
作者:汪洋(平安科技数据库技术部经理)
作者简介:
汪洋,中国平安集团旗下平安科技数据库技术部总监。从1994年开始接触Oracle 6数据库,于1998年获取Oracle 7.3 OCP证书,迄今已从事Oracle相关开发运维工作20年。在加入平安之前,就职于Oracle香港高级客户服务部门,为中国、香港以及澳门客户提供数据库架构设计,数据库性能优化等高级服务。加入平安后,负责数据库技术引入,数据库产品选型,数据库架构设计,数据库规范制定,开发、测试、生产环境运维等工作。近年,对开源数据库技术以及DBaaS产生浓厚兴趣,一直致力于相关的研究和引入工作。
本文为BRIN和BTREE索引讨论系列之二。在前面的文章中根据表中不同的数据分布比较了BRIN和BTREE索引在大小和查询性能上的差异,希望对大家在选择使用BRIN还是BTREE索引时有所帮助。
系列一的结论指出,BTREE相比BRIN索引的结构庞大,但在测试的各种数据分布情况下查询性能较好,虽然有时性能差异不是太大;反之BRIN虽然结构精简,但查询性能却不如BTREE,特别是所需访问数据量较小时性能和BTREE有巨大差异。那么有没有可能鱼和熊掌兼得呢?既可以获得BTREE在小数据量查询下的高性能,同时又可以使用BRIN的精简结构进行大数据量的查询,还能够节省巨大的存储空间,这该是多好的一件事情!Bring the best of both worlds! 有没有可能呢?答案是肯定的!
在PG中,有一个特性叫Partial Indexes。这也正是PG强大且灵活的地方。通过使用这个特性,在特定的数据分布下,我们就可以享受BRIN带来的空间节省以及BTREE带来的高查询性能。先简单解释一下什么是Partial Indexes,普通的索引需要对表的所有行对应的索引字段建立索引,而Partial顾名思义,只对表的一部分子集对应的索引字段建立索引,而且这个子集可以写过滤条件(Predicate)来自己定义。根据这个条件创建出来的索引,条目中也就只包含了满足过滤条件的字段值。什么时候需要用到Partial Index?是在字段中数据存在Data Skew,我们常说的分布不均情况下。大家都知道,如果一个字段上distinct值越多,density越小,我们说索引的selectivity就越高,使用BTREE类型的索引查询性能就越高;反之通过BTREE的查询性能会下降。当一个字段上出现高频值的时候,是没有必要对这个高频出现的值建立索引条目的,既浪费存储空间又起不到提升查询性能的效果。很多情况下,还会导致性能下降,引起并发竞争等问题。如果不对这些高频值建立索引,还能够提升数据库中DML语句的执行性能。一般来讲,一个表上的索引越多,虽然查询性能能够获得一定提升,但DML语句的执行性能会越差,因为需要维护对应的索引结构。如果连查询性能都提升不了,就更没有必要建立索引了。Partial Index正是针对这种情况而设计的。
