想挑战AlphaGO吗?先和PostgreSQL玩一玩?? PostgreSQL与人工智能(AI)
作者: digoal
日期: 2017-01-08
标签: PostgreSQL,AI,人工智能,神经网络,机器学习,MADlib,Greenplum, 物联网,IoT,pivotalR,R
背景
想必很多朋友这几天被铺天盖地的AI战胜60位围棋高手的新闻,我们不得不承认,人工智能真的越来越强了。
http://wallstreetcn.com/node/283152
1月4日晚,随着古力认输,Master对人类顶尖高手的战绩停留在60胜0负1和,而令人尴尬的是这唯一一场和棋还是因为棋手掉线系统自动判和,并不是棋盘上的局势真的势均力敌了。包括聂卫平、柯洁、朴廷桓、井山裕太在内的数十位中日韩围棋高手,在30秒一手的快棋对决中落败。Master(最新版AlphaGo)网测以60战全胜的战绩收场!
在横扫中日韩顶尖棋手,豪取47连胜之后,昨晚神秘的“Master”再战世界冠军棋手朴廷桓,元晟溱,和中国第一人柯洁。随着柯洁黯然投子,Master的连胜纪录已扩大至50盘,难逢敌手。
今天早些时候,Master挑战人类顶尖高手第54局,中国棋圣、64岁的聂卫平出战。《新闻晨报》报道,本局“Master”特意把比赛用时调整为每方1分钟一手,以示对聂卫平的尊敬,最终执白的聂卫平以7目半的劣势落败。神秘AI围棋Master战胜棋圣聂卫平,54连胜。
人工智能知识背景
内容请参考: http://mp.weixin.qq.com/s/Chln4htaCq1rQWTpPgFYZg
参考以上文章萃取后的内容
大概的思想就是通过模仿生物神经网络的学习和训练方法,让计算掌握学习能力。 生物神经网络的学习过程是这样的,首先我们天生就有五官,能听到声音、看见世界、闻到气味、尝到酸甜苦辣、触摸到一切。
五官是神经网络的输入之一,而另一方面,我们的长辈会教我们东西,比如你告诉小孩这是香蕉,小孩的神经会根据看到的形状、颜色等特征,以及你告诉他的(事实)做一个碰撞,调整连接这两个点之间的信号强弱,形成固定的模式,学习成功。
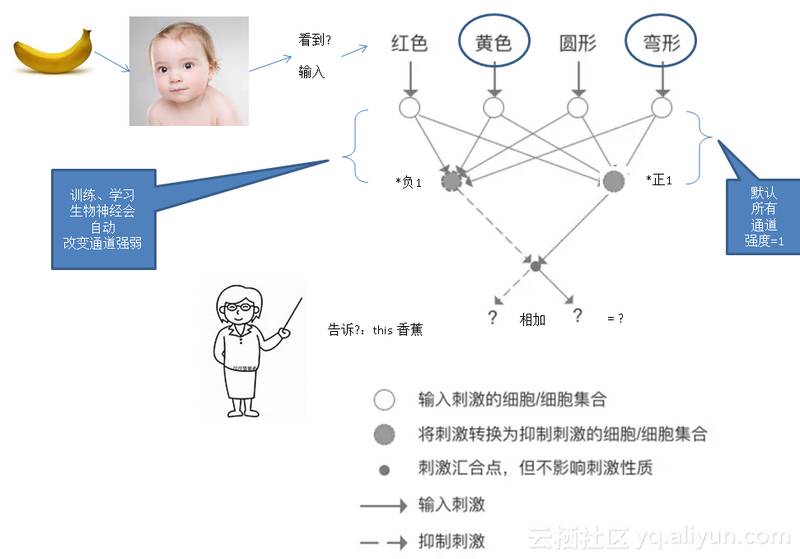
人工神经网络和生物神经网络类似,也需要训练,从而修正通道的信号强弱,掌握知识(判断能力)。

比如我们有一批水果的照片,并且人工将这些照片设置属性,存入数据库大概是这样的。
表1
| 水果图片 | 水果名称 | 水果唯一编号 |
|---|---|---|
| 图片1 | 香蕉 | 2 |
| 图片2 | 香蕉 | 2 |
| 图片3 | 香蕉 | 2 |
| 图片4 | 苹果 | -2 |
| 图片5 | 苹果 | -2 |
| 图片6 | 苹果 | -2 |
因为图片是数字化的,计算机可以读取(识别)图片的特征(比如每个像素的三原色等信息),同时第三个字段是水果的唯一编号,也就是说不通的香蕉图片,它们的编号都是一样的。
1. 图片就和小宝宝眼睛看到的东西一样。
2. 而水果编号就像大人教小宝宝的。
从而形成了与生物神经网络类似的训练模式,通过这样的方式,来调整两个输入点之间通道的强弱,适配唯一编号,就达到了人工神经网络的学习过程。
训练完成后,计算机就可以从输入(图片),就能识别它是什么(通过输入与不同通道相乘,在进行正负反馈相加得到结果),结果与已有的水果唯一编号对比,即可知道它是什么?
