
作者:汪洋(平安科技数据库技术部经理)
作者简介:
汪洋,中国平安集团旗下平安科技数据库技术部总监。从1994年开始接触Oracle 6数据库,于1998年获取Oracle 7.3 OCP证书,迄今已从事Oracle相关开发运维工作20年。在加入平安之前,就职于Oracle香港高级客户服务部门,为中国、香港以及澳门客户提供数据库架构设计,数据库性能优化等高级服务。加入平安后,负责数据库技术引入,数据库产品选型,数据库架构设计,数据库规范制定,开发、测试、生产环境运维等工作。近年,对开源数据库技术以及DBaaS产生浓厚兴趣,一直致力于相关的研究和引入工作。
本文是针对PostgreSQL 9.5推出的新索引类型BRIN如何在实际中运用的系列之三。前面两篇一篇是分析在不同数据分布下BTREE和BRIN索引在空间和查询性能上的不同表现;第二篇是介绍在某些数据分布不平均的场景下,如何同时使用BTREE和BRIN索引来获得查询性能的提升和存储空间的有效利用。本文将集中在对BRIN索引自身的使用上。
在一篇分析BRIN索引存储结构的文章中提到,一个BRIN索引主要分为三大部分:metadata page,revmap page和regular page。而regular page是BRIN索引的核心,正是通过查询在regular page中的BRIN索引条目,能够在进行大量数据访问的时候提升查询性能。那么BRIN的索引条目是如何提升查询性能的呢?每一个条目除了给出所涵盖的heap page范围中最大值和最小值之外,还包含了两个关键的信息。一个是allnulls,还有一个是hasnulls。拿缺省的pages_per_range=128为例:
- allnulls是告诉我们在一个条目涵盖的128个heap page对应的索引字段上是否全部为NULL值;
- hasnulls顾名思义,告诉我们在一个条目涵盖的128个heap page对应的索引字段上是否含有NULL值。但不全是NULL;
今天我们就来看一下查询时执行器是如何利用BRIN索引上的这两个信息过滤掉不需要访问的heap page,从而提升查询性能。
先来构造我们的案例,创建一张表,并且插入2,000,001行记录。其中id字段是顺序递增的;id1字段的值绝大部分和id相同,存在少许NULL值,用于创建BRIN索引。具体如下图:
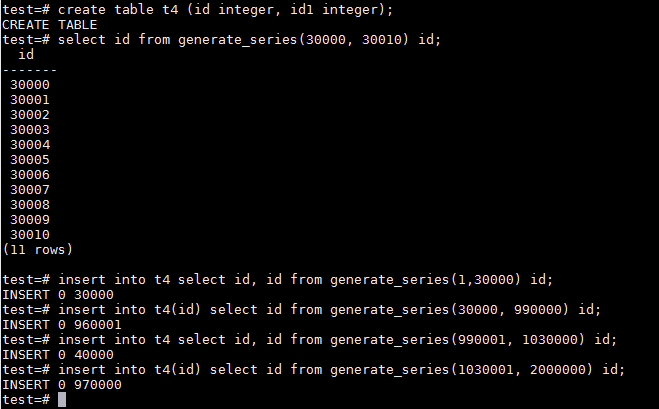
id1字段上的BRIN索引按缺省的pages_per_range=128创建,这点可以从下面的BRIN索引metapage中看到。

再来看一下BRIN索引regular page中的索引条目信息,请留意allnulls和hasnulls对应的值。在我们构造的案例中:
- blocknum=0,也就是heap page 0 – 128的allnulls是f,hasnulls也是f,说明在这128个heap page中,id1全部都是非空值;
- 而blocknum等于128,4352和4480的索引条目上,allnulls是f,hasnulls是t,代表在这384个heap page中,id1字段上包含有空值,但也有非空值;
- 其余所有的索引条目都是allnulls是t,hasnulls是f。在这些heap page上,id1字段全部是空值;
- 在前面1、2点加起来的512个heap page中,由于id1都存在非空值,所以对应索引条目也存在最大值和最小值;
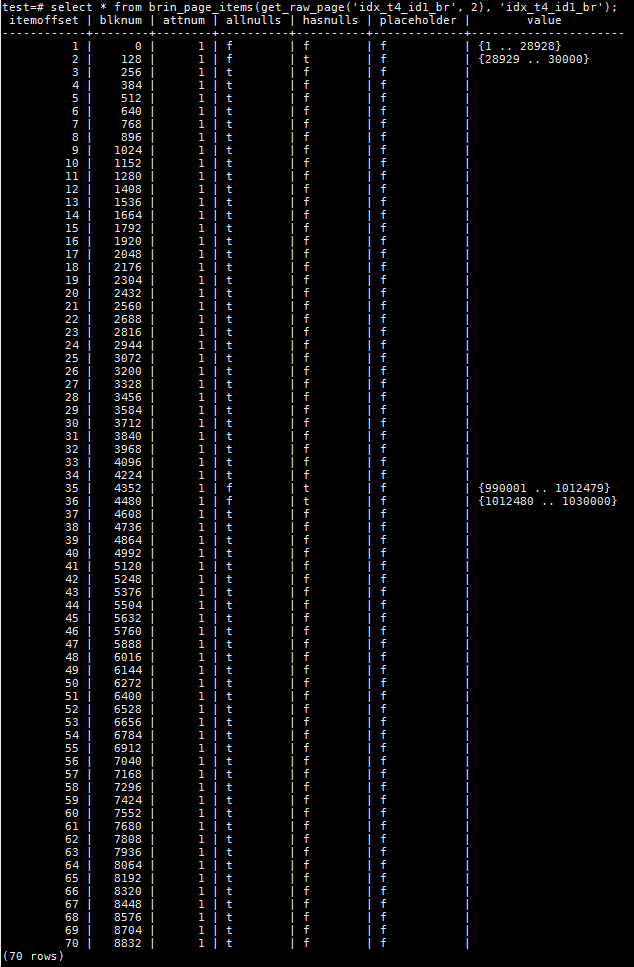
在这种情况下,当我们想要找出所有id1字段为非空的行的个数会发生什么?PG会扫描所有的heap page吗?来看下面的查询:
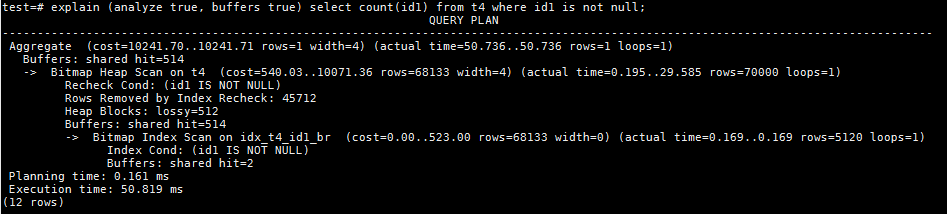

从执行结果可以看出,PG的执行器利用了BRIN索引条目上的allnulls和hasnulls信息,过滤掉了大部分无需扫描的heap page。
- 在t4总共8850个heap page中,只扫描了512个heap page,对应了4个BRIN索引条目;
- 总扫描的buffers是514,这是因为扫描BRIN索引需要2个buffer的读取;
- 如果想要访问id1字段为非空的数据,只需访问allnulls不是t的heap page范围。从前面分析的BRIN索引条目上得知,只有4个索引条目满足次条件,对应的heap page恰好是512个;
- 本例中主要通过索引条目上allnulls的值,省却了大量不必要的heap page扫描,提升了查询性能;
来看一下正好相反的例子。在本例中,我们将id1完全为空的值更新为非空;而将原先为非空的值更新为空。

可以想象到,更新后,id1字段绝大部分都为非空值,而只有少数为空值。来看一下更新后的BRIN索引条目。
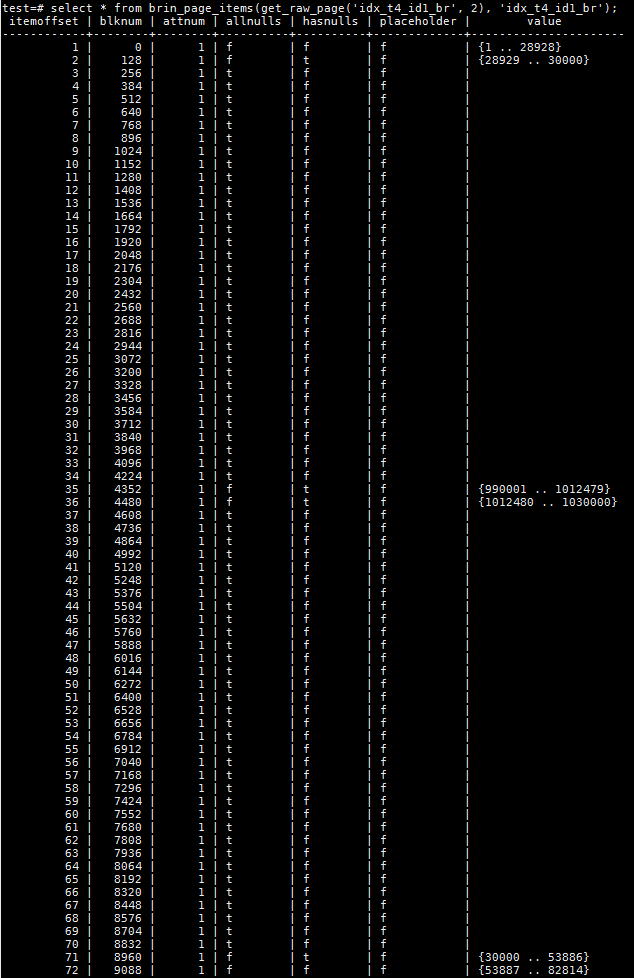
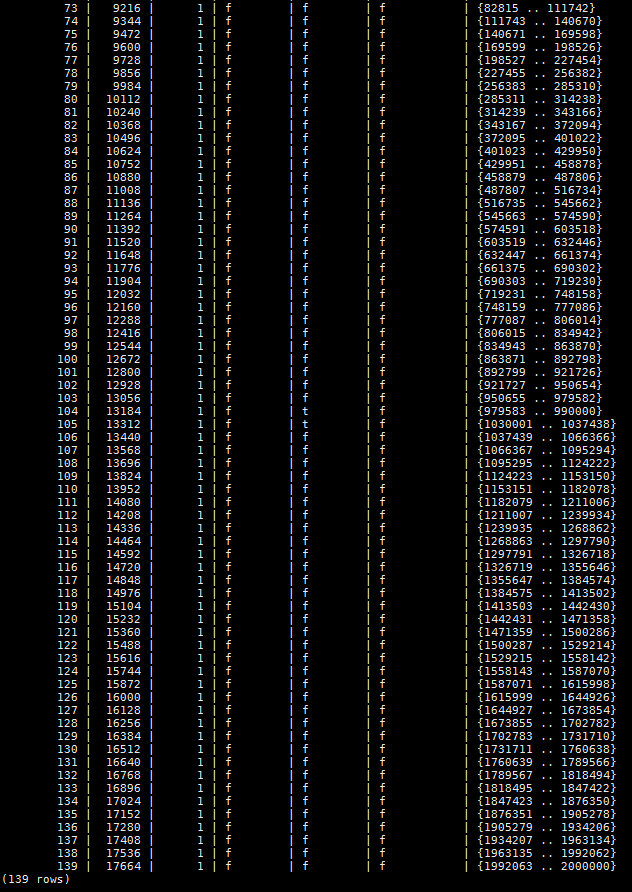
索引条目数从70增加到了139,这是因为PG的MVCC特性导致的,更新后最初的数据行还在,heap page也没有释放。即使手工做了表的vacuum操作也是一样,只是更新了visibility map。由于PG的索引中并不包含数据行的visibility信息,所以对应heap page的索引条目也都存在。更新后的数据会占用新的heap page,并会产生新的索引条目。
