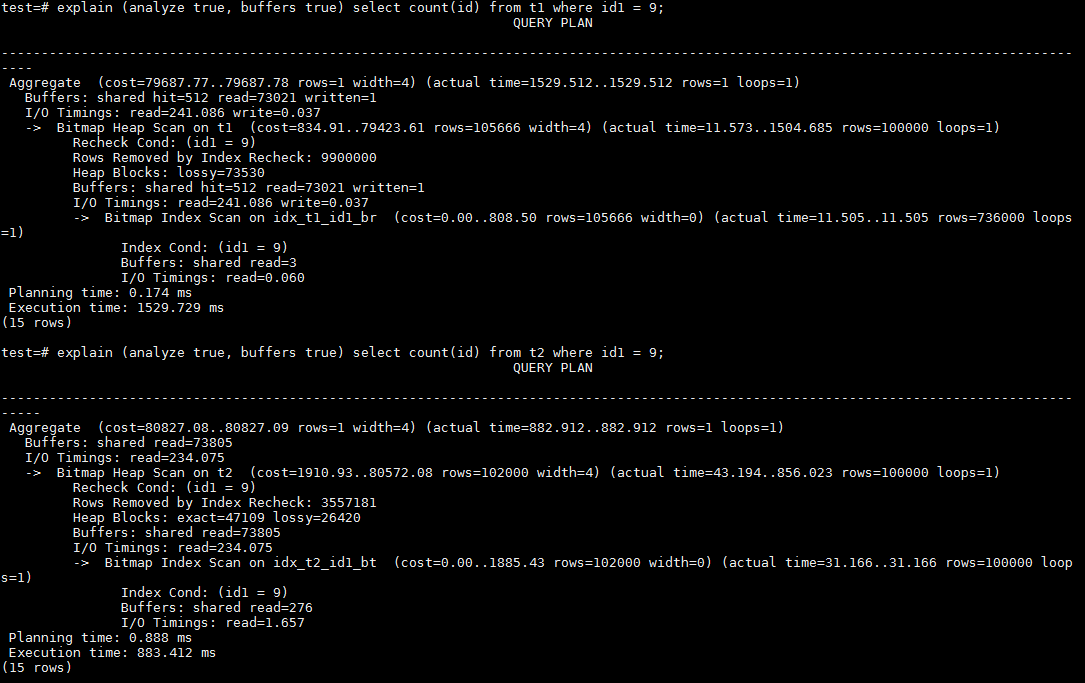
可以看到,确实每个heap的数据块都被访问到了。而且,由于BTREE结构比较大的原因,比BRIN在索引上还多扫描了270个数据块。本文中,也不打算论述访问数据块个数的精确差异,只要知道大概就可以。但BTREE的访问效率依然较高,这是为什么?BRIN执行计划中多余的时间很有可能是消耗在CPU上,由于BRIN是lossy索引,还需要对访问的数据进行精确匹配,做过滤操作;而BTREE只需通过访问路径即可查找到匹配的数据,因此性能较高。
3、在id2上的等值查询。id2是除以100后取整,所以等值查询也是范围扫描。id2是以一定重复的值顺序递增。BRIN和BTREE都只需访问较少的数据页。
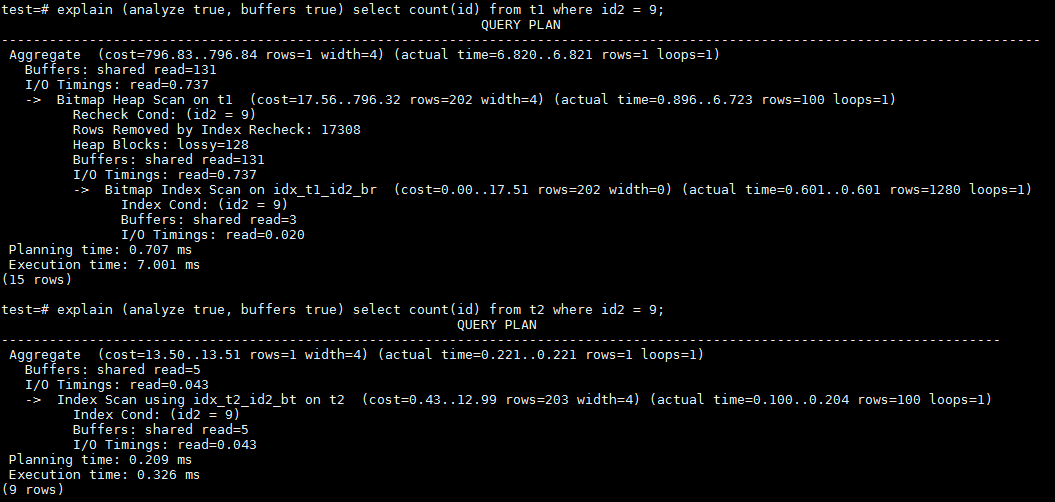
在这种情况下,BTREE仍然具有较明显的性能优势。重复值较少,所以BTREE只需访问很少的buffer,在本例中是5个buffer;而BRIN缺省就是128个heap page范围,所以最少也需要访问128个heap page,本例中访问了131个buffer。