训练过程有两个输入(图片、水果唯一编号),而处理过程是一个输入(图片),一个输出(计算得到的值,与水果编号进行比较从而知道它是什么)。
上面介绍了最为简单的人工神经网络,那么它与机器学习和人工智能的关系是什么?
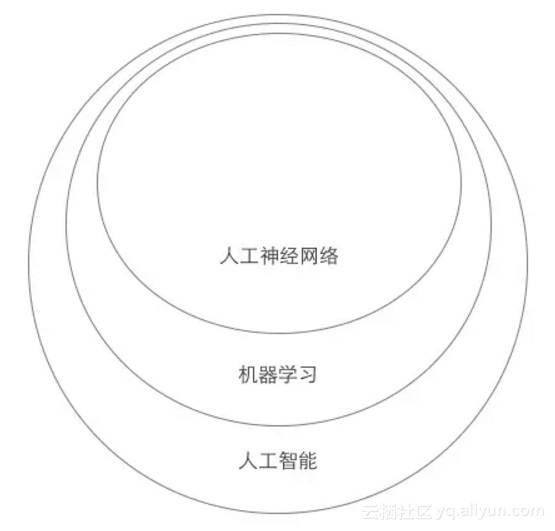
人工神经网络是机器学习的一种技术,有关人工神经网络的我们了解了,那么不是人工神经网络的机器学习是什么呢?大数据这个词大家都不陌生,大数据技术依赖的是数据中的数据关系,通过大数据训练的算法中很多就是机器学习中不是人工神经网络的部分,比如根据你购物的时候购买特定商品的频率推送相应的广告。
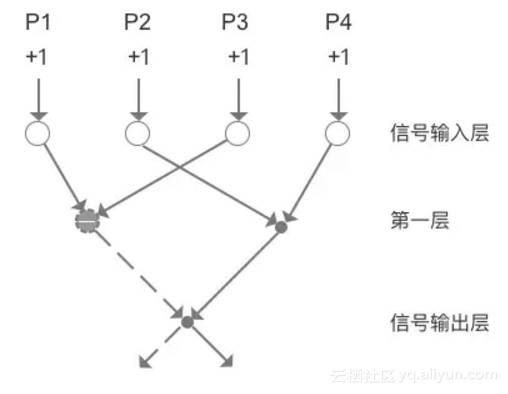
除了人工神经网络,深度学习也是经常被提起的名词,人工神经网络与深度学习又是什么关系?我们首先要对人工神经网络有一个粗浅的了解,如下图。
在识别苹果和香蕉的例子中,我们构建的其实是趋近于两层的单层神经网络,甚至形成了部分侧向抑制的能力,如果四个输入信号都被刺激,那么最终的刺激为0。
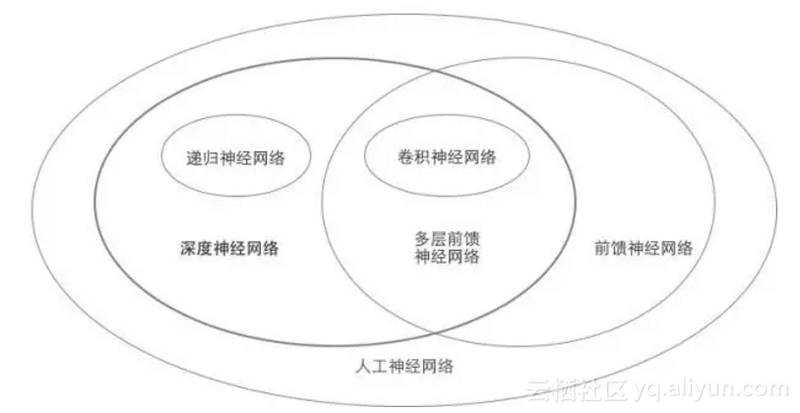
人工神经网络有一个非常重要的部分,深度神经网络,是指含有多个隐层的神经网络,如下图。