回到本文的主题,我们构造了一个数据严重偏移的数据分布情况。表中有10,000,000的数据量,在id1这个字段上总共有100个唯一值,但1-99这些值只重复了10次;而id1=100却有9,999,010行,占了总数据量的99.9901%。很明显,对于id1=100这个值使用BTREE索引是完全没有必要的,不仅会消耗大量的存储空间,也无法带来查询性能的提升。这正是Partial Index适用的场景。
表和数据的构造语句如下图所示:
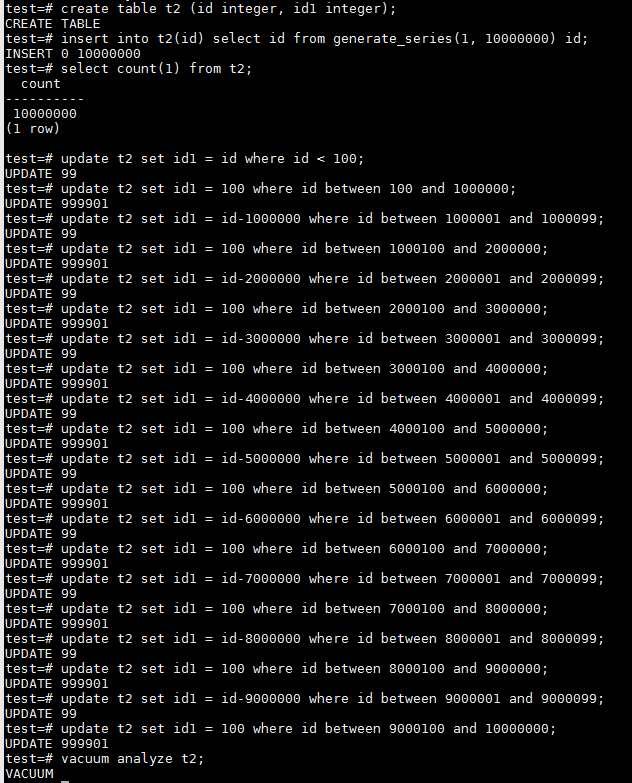




可以看到,构造完毕后。
- 普通的BTREE索引idx_t2_id1_bt_in占用了214MB的空间;
- 而排除了id1=100的Partial BTREE Index idx_t2_id1_bt只使用了40KB;
- 普通的BRIN索引idx_t2_id1_br占用了24KB的空间;
- 只包含了id1=100的Partial BRIN Index idx_t2_id1_br_ex也是使用了24KB,没有差别;
到这里,大家可能已经知道了我们如何鱼和熊掌兼而得之!通过创建Partial BTREE Index,可以排除不必要的高频值,从而大幅减少存储空间的使用,同时获得对低频值的高性能查询;而通过建立BRIN索引,可以获得对大批量数据访问的性能提升。
我们来看一下实际的查询执行性能情况:

在id1=99时,由于是一个低频值,在Partial BTREE Index idx_t2_id1_bt中有对应的索引条目,PG优化器选择走索引,只需要访问11个buffer,执行时间也只有0.246ms。
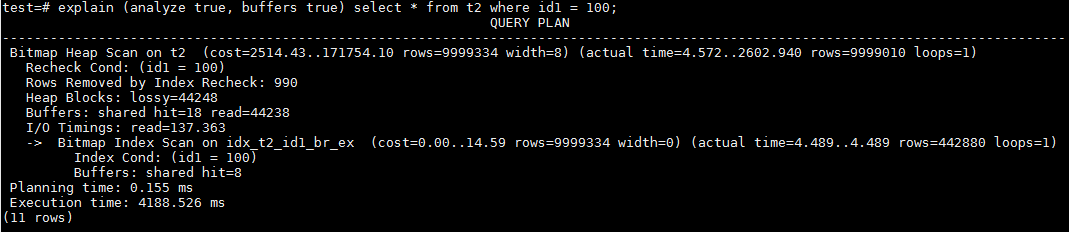
而在id1=100时,优化器选择走了Partial BRIN Index idx_t2_id1_br_ex,访问了表t2所有的heap page,Lossy=44248。加上扫描BRIN的buffer,总buffer数量是44256。这是正常的,前面提到id1=100的行占据了总数据量的99.9901%。

再看一下使用普通BRIN索引的情况,由于id1在0到99之间值很少,所以对最终结果影响不大。还是扫描了表t2所有的heap page,lossy=44248。扫描BRIN的buffer变成了2,最终总扫描buffer数量是44250。
总结:
- 通过在特定的数据分布下使用PG的Partial BTREE Index特性和BRIN索引,既可以做到索引空间的大量节省,又可以实现对不同频率数据的高性能访问。在本例中,如果采用普通BTREE和BRIN索引,空间使用是560MB;而使用Partial BTREE Index和BRIN,空间使用则只有346MB,索引使用空间基本忽略不计。借助PG的灵活性,鱼和熊掌可以兼得!