4、在id3上的等值查询。id3是对1000取模,并不是每个数据块都包含9这个值。通过BTREE可以访问较少的buffer。由于BRIN是128个heap page做为一个范围单位,在一个范围单位里面还是会出现9这个值。也就是说,通过BRIN还是会访问到所有heap page。从这点来看,BTREE还是具有较大优势。我们来看实际情况是否如此。
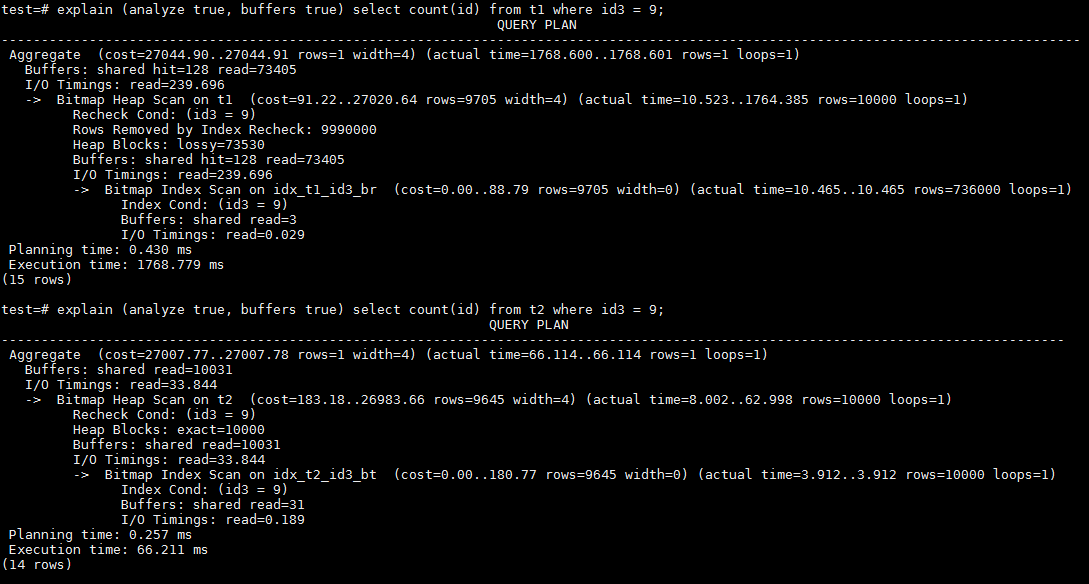
可以看到,通过BRIN的执行SQL查询访问了73533个buffer,而通过BTREE的执行只访问了10031个buffer。从执行时间上,BTREE也是具备明显的优势,是BRIN性能的21倍。
5、再来看id4上的等值查询。id4是除以1000后取整,是以更多重复的值顺序增加。来看一下实际运行的数据。
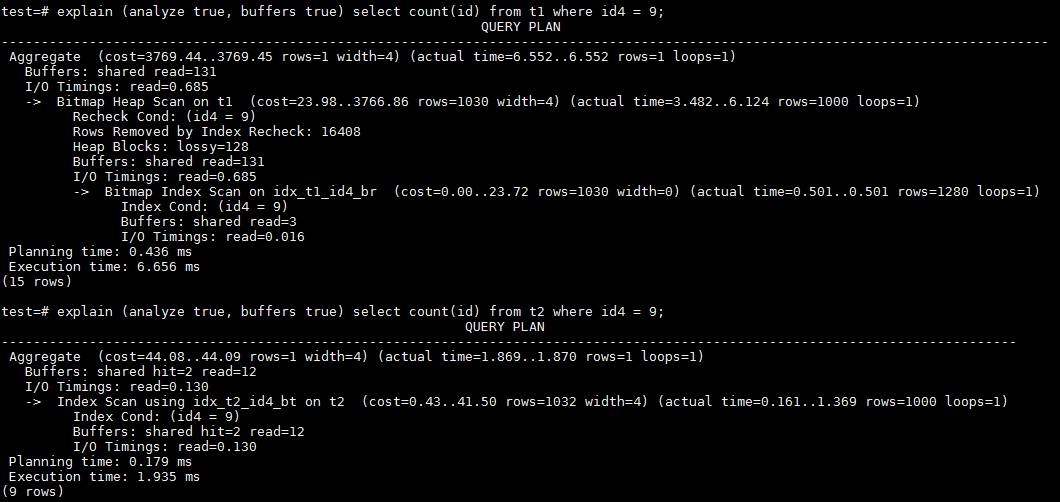
虽然由于除以1000的关系,id4以更大的重复度顺序增加,但依然没有超过BRIN缺省128个heap page的范围,所以访问的buffer还是131个。而BTREE却因为重复值的增加而扫描了更多的buffer,达到14个。比之前的id2(除以100后取整)多了7个buffer的访问。但相比BRIN的性能优势还是比较明显。