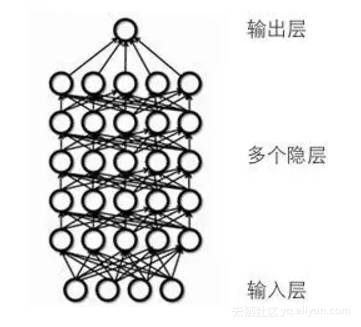
依赖深度神经网络的机器学习被称为深度学习。深度神经网络本身有几个重要的类型:递归神经网络,卷积神经网络,前馈神经网络,这几种神经网络有不同的应用场景。深度学习又可以分为无监督学习和监督学习,如下图。
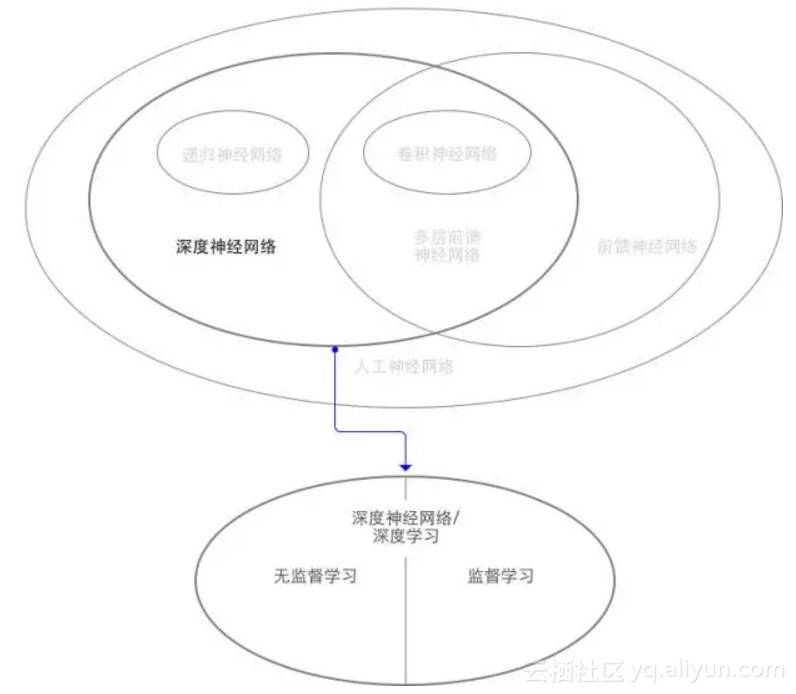
我们知道神经网络是要通过数据来训练(学习)的,所以如果先要通过具有相关性的标签化的数据训练网络,那么这部分数据就是通过人的监督来筛选的,比如我们构建的简单的识别水果的神经网络,就是先把苹果和香蕉的数据准备好,再输入进去,这就是监督学习。假如不去告诉人工神经网络什么是对,什么是错,什么是苹果,什么是香蕉,而是通过神经网络自己进行聚类学习,
除了识别出一般的香蕉苹果,甚至发现特殊品种,这种就是无监督学习,或者叫非监督学习。
从人工智能到无监督学习,整体的概念联系图就是这样的。
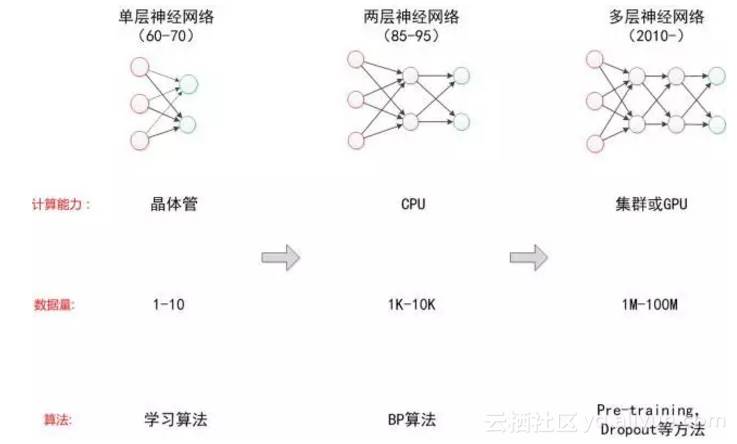
人工神经网络的发展并非一帆风顺,从最早的单层神经网络到现在的多层神经网络经历了七十多年的研究,如下是人工神经网络的发展简史。