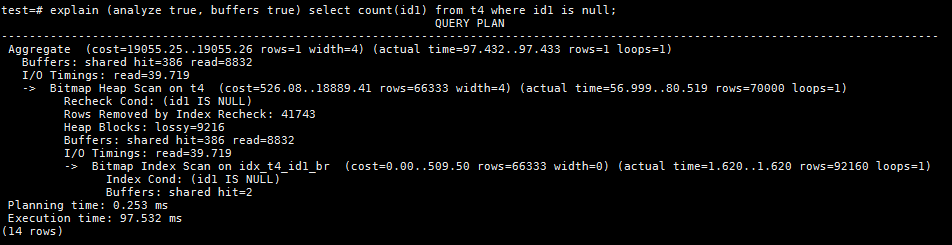
也因为索引条目的新增,旧的条目以及对应的heap page还在,BRIN索引对于本次查询性能的提升并不十分明显。我们来具体分析一下:
- 需访问总的buffer数量达到了9218,其中BRIN索引自身占用2个,需要访问的heap page达到9216个;
- 由于本例和之前的正好相反,需要找到所有id1字段为空的行的数量。对于BRIN索引条目来讲,只要allnulls和hasnulls任何一个为t就需要扫描对应的heap page;
- 对于更新前的MVCC数据,只有blknum=0不满足这个条件,所以可以无需扫描;
- 对于更新后的visible数据,只有blknum为8960,13184和13312满足条件,需要扫描对应的heap page;
- 所以需要扫描的heap page总数为((70-1)+3)*128=9216;
- 虽然对于visible的数据,BRIN过滤掉了绝大部分不必要的heap page,但由于PG的MVCC特性,整体性能提升没有在之前的一个例子中如此明显;
我们再来看一下对表进行vacuum full操作以及reindex之后的查询效果。

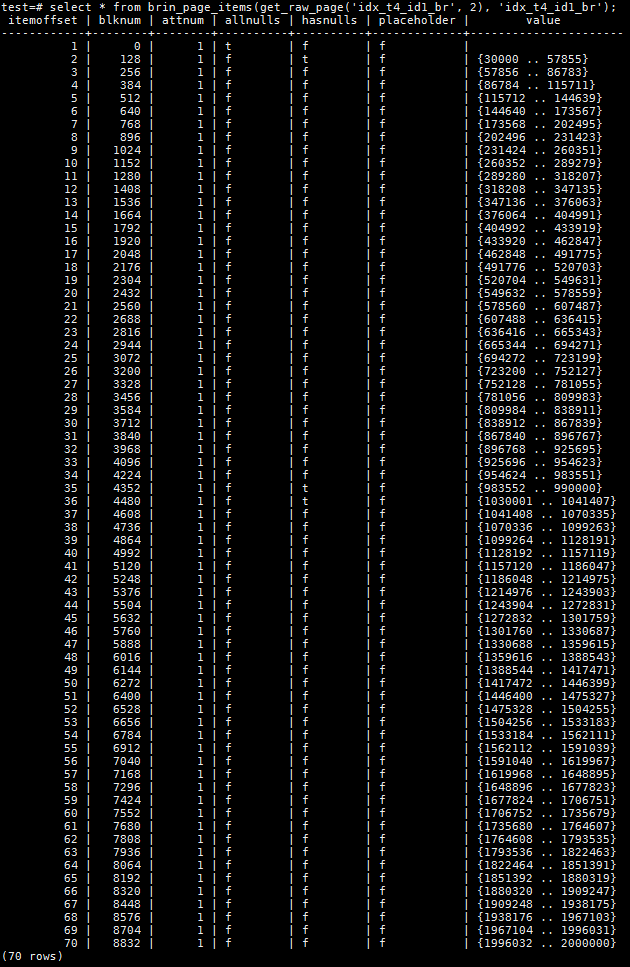
vacuum full操作相当于重建t4表,之前的dead tuple全部删除,并且占用的heap page也得以全部释放。重建后的idx_t4_id1_br索引也只包含了更新后数据对应的索引条目,看上去和案例一是相似的。
再来执行一遍统计id1字段为空的行数的查询:
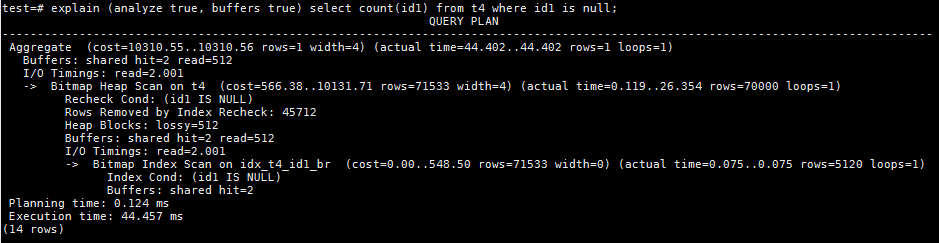
- 总的buffers回调到了514,其中2个是BRIN索引自身的扫描,512是对于t4中heap page的扫描;
- 前面提到,为了找出所有id1字段为空的行,只要索引条目中allnulls或者hasnulls任何一个为t就需要扫描对应的heap page。而blknum是0,128,4352,4480都满足这个条件,4个条目覆盖的heap page数量为512;
- 其他的条目皆为allnulls=f并且hasnulls=f,说明在这些heap pages中id1字段的值全部都是非空,不用做无谓的扫描;
- 通过BRIN索引条目上的allnulls和hasnulls信息,查询性能得到极大的提升;
总结:
- 本文分析讨论了对于查询条件中涉及NULL值在使用BRIN索引时能够带来的性能提升。BRIN索引条目中的allnulls和hasnulls信息可以帮助PG执行器过滤掉不必要的heap page扫描,从而带来查询性能的提升;