我们可以想象,如果再增加值的重复度,例如除以2000、3000,两者性能差距会逐渐缩小。BRIN还是在一个范围之内,也就是128个heap page;而BTREE因为重复值的增加所需要访问的index page和heap page数量都会增加。
6、再来看id5上的等值查询。id5使用了一个比较大的数值30000来取模。一个BRIN范围是128,而一个heap page中有136个数据行,因此一个BRIN可以涵盖17408行字段上的值。换句话说,并不是每个BRIN单位都含有9这个值,BRIN可以减少buffer的访问量。而BTREE因为唯一值数量的增加,也会访问较少的buffer。来看看实际运行性能孰优孰劣。
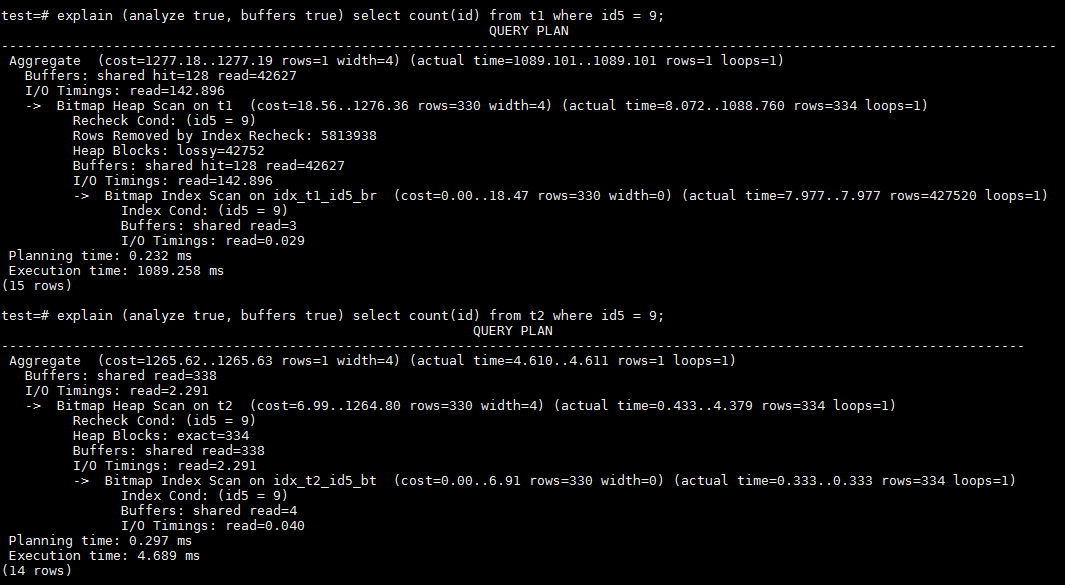
可以看到,正如前面预测的一样。通过BRIN执行的语句本次不用再访问所有的heap page,访问的buffer数量相比之前取模的分布情况减少到42755。而BTREE也比之前id3通过1000取模的情况大幅减少,从10031降低到338。从执行时间的性能数据上来看,BTREE仍然具有明显的优势,是BRIN的265倍!