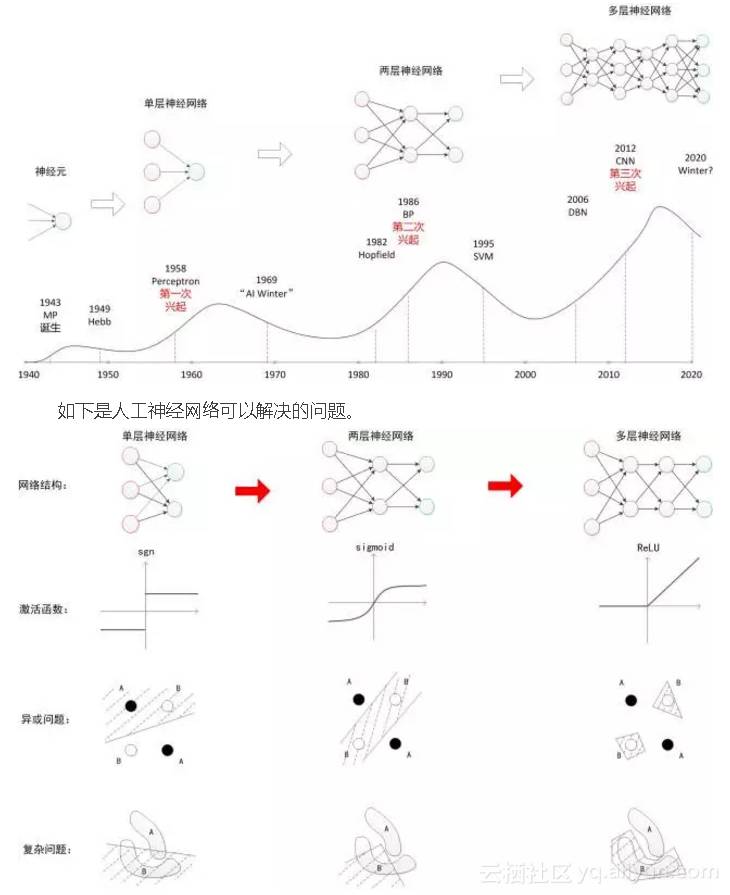
如下是人工神经网络所使用的算法。
深度神经网络的两个应用领域
1. CNN—图像识别(参考 用CNN来识别鸟or飞机的图像 )
2. RNN-语音/语义识别 (参考 循环神经网络RNN打开手册 )
3. CNN与RNN的融合
机器从获取到的数据集合,通过训练,达到一定程度后,智力超过人类也属于正常现象。甚至可能未来也能像人类一样进化,冥想。
数据与建模
我们知道深度学习所采用的技术关键点之一是通过数据训练网络,那么究竟需要多少数据?在2016年初,互联网出现了一个引爆性的新闻,谷歌收购的Deep Mind公司通过以CNN为基础的神经网络形成的人工智能Alphago在围棋上击败了李世石,在这个网络开始训练的时候已经相当于下了三千万的棋谱,而与李世石下棋的时候这个数据达到一亿,当然人类完成一局要一小时,而Alphago只要一秒。
Alphago的示例是不是说一定要海量的数据才能训练神经网络?这样对于没有大量计算资源(分布式的Alphago调用了1202个CPU和176个GPU),以及庞大数据库(3000万棋谱)的小公司和个人是不是就意味着无法使用人工智能?