- 本例中为了说明Partial BTREE Index和BRIN的完美结合带来了空间和性能的双重收益,构造了很特别的数据分布,并不能代表真实应用场景。通过本文是想告诉大家,PG带给我们其他数据库产品所不具备的特性,在进行应用设计时,提供给了我们更大的想象空间。在特定的场景下,通过同时使用Partial Index和BRIN索引,能够有意想不到的收获。

https://bjnancheng.tiancebbs.cn/ http://wutai.cqtcxxw.cn/chengde/ http://shenghuo.china-bbs.com/scab/ https://gongchen.tiancebbs.cn/ http://wutai.cqtcxxw.cn/kashi/ http://bjtcxxw.cn/jzq/ http://fs.shtcxxw.cn/huaibei/ https://yamingshan.tiancebbs.cn/ http://js.sytcxxw.cn/jlcc/ http://taiying.njtcbmw.cn/sfc/ https://huidong.tiancebbs.cn/ http://km.lstcxxw.cn/guyuan/ https://xidan.tiancebbs.cn/ http://yz.cqtcxxw.cn/tjnk/ http://shimai.zjtcbmw.cn/yu-lin/ http://taiying.njtcbmw.cn/lsgjz/ https://fschanyeyuan.tiancebbs.cn/
环境保护作文:https://www.deipei.com/zuowen/987.html 家访工作总结:https://www.deipei.com/zongjie/619.html 火灾事故报告:https://www.deipei.com/shuzhibaogao/768.html 六年级下学期班主任工作总结:https://www.deipei.com/zongjie/561.html 白鹅教学设计:https://www.deipei.com/jiaoxue/759.html 亲情文章:https://www.deipei.com/yuedu/728.html 骨干教师培养计划:https://www.deipei.com/jihua/518.html 志愿军观后感:https://www.deipei.com/guanhougan/669.html 工作经验交流发言稿:https://www.deipei.com/yanjianggao/850.html 活动策划案例:https://www.deipei.com/fangan/1031.html 收入证明模板:https://www.deipei.com/fanwen/658.html 中国传统文化故事:https://www.deipei.com/yuedu/554.html 小学信息技术教学总结:https://www.deipei.com/zongjie/623.html 讲座开场白:https://www.deipei.com/yanjianggao/636.html 以成长为话题作文:https://www.deipei.com/zuowen/929.html 作文600字:https://www.deipei.com/zuowen/957.html 安全保卫管理制度:https://www.deipei.com/gongzuo/539.html 哲理散文:https://www.deipei.com/yuedu/614.html 职称评定工作总结:https://www.deipei.com/zongjie/723.html 节日作文600字:https://www.deipei.com/zuowen/572.html 毕业实习报告:https://www.deipei.com/shixibaogao/672.html 上学的路上作文:https://www.deipei.com/zuowen/882.html 教育家精神心得体会:https://www.deipei.com/xindetihui/983.html 我最喜欢的季节作文:https://www.deipei.com/zuowen/703.html 领导讲话心得体会:https://www.deipei.com/xindetihui/886.html 学期工作计划:https://www.deipei.com/jihua/566.html 优秀作文范文:https://www.deipei.com/zuowen/947.html 教师教学反思:https://www.deipei.com/gongzuo/890.html 汉字的研究报告:https://www.deipei.com/xuexi/746.html 新教师述职报告:https://www.deipei.com/shuzhibaogao/514.html
音乐说课稿:https://www.nanss.com/gongzuo/559.html 伤感名字男生:https://www.nanss.com/mingcheng/843.html 女性游戏名字:https://www.nanss.com/mingcheng/1197.html 感谢老师的话:https://www.nanss.com/yulu/1124.html 游戏名称:https://www.nanss.com/mingcheng/895.html 好记的网名:https://www.nanss.com/mingcheng/1405.html 游戏角色名大全:https://www.nanss.com/mingcheng/1200.html 文案句子治愈:https://www.nanss.com/xuexi/773.html 努力的句子:https://www.nanss.com/xuexi/525.html 自我陈述报告高中800字:https://www.nanss.com/xuexi/595.html 四月一号的朋友圈说说:https://www.nanss.com/wenan/1492.html 夏天的句子短句唯美:https://www.nanss.com/yulu/1298.html 男生霸气网名:https://www.nanss.com/mingcheng/1218.html 网络昵称大全:https://www.nanss.com/mingcheng/680.html 王者荣耀有意思的名字:https://www.nanss.com/mingcheng/959.html 个性繁体网名:https://www.nanss.com/mingcheng/1397.html 励志网名:https://www.nanss.com/mingcheng/702.html 抖音名字昵称好听:https://www.nanss.com/mingcheng/933.html 温柔干净的网名英文:https://www.nanss.com/mingcheng/535.html 简单好听的微信名:https://www.nanss.com/mingcheng/769.html 和平精英名字大全:https://www.nanss.com/mingcheng/904.html 学校安全教育制度:https://www.nanss.com/gongzuo/1351.html 餐厅名:https://www.nanss.com/shenghuo/1140.html 演讲题目:https://www.nanss.com/xuexi/650.html 饭局开场白:https://www.nanss.com/shenghuo/687.html 体育教学反思:https://www.nanss.com/gongzuo/523.html 嗓子哑了的说说:https://www.nanss.com/wenan/1075.html 唯美句子大全:https://www.nanss.com/wenan/1274.html 听课记录模板范文:https://www.nanss.com/gongzuo/585.html 比较好的微信号id号:https://www.nanss.com/mingcheng/907.html