7、最后我们来看一下id6上的等值查询情况。id6通过除以30000后取整获得。按照第5点的分析,BRIN和BTREE的查询在此种数据分钟下性能差距会缩小,看看是否如此。
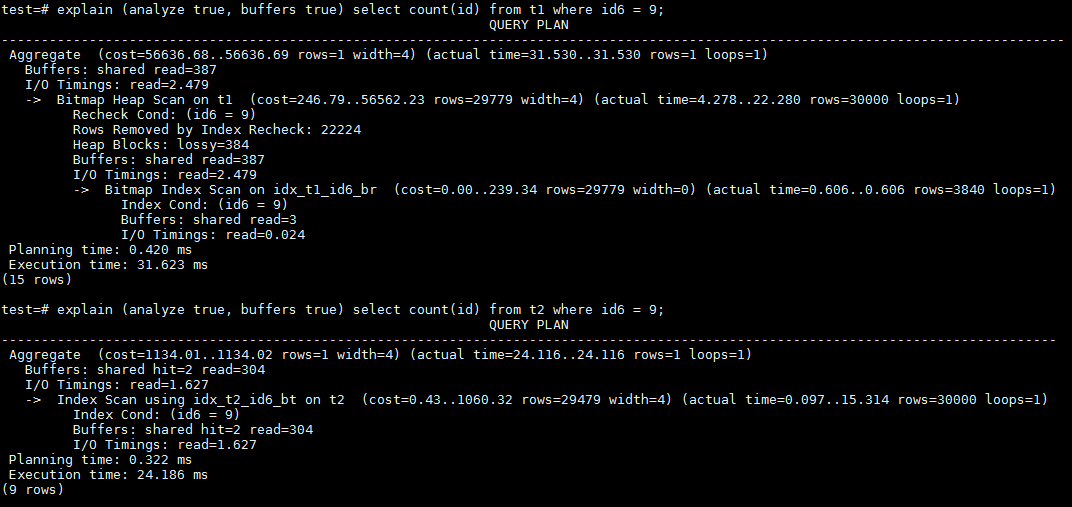
果然,二者的性能差距在本例中已经基本持平。BRIN由于值重复度的进一步增加,需要访问3个BRIN单位,最终需要访问387个buffer;而BTREE由于重复值的增加,buffer的访问数量也增加到了306个,已经非常接近BRIN。
- 总结:
- BRIN索引和BTREE索引相比,在存储空间占用上具备巨大优势。本例中达到6848倍!对于数据仓库或者VLDB应用可以节省大量的存储成本。
- 本文给出并分析了7中不同的数据分布,在等值查询情况下,所有的场景BTREE的性能都优于BRIN索引。但在不同数据分布情况下,BTREE在性能上的领先优势差别非常大,从不到1倍到265倍。
- 在选择创建BRIN还是BTREE索引时,需要权衡性能和空间使用两方面的影响。根据数据量、数据分布和SQL选择最适合的索引类型。在性能相差不大的情况下,选择BRIN可能是更加经济的选择。总体来说,当实际匹配数据量较少时,BTREE索引更加适合;反之,BRIN更加适合。
- 由于BRIN索引的lossy特性,需要消耗较多的CPU时间用于精确匹配。
- BRIN索引的引入无疑给数据访问开辟了一条新的途径,使得PG的功能更加丰富。期望Oracle也能够将功能类似的Storage Index早日引入到其非Exadata数据库版本中。

以幸福为题的作文:https://www.deipei.com/zuowen/940.html 以诚信为话题的作文:https://www.deipei.com/zuowen/951.html 我的教练作文:https://www.deipei.com/zuowen/892.html 答辩自述:https://www.deipei.com/shixibaogao/937.html c语言学习心得:https://www.deipei.com/xuexi/729.html 小学足球训练计划:https://www.deipei.com/jihua/770.html 职工思想动态分析:https://www.deipei.com/gongzuo/877.html 奇遇记作文:https://www.deipei.com/zuowen/952.html 新娘婚礼致辞:https://www.deipei.com/yanjianggao/709.html 社会实践自我鉴定:https://www.deipei.com/ziwojianding/640.html 党员思想汇报材料:https://www.deipei.com/yanjianggao/637.html 优秀班主任事迹材料:https://www.deipei.com/shijicailiao/993.html 即景作文:https://www.deipei.com/zuowen/994.html 教师辞职信:https://www.deipei.com/fanwen/1004.html 专业技术人员年度考核个人总结:https://www.deipei.com/zongjie/976.html 人与自然作文:https://www.deipei.com/zuowen/606.html 下月工作计划:https://www.deipei.com/jihua/602.html 建材购销合同:https://www.deipei.com/hetong/824.html 安全生产工作总结:https://www.deipei.com/zongjie/708.html 保密工作自查报告:https://www.deipei.com/shuzhibaogao/799.html 履职总结:https://www.deipei.com/zongjie/641.html 会议通知范文:https://www.deipei.com/fanwen/773.html 致我们逝去的童年作文:https://www.deipei.com/zuowen/845.html 