有另一家公司在Deep Mind公司被收购前与其齐名,Vicarious,该公司的特点是大量借鉴神经科学家和脑科学家的科研成果进入人工智能领域,在其科研人员中有20%来自相关领域。我们在上文中提到了神经细胞的侧向抑制作用对轮廓识别和马太效应的影响,那么如果把这种能力模拟成神经网络中的某些函数会是什么结果?
Vicarious在NIPS、神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上发表了这样一篇论文,利用了脑科学上非常成熟的成果:人类的神经系统系统普遍存在的侧向抑制的现象,在他们在模型上实现了侧向约束(Lateral Constraints),如下图。
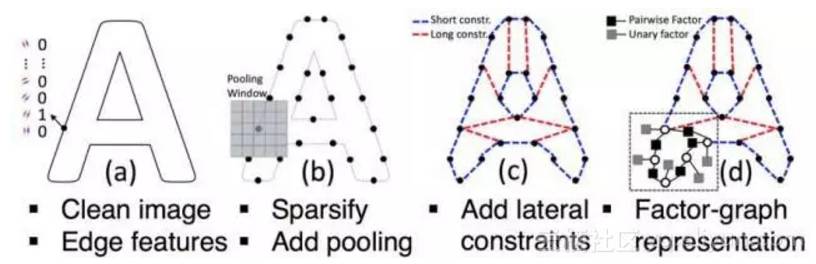
注意右下角的放大小图中的灰色方块一元因子(Unary factor),这是与水平细胞相似的关键。在字母验证码识别这个具体问题上,Vicarious基于生成型形状模型的系统能够只用1406张图片作为训练集,就超越了利用深度学习的800万图片达到的效果。
所以当模型足够优化的时候可以大大减少对数据的需求量,而借鉴神经科学的发展无疑是一个有效的途径。
与PostgreSQL数据库下一场国际象棋
虽然这个例子与AI无关,只是简单的自定义规则的棋类游戏。但是它反映的是PostgreSQL的开放性,以及扩展能力。 PostgreSQL的用户有点疯狂,看看他们怎么让PostgreSQL和你玩国际象棋吧。
部署
wget http://api.pgxn.org/dist/pg2podg/0.1.3/pg2podg-0.1.3.zip wget http://api.pgxn.org/dist/pgchess/0.1.7/pgchess-0.1.7.zip unzip pg2podg-0.1.3.zip unzip pgchess-0.1.7.zip cd pg2podg-0.1.3 make clean; make; make install cd ../pgchess-0.1.7 make clean; make; make install
部署结束
-rw-r--r-- 1 digoal users 94 Jan 6 10:05 pg2podg.control -rw-r--r-- 1 digoal users 21K Jan 6 10:05 pg2podg--0.1.3.sql -rw-r--r-- 1 digoal users 131 Jan 6 10:05 pgchess.control -rw-r--r-- 1 digoal users 14K Jan 6 10:05 pgchess--0.1.7.sql -rwxr-xr-x 1 digoal users 22K Jan 6 10:05 chess.so
将游戏加载到PostgreSQL数据库中
psql -h 127.0.0.1 psql (9.4.5) Type "help" for help. postgres=# create extension pgchess; CREATE EXTENSION postgres=# create extension pg2podg; CREATE EXTENSION
新增了3个数据类型
postgres=# \dT
List of data types
Schema | Name | Description
--------+----------+-----------------------------------------------------------------------
public | game | "moves" is encoded via the %% operators, which throughout this file +
| | represent a compact textual encoding of a game or a move. +
| | +
| | "board" could be computed from "moves", but only for standard games +
| | (e.g. not for chess problems). Also, remembering "board" is efficient+
| | and simpler. +
| | +
| | The first 64 characters of "board" represent the chessgame locations;+
| | the next four characters encode castling information, and the last +
| | character is the piece captured in the last move (if any).