- 由于PG数据库的MVCC特性,在表出现bloat的情况下,同时BRIN索引中也包含了很多无用的索引条目,实际中带来的性能提升可能不如预期明显;
- 但这同时也告诉我们,需要定期对表进行维护操作,将无用的数据进行清理,以使得数据库性能保持在一个稳定的水平;

https://www.tiancebbs.cn/ershouwang/469760.html https://su.tiancebbs.cn/hjzl/462228.html https://zulin.tiancebbs.cn/sh/4414.html https://taicang.tiancebbs.cn/hjzl/458303.html https://bj.tiancebbs.cn/qths/459735.html https://zulin.tiancebbs.cn/sh/3638.html https://zulin.tiancebbs.cn/sh/3367.html https://zulin.tiancebbs.cn/sh/3458.html https://www.tiancebbs.cn/ershoufang/472733.html https://www.tiancebbs.cn/ershoufang/473862.html https://zulin.tiancebbs.cn/sh/552.html https://aihuishou.tiancebbs.cn/sh/4444.html https://zulin.tiancebbs.cn/sh/4687.html https://www.tiancebbs.cn/fabu/1989.html https://sdjn.tiancebbs.cn/qths/473532.html https://aihuishou.tiancebbs.cn/sh/1985.html https://su.tiancebbs.cn/qths/454887.html
好听伤感的网名:https://www.nanss.com/mingcheng/1389.html 仙气撩人的情侣名:https://www.nanss.com/mingcheng/1193.html 网名男生简单气质:https://www.nanss.com/mingcheng/532.html 好网名:https://www.nanss.com/mingcheng/822.html 英文qq网名:https://www.nanss.com/mingcheng/1366.html 