个人发展规划:https://www.deipei.com/fanwen/595.html 中国古代故事:https://www.deipei.com/yuedu/597.html 巨人的花园教学反思:https://www.deipei.com/jiaoxue/961.html 保洁合同:https://www.deipei.com/hetong/982.html 装修合同书:https://www.deipei.com/hetong/999.html 高中班主任工作计划:https://www.deipei.com/jihua/1003.html 演出合同:https://www.deipei.com/hetong/923.html
特殊情侣网名:https://www.nanss.com/mingcheng/1317.html 小作文:https://www.nanss.com/xuexi/561.html qq昵称女生:https://www.nanss.com/mingcheng/783.html 失恋昵称:https://www.nanss.com/mingcheng/1394.html 淡然心静的昵称:https://www.nanss.com/mingcheng/655.html 独一无二的霸气女网名:https://www.nanss.com/mingcheng/894.html 工作经验证明:https://www.nanss.com/gongzuo/1129.html 好听的情侣网名一对:https://www.nanss.com/mingcheng/1379.html 冬至的美好寓意:https://www.nanss.com/shenghuo/1147.html 动漫人物名字:https://www.nanss.com/mingcheng/971.html qq昵称大全:https://www.nanss.com/mingcheng/1314.html 对妈妈爱的表达短句子:https://www.nanss.com/yulu/1322.html 姓郭的名人:https://www.nanss.com/shenghuo/1143.html 光盘行动倡议书:https://www.nanss.com/xuexi/647.html 小学班主任工作总结:https://www.nanss.com/gongzuo/1160.html 好听的家族名字:https://www.nanss.com/mingcheng/1190.html 爱一个人的句子情话大全:https://www.nanss.com/yulu/1064.html 银行面试自我介绍:https://www.nanss.com/gongzuo/908.html 说说文案干净治愈:https://www.nanss.com/yulu/747.html 好听的情侣网名大全:https://www.nanss.com/mingcheng/1459.html 狼人战士名字:https://www.nanss.com/mingcheng/1243.html 有深度的网名:https://www.nanss.com/mingcheng/1210.html 网名男生霸气:https://www.nanss.com/mingcheng/546.html 家族群名:https://www.nanss.com/mingcheng/616.html 你画我猜题目:https://www.nanss.com/shenghuo/830.html 非主流幸福网名:https://www.nanss.com/mingcheng/1089.html 可爱名字:https://www.nanss.com/mingcheng/518.html 女生网名两个字:https://www.nanss.com/mingcheng/864.html 一切都是过眼云烟:https://www.nanss.com/shenghuo/1053.html 含义网名:https://www.nanss.com/mingcheng/1362.html