public | location |
public | move |
(3 rows)
玩法参考
http://api.pgxn.org/src/pgchess/pgchess-0.1.7/doc/pgchess-QUICKSTART.md
游戏在以下目录
pgchess-0.1.7/test/sql/play -rw-r--r-- 1 digoal users 160 Oct 19 2012 Human_v_PG.sql -rw-r--r-- 1 digoal users 148 Oct 19 2012 new-game.sql -rw-r--r-- 1 digoal users 160 Oct 19 2012 PG_v_Human.sql -rw-r--r-- 1 digoal users 160 Oct 19 2012 PG_v_PG.sql -rw-r--r-- 1 digoal users 242 Oct 19 2012 reset-stats.sql -rw-r--r-- 1 digoal users 933 Oct 19 2012 _.sql -rw-r--r-- 1 digoal users 854 Oct 19 2012 view-stats.sql
玩法如下:
Step 1
------
Load a default game in the chessboard:
\i /home/dege.zzz/pgchess-0.1.7/test/sql/play/new-game.sql
Step 2
------
View the game in FEN notation
gianni=# select %% game from status;
?column?
----------------------------------------------------------
rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1
(1 row)
Step 2a (optional)
------------------
If you are using a VT100-compatible terminal, you can use an enhanced
graphical display.
First make sure that the background is lighter than the foreground (e.g.
black on white); then issue
gianni=# \pset format unaligned
Output format is unaligned.
and check that it is working by displaying the current game:
gianni=# select # game from status;

Step 3
------
Now you can start a CPU v CPU game:
\i play/PG_v_PG.sql
you can interrupt the game with CTRL-C.
Since each half-move is executed in a separate transaction, the game will be left in the state
corresponding to the last completed move.
由于我的终端问题,无法正确的显示图标
请使用9.4来把玩,9.5以后这个接口有变,需要修改以上两个游戏模块的代码。
extern ArrayIterator array_create_iterator(ArrayType *arr, int slice_ndim);
一个小小的下棋插件,主要体现的是PostgreSQL的开放性,不要把它当成单纯的数据库,它是一个真正的面向对象数据库。 可以实现很多有趣的特性,能帮助业务解决很多的问题,比如本文末尾有很有很实用的例子,已经帮到了很多用户。
Greenplum与PostgreSQL 的机器学习库MADlib
数据库中的人工神经网络体现: http://www.infoq.com/cn/articles/in-database-analytics-sdg-arithmetic
PS: 这篇文档中有一些描述的点并不正确(比如UDFA实际上是支持并行的)。
把机器学习库内置到database中(通过database的UDF)有许多优点,执行机器学习算法时只需要编写相应的SQL语句就可以了,同时database本身作为分析的数据源,使用非常方便,大大降低了机器学习的应用门槛。
在数据库中,如何编写聚合,在Greenplum如何编写两阶段聚合:
《hll插件在Greenplum中的使用 以及 分布式聚合函数优化思路》
《performance tuning about multi-rows query aggregated to single-row query》
《PostgreSQL aggregate function customize》
实际上MADlib库中包含了大量的机器学习算法,可以通过已有的数据集合进行训练(比如前面提到的苹果、香蕉等水果的照片)。(类似前面提到的生物神经网络的学习过程)那么madlib是什么样的呢?