好网名大全:https://www.nanss.com/mingcheng/915.html 赞美长城的句子:https://www.nanss.com/xuexi/1037.html 5个字的网名:https://www.nanss.com/mingcheng/1203.html 时间名言:https://www.nanss.com/xuexi/1127.html 个签短句干净治愈:https://www.nanss.com/yulu/563.html 篮球队名:https://www.nanss.com/mingcheng/995.html 懒羊羊语录:https://www.nanss.com/yulu/771.html 高姿态网名:https://www.nanss.com/mingcheng/1420.html 励志的短句:https://www.nanss.com/xuexi/1115.html 早会小游戏:https://www.nanss.com/gongzuo/935.html 夸人的词语:https://www.nanss.com/xuexi/524.html 描写春天阳光的句子:https://www.nanss.com/yulu/1061.html 药店取名:https://www.nanss.com/shenghuo/1131.html 春节活动方案:https://www.nanss.com/gongzuo/1141.html 一次说走就走的旅行优美句子:https://www.nanss.com/wenan/1276.html 吃年夜饭朋友圈配文:https://www.nanss.com/wenan/1021.html 升旗手介绍:https://www.nanss.com/xuexi/781.html 吃鸡游戏名字:https://www.nanss.com/mingcheng/833.html 电梯安全管理制度:https://www.nanss.com/gongzuo/1349.html 关于人生的网名:https://www.nanss.com/mingcheng/1169.html 激励孩子努力上进的话:https://www.nanss.com/yulu/801.html 霸气女生网名:https://www.nanss.com/mingcheng/980.html 英文情侣网名:https://www.nanss.com/mingcheng/1180.html 很酷的游戏名:https://www.nanss.com/mingcheng/1440.html 吃鸡昵称:https://www.nanss.com/mingcheng/531.html