一张图读懂madlib: http://blog.163.com/digoal@126/blog/static/163877040201510119148173
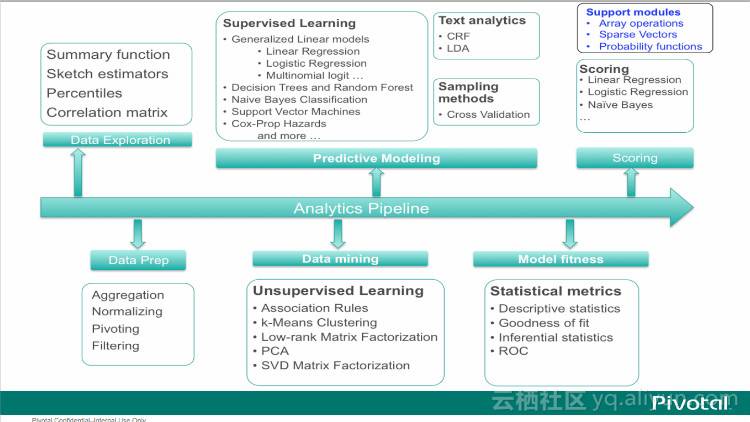
回归分析,决策树,随机森林,贝叶斯分类,向量机,风险模型,KMEAN聚集,文本挖掘,。。。等。
一个线性回归的例子,对应上图 supervised learning -> generalized linear models -> linear regression

如果你是R的数据科学家,并且不习惯使用SQL的话,使用pivotalR的R包就可以了,左边是R的写法。右边对应的是SQL。
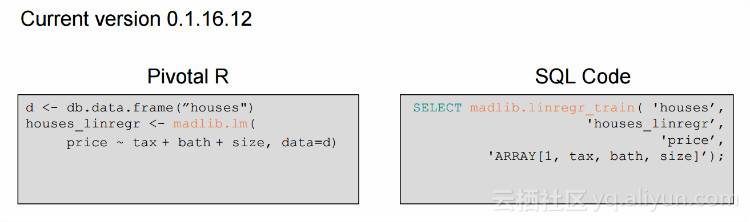
话说如果要预测每个时间点的11.11销售额,可以用到它了。PostgreSQL用户来搞数据挖掘有天然优势。
madlib的使用手册:http://doc.madlib.net/latest/index.html http://madlib.incubator.apache.org/docs/latest/group__grp__tsa.html
pivotalR使用手册: https://cran.r-project.org/web/packages/PivotalR/PivotalR.pdf
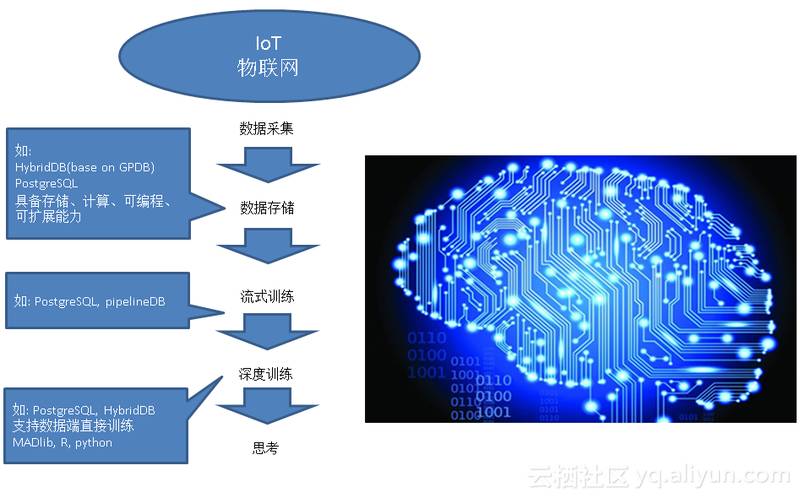
IoT、大数据与人工智能的结合
人工智能的基础是数据、学习算法。
1. 人的数据来自哪里?五官
2. 人工智能的数据来自哪里? IoT,万物产生的数字化数据
3. 人的数据存哪里?如何处理?大脑?
4. 人工智能的数据存哪里?如何处理?
为了提高数据传输的速度,数据和计算单元越近越好,否则不仅需要传输,还需要在计算端暂存,耗时耗力。
所以数据库本身具备计算能力是最好的,否则一次运算需要的数据在网络上传输花的时间可能是无法想象的。
有了菜谱,那么就开始找食材吧:
Greenplum, PostgreSQL, MADLib, R, pivotalR 是不错的食材,可以烧出什么样的菜呢?


http://jinqiang.ahtcbmw.cn/xjhm/ http://ruanwen.xztcxxw.cn/smxc/ https://taicheng.tiancebbs.cn/ https://xjhuayuan.tiancebbs.cn/ http://yz.cqtcxxw.cn/yzq/ http://huilong.sctcbmw.cn/yspx/ http://taiying.njtcbmw.cn/bnq/ http://bjtcxxw.cn/esmtc/ http://yz.cqtcxxw.cn/kfjz/ https://honglan.tiancebbs.cn/linzhi/ http://ly.shtcxxw.cn/zhengzhou/ http://jinqiang.ahtcbmw.cn/scls/ http://taiying.njtcbmw.cn/bjcp/ http://ouyu.hftcbmw.cn/hnsmx/ http://ruanwen.xztcxxw.cn/chuzhou/ http://taiying.njtcbmw.cn/sjpx/ https://bsqgongyeyuan.tiancebbs.cn/
摆地摊卖饰品技巧:https://www.nanss.com/wenti/3582.html 向英雄致敬的经典句子:https://www.nanss.com/yulu/3954.html 小故事大道理:https://www.nanss.com/yuedu/2894.html 一句佛语点透人生:https://www.nanss.com/yulu/3835.html 愿宝贝快乐成长的句子:https://www.nanss.com/wenan/3777.html 端午节活动方案:https://www.nanss.com/shenghuo/3102.html 关于exo的个性签名:https://www.nanss.com/wenan/4026.html 闻香识女人经典台词:https://www.nanss.com/shenghuo/3644.html 酷的名字:https://www.nanss.com/mingcheng/3946.html 劳动心得:https://www.nanss.com/xuexi/3048.html 日落黄昏的唯美句子:https://www.nanss.com/yulu/3593.html 科学家的名言:https://www.nanss.com/xuexi/3972.html 洋气点的网名:https://www.nanss.com/mingcheng/3980.html 毕业生自我总结:https://www.nanss.com/xuexi/3342.html 神奇的探险之旅作文:https://www.nanss.com/xuexi/3161.html 政审表填写内容模板:https://www.nanss.com/gongzuo/3473.html 事业越来越好的祝福语:https://www.nanss.com/gongzuo/3970.html 幼儿园教师总结:https://www.nanss.com/gongzuo/3415.html 一秒笑喷的段子:https://www.nanss.com/wenan/3767.html 我是小小讲解员作文:https://www.nanss.com/xuexi/3311.html 销售总结:https://www.nanss.com/gongzuo/3351.html 打工人语录:https://www.nanss.com/gongzuo/3798.html 兵马俑作文:https://www.nanss.com/xuexi/3321.html 给自己的照片配一句话:https://www.nanss.com/wenan/4005.html 读书笔记:https://www.nanss.com/xuexi/3324.html 祝老人一路走好的句子:https://www.nanss.com/yulu/4024.html 友谊长存:https://www.nanss.com/yulu/3541.html 翻过那座山作文600字:https://www.nanss.com/xuexi/3441.html 通知的格式及范文:https://www.nanss.com/gongzuo/3059.html 绩效考核方案:https://www.nanss.com/gongzuo